[기계학습심화] 2. 선형 회귀 & 경사하강법
지난 글에서 기계학습의 개요를 정리하면서, 기계학습은 입력 데이터의 분포를 잘 설명하는 함수(모델)를 찾는 과정이라고 정리하였다.
이번 글에서는 가장 간단한 모델인 선형 회귀와 해당 모델을 학습시키는 경사 하강법에 대해서 정리해본다.
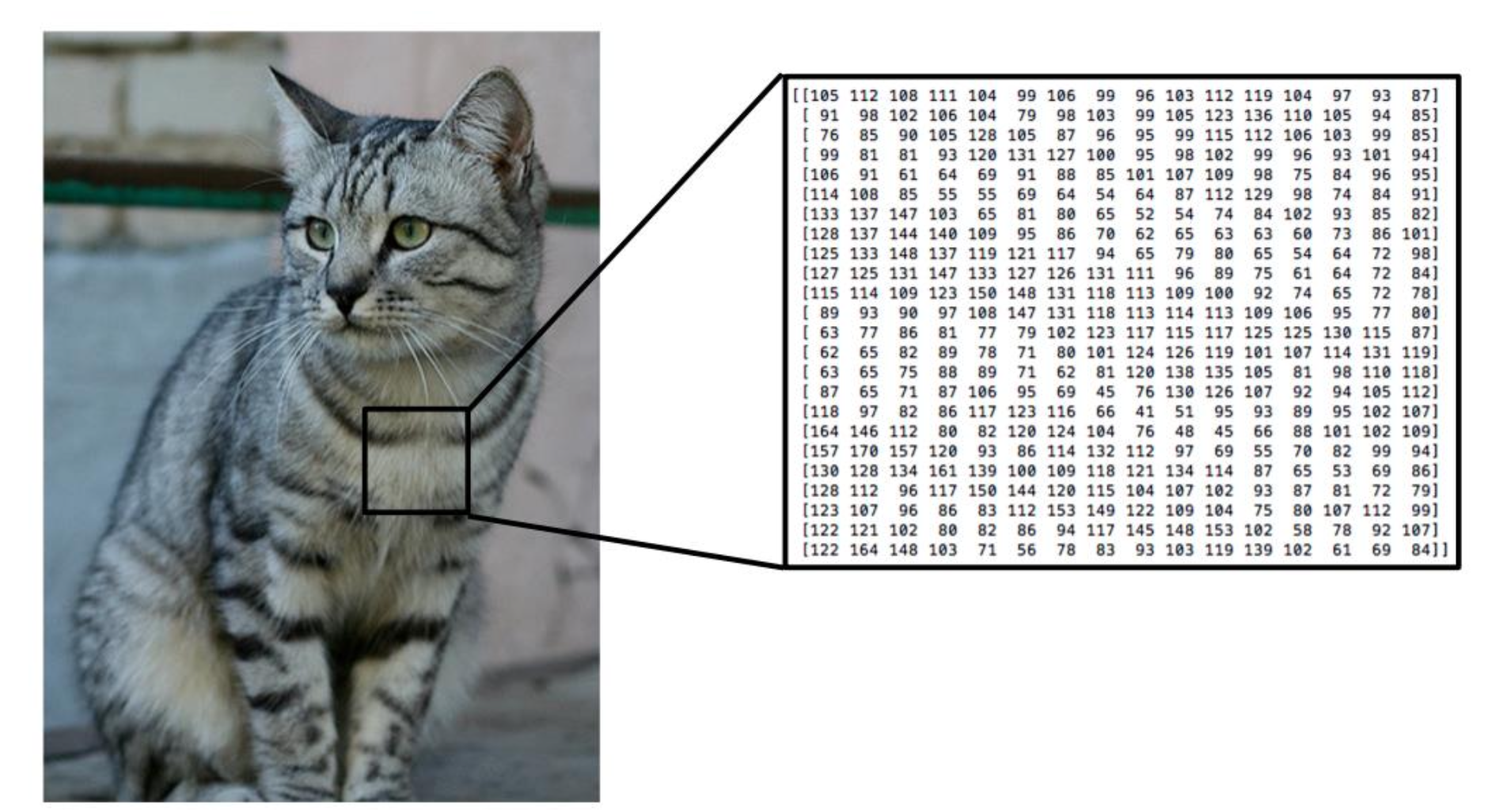
지난 글에서 본 것처럼 컴퓨터가 인식하는 '데이터'는 숫자의 묶음이다.
이미지의 경우에는 RGB 3개 숫자 데이터의 2차원 묶음 (따라서 결과적으로는 3차원 배열) 이다.
만약 이 이미지의 크기가 50 픽셀 x 50픽셀 이라면, 50 x 50 x 3 = 7500 개 숫자들의 배열이 된다.
그리고 이 숫자들을 7500 x 1 크기의 행렬로도 표현할 수 있다.
이 행렬은 수학적으로 7500차원 좌표계 위에 있는 하나의 점으로 생각할 수 있다.
또 다른 50픽셀 x 50픽셀 이미지들을 더 모은다면 이 이미지들도 모두 7500 x 1 벡터로 표현할 수 있고, 이들을 모두 7500차원 좌표계 위의 점으로 나타낼 수 있다.
이미지 뿐만 아니라, 소리도 높낮이 등을 활용하여 숫자의 형태로 표현할 수 있고, 텍스트도 간단하게는 아스키코드로 나타낼 수도 있다. (실제로는 이렇게 하면 성능이 안나와서 다른 방법으로 표현한다고 한다.)
결론적으로 이미지, 텍스트, 음성 등 머신러닝과 관련된 모든 데이터는 컴퓨터가 이해할 수 있는 숫자 형태로 변환한다는 것이 중요하다.
그리고 다시 기계학습의 '함수 찾기' 관점에서 보면, 어떤 숫자가 들어오고 어떤 숫자가 나올 때, 이 두 숫자를 매핑하는 함수를 찾는 것이 기계학습이다.
하지만 데이터가 있다고 해서 함수를 그냥 쌩으로 찾는 것은 불가능하다.
따라서 기본적인 함수의 형태를 미리 정의해줄 필요가 있다.
(다항 함수의 종류만 해도 1차함수, 2차함수, .. 로 해서 수많은 종류의 함수가 존재하는데, 어떤 종류의 함수를 사용할 지 스스로 알아내라고 하는 것은 사실 불가능하다.)
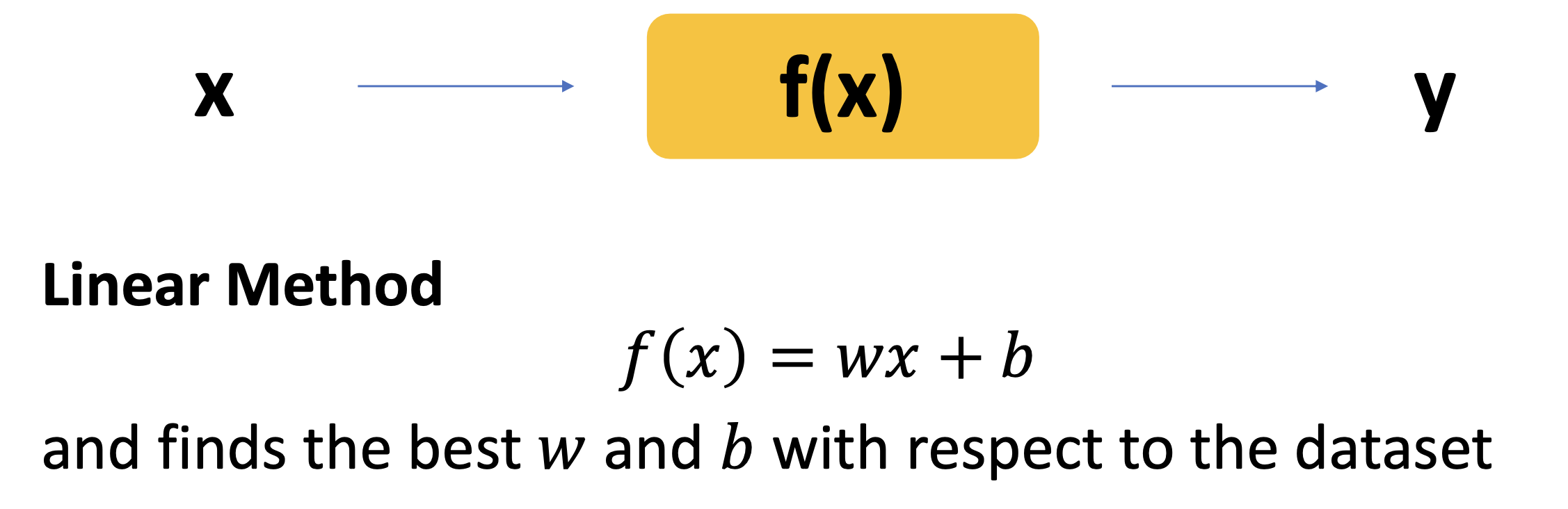
그래서 linear method 라고 하면 함수의 형태를 1차 함수의 형태로 정해서 wx + b 의 형태로 고정을 시켜두고, 주어진 데이터를 가장 잘 나타내는 함수를 (정확히는 미지수 w, b를) 찾는 것이다.
이제 주어진 문제는 함수를 찾는 것에서 w, b 라는 계수를 찾는 문제로 바뀌게 되었다.
그리고 이 문제는 함수를 찾는 것보다 매우 쉽다.
우선 linear method 의 경우 2개의 점만 있으면 w, b 를 결정할 수 있기 때문이다.
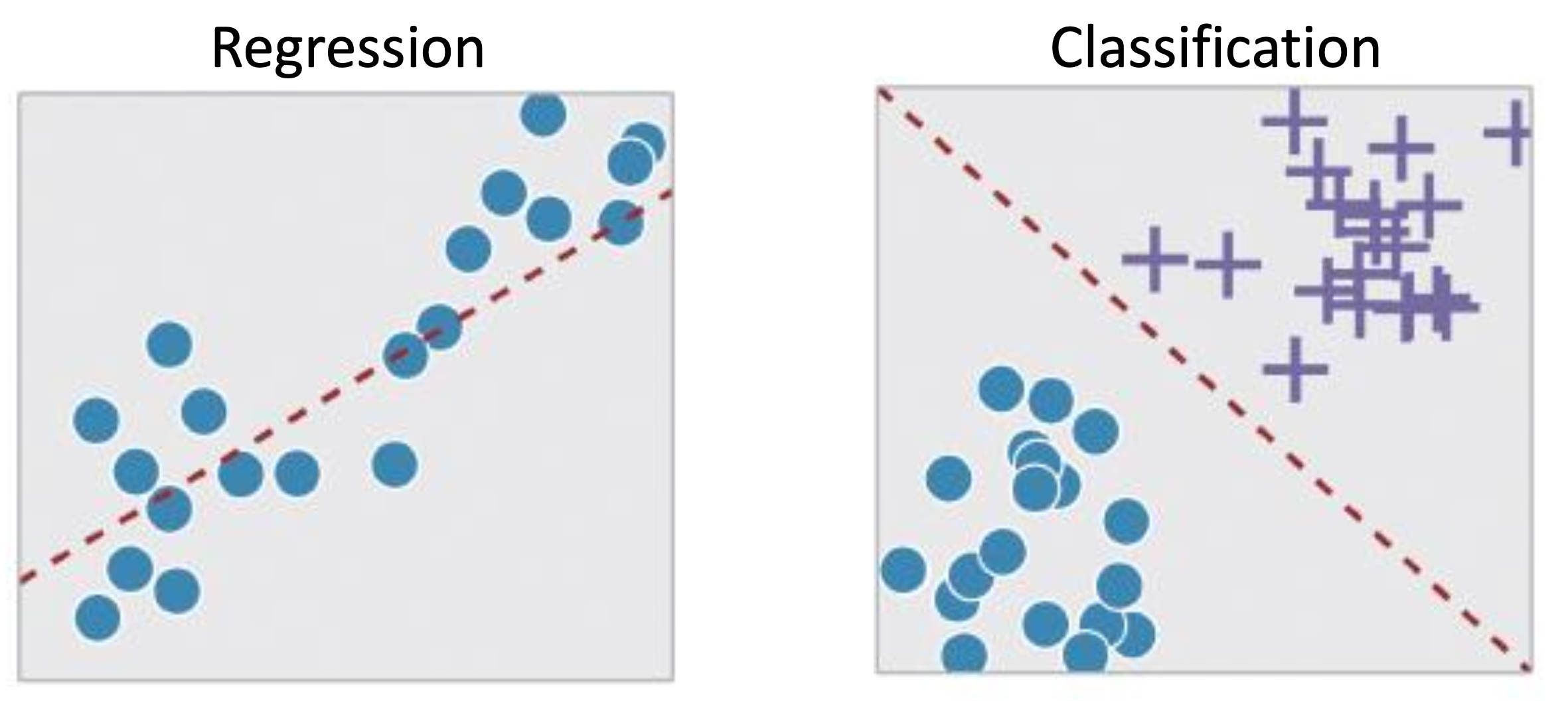
linear method 를 사용하는 지도 학습의 경우, 문제를 크게 regresion 문제와 classification 문제로 나눌 수 있다.
regresion (회귀) 문제의 경우, 주어진 데이터들의 분포를 잘 따라가는 선을 찾는 것이고, classification 문제는 주어진 데이터들을 잘 분류하는 기준선을 찾는 것이다.
이번 글에서는 선형 함수를 사용하는 회귀 문제, 선형 회귀와 선형 회귀 문제를 풀기 위한 함수를 구하는 방법인 경사하강법에 대해 정리해본다.
선형 회귀
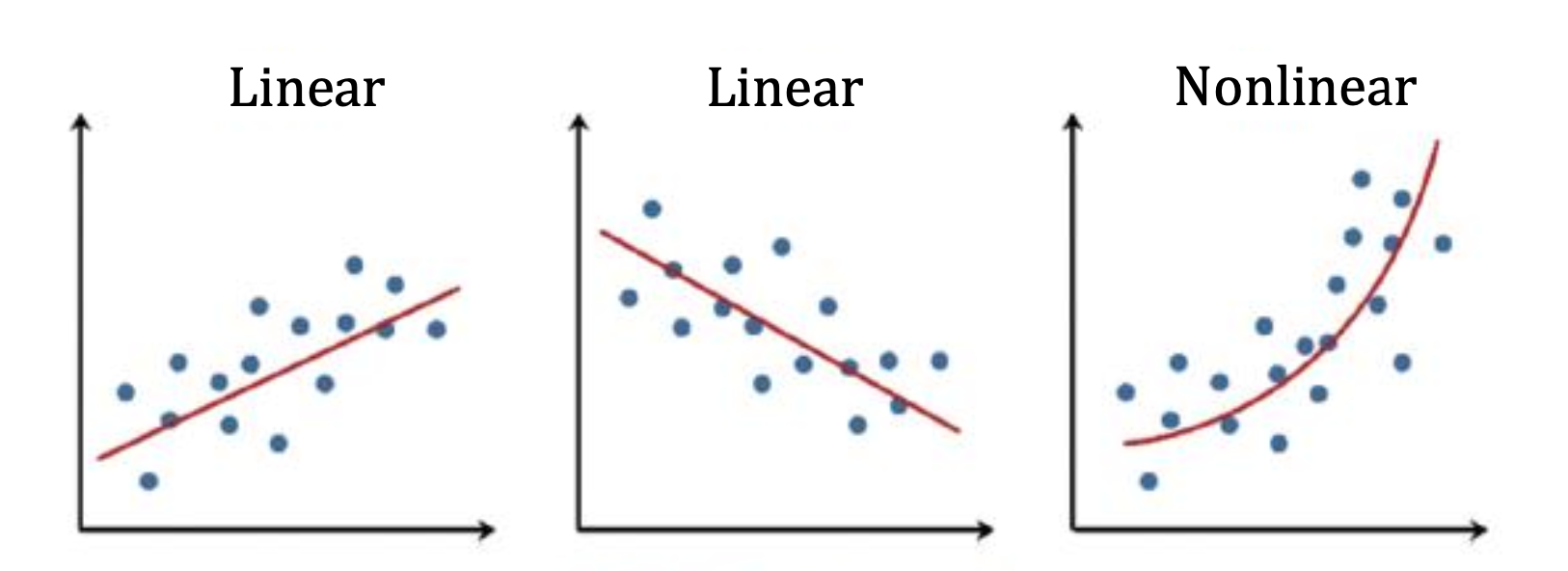
회귀는 주어진 데이터들의 분포를 잘 설명하는 함수(직선 or 곡선)를 찾는 것을 말한다.
주어지는 데이터의 입력도 1차원이고 출력도 1차원이면 위 그림과 같이 2차원 좌표평면에 점을 찍을 수 있다.
2차원 좌표 평면에서는 주어진 점들을 가장 잘 나타내는 직선을 찾는 것이 선형 회귀이다.
만약 입력이 2차원이고 출력이 1차원이면 그 점은 3차원 좌표계에 찍어야 할 것이다.
그 경우에는 해당 점들을 가장 잘 나타낼 '평면' 을 찾아야 하며, 이런 식으로 n차원 점들의 분포를 잘 나타내는 n-1 차원의 hyperplain 을 찾는 것이 '선형 회귀' 이다.
위 그림의 오른쪽 모습과 같이, 직선이 아닌 곡선을 찾는 경우도 있다.
이 경우는 '선형 회귀' 가 아니며, 이 글에서 다루는 범위를 벗어난다. (이런 경우에는 non-linear 모델이다.)
선형 회귀를 적용할 수 있는 대표적인 예시로는 키-몸무게 간 상관 관계, 학습 시간-성적 간 상관 관계, CPU 속도-실행 시간 간 상관관계 등이 있다.
위 예시들은 모두 절대적이지는 않지만 (키가 크다고 반드시 몸무게가 많이 나간다거나, 시간을 많이 붓는다고 무조건 성적이 높다거나) 대체로 그런 경향성이 있다고 보고 그 경향성을 직선으로 나타낼 수 있다.
이런 상황에서 선형회귀를 적용하면 효과적이다.
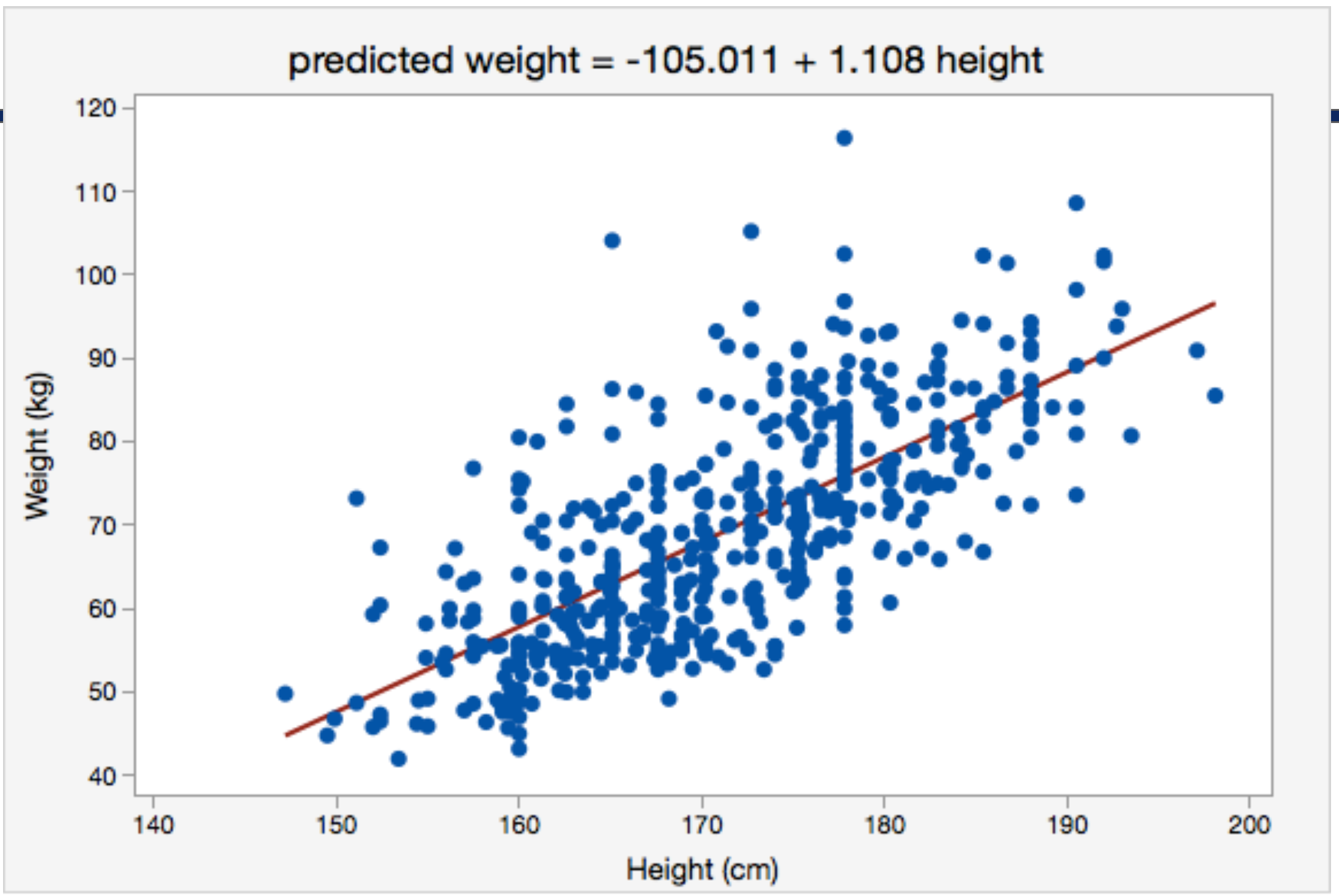
키와 몸무게 대한 데이터를 이렇게 2차원 좌표에 점을 찍었을 때, 빨간색 직선으로 그 경향성을 나타낼 수 있다.
그리고 이 직선을 이용하면 키가 주어졌을 때 몸무게를 예측하는 모델을 만들 수 있을 것이다.
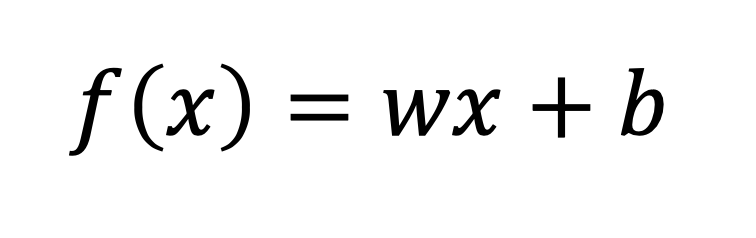
먼저 빨간색 직선을 찾는다는 것은 해당 직선식을 위와 같이 설정하고 기울기 w와 y절편 b를 찾겠다는 것과 같다.
선형회귀는 처음에 w, b 값을 랜덤으로 설정하고, 훈련용 데이터를 넣으면서 w, b 값을 조정하여 우리가 원하는 함수를 찾는다.
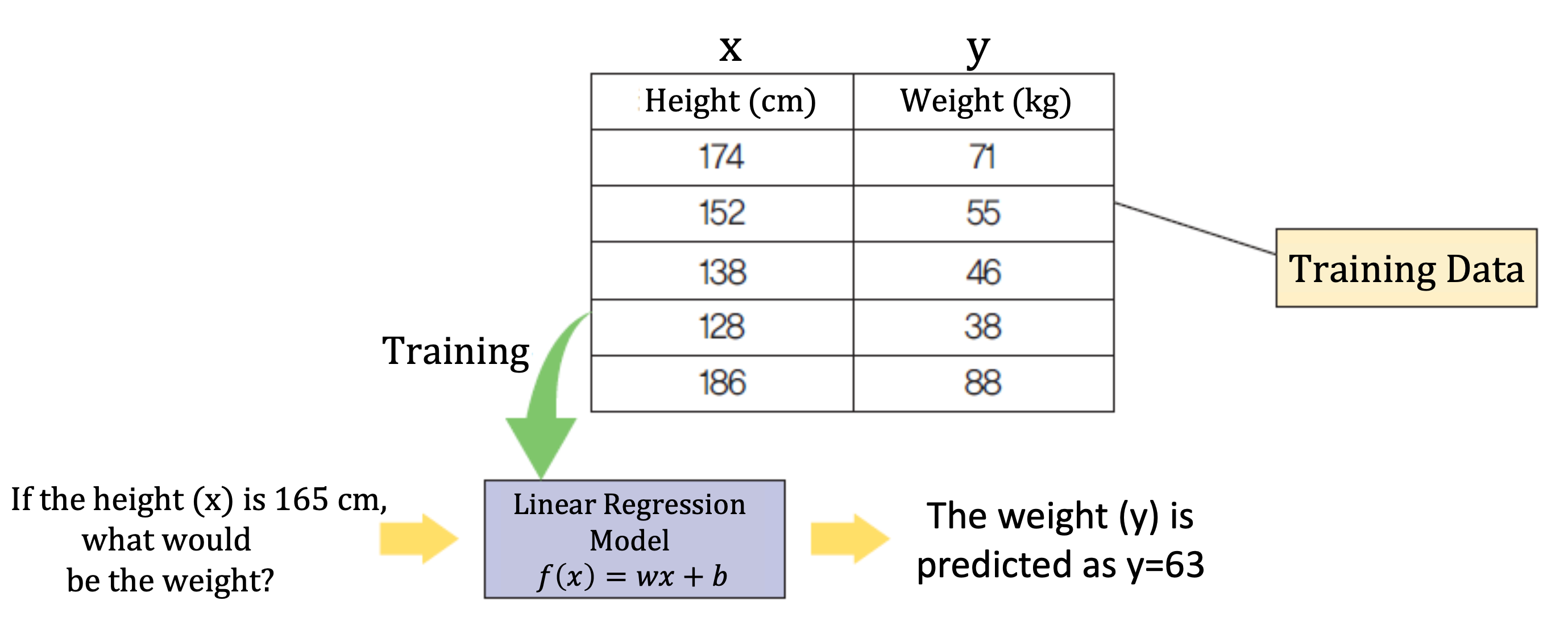
키가 주어졌을 때 몸무게를 예측하는 모델을 선형회귀를 통해 만든다고 하면, f(x) = wx + b 라는 함수의 형태를 정의하고, 랜덤값으로 w, b 를 지정한 뒤, 다양한 훈련용 데이터를 넣어 w, b 값을 찾는다.
그리고 그렇게 만든 모델에 165cm 라는 키를 넣어서 몸무게를 예측할 수 있다. (위 경우 63kg이 나왔다.)
그런데 모든 선형 함수가 1개의 변수로 구성되어있지는 않을 수 있다.
위에서 본 것처럼 7500차원의 이미지가 데이터로 들어올 수도 있다.
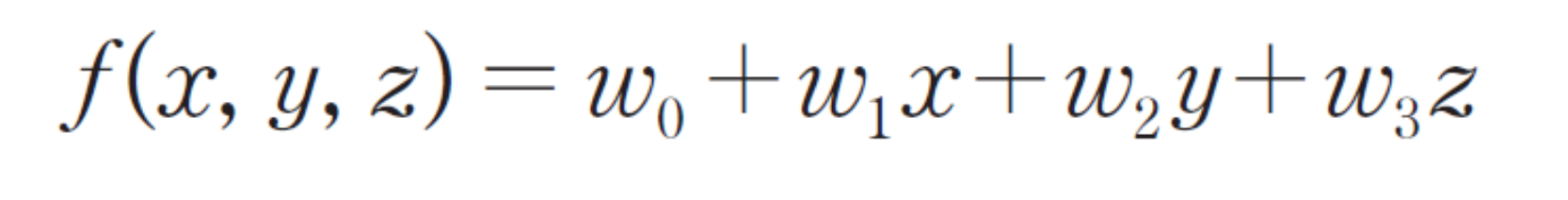
즉, 위와 같은 형태의 함수를 사용할 수도 있다.
따라서 이를 더 일반화된 형태로 표현할 필요가 있다.
그리고 행렬을 사용하면 위 식을 일반화하여 표현할 수 있다.
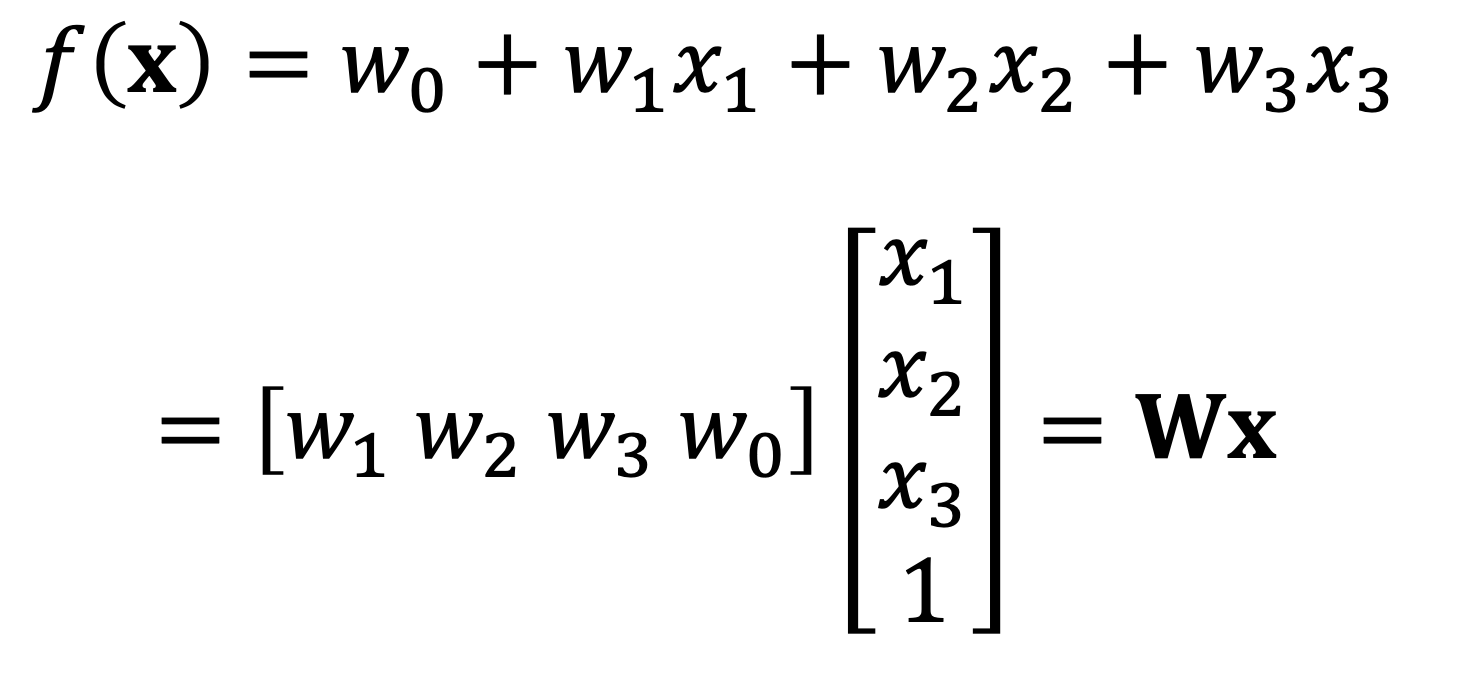
바로 이렇게 표현하면 된다.
입력 데이터의 차원이 늘어나면 그만큼 계수의 차원도 늘어나므로 모든 선형 회귀는 f(x) = Wx 의 형태로 나타낼 수 있다.
또한 위 예시는 출력의 결과가 1개의 숫자이지만, 출력도 역시 벡터 형태가 될 수 있다.
(참고1 - 상수항을 빼서 Wx + b 형태로 기술하기도 한다.)
(참고2 - 이텔릭체로 쓴 문자(x1, x2, ..)는 숫자 1개를 의미하고, 이텔릭체가 아닌 문자(Wx의 x)는 벡터를 의미한다.)
이제 함수의 형태를 일반화하여 표현하는 방법까지 알았으니 실제 문제를 풀어보자.
먼저 이해를 위해 데이터는 모두 1차원 벡터로 주어진다고 하자.
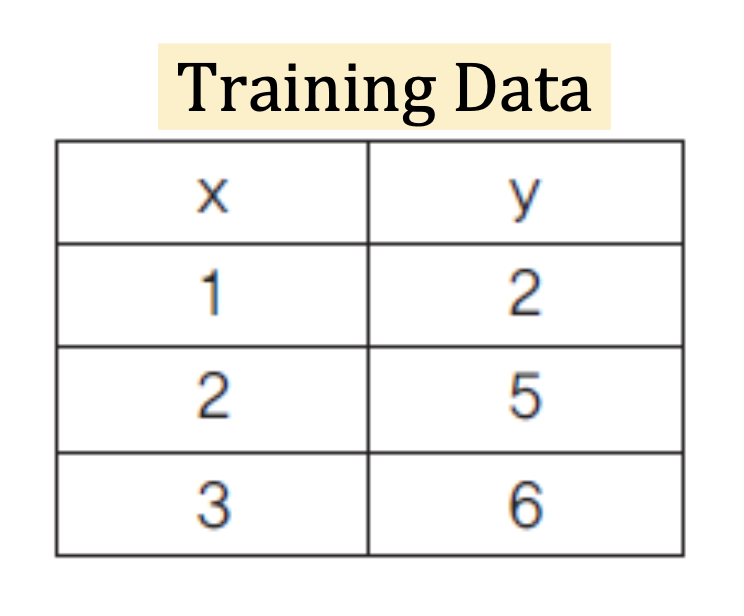
다음과 같은 훈련 데이터가 있을 때, 선형회귀는 이 데이터들의 분포를 가장 잘 나타내는 직선을 그리면 된다.
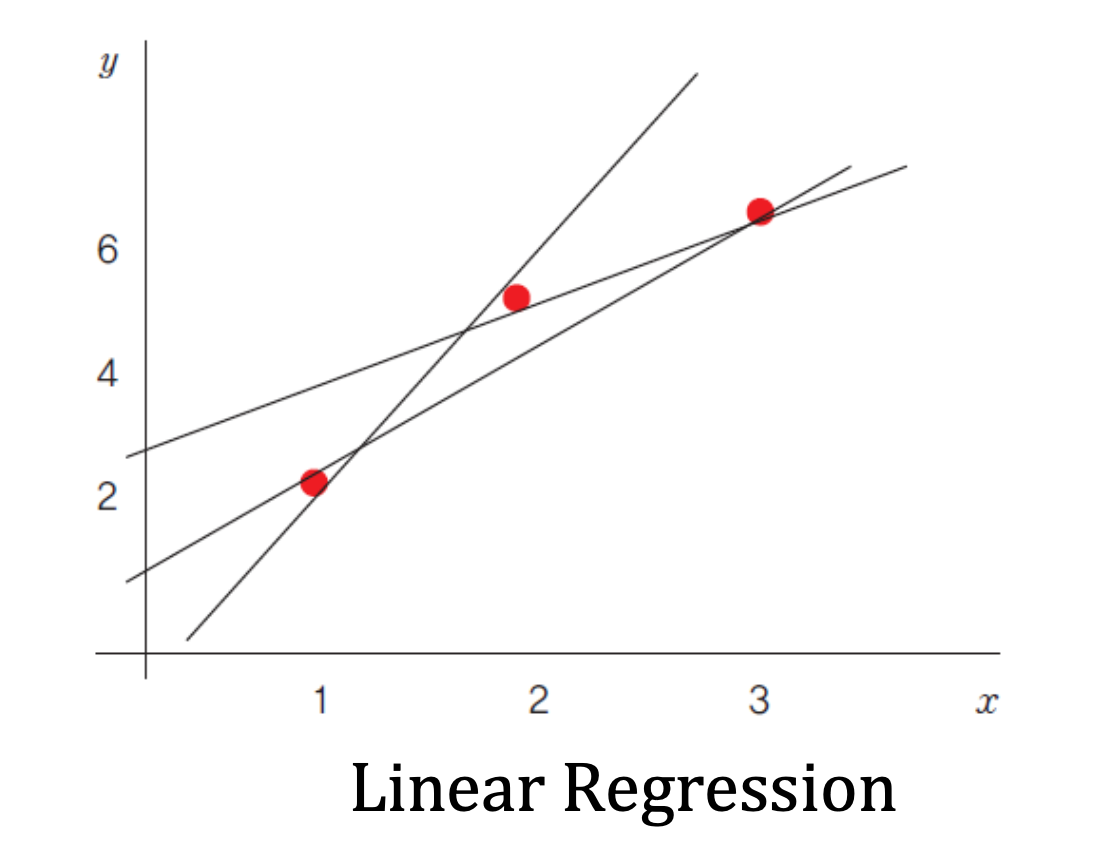
그런데 막상 직선을 그리려고 해보니 여러가지 직선이 그려질 수 있다.
이 직선들 중에서 가장 점들의 분포를 잘 나타내는 직선은 어떤 직선일까?
이 기준은 사람들마다 생각하는 것이 다를 수 있다.
따라서 선형회귀를 할 때는 가장 분포를 잘 나타내는 직선의 기준도 필요하다.
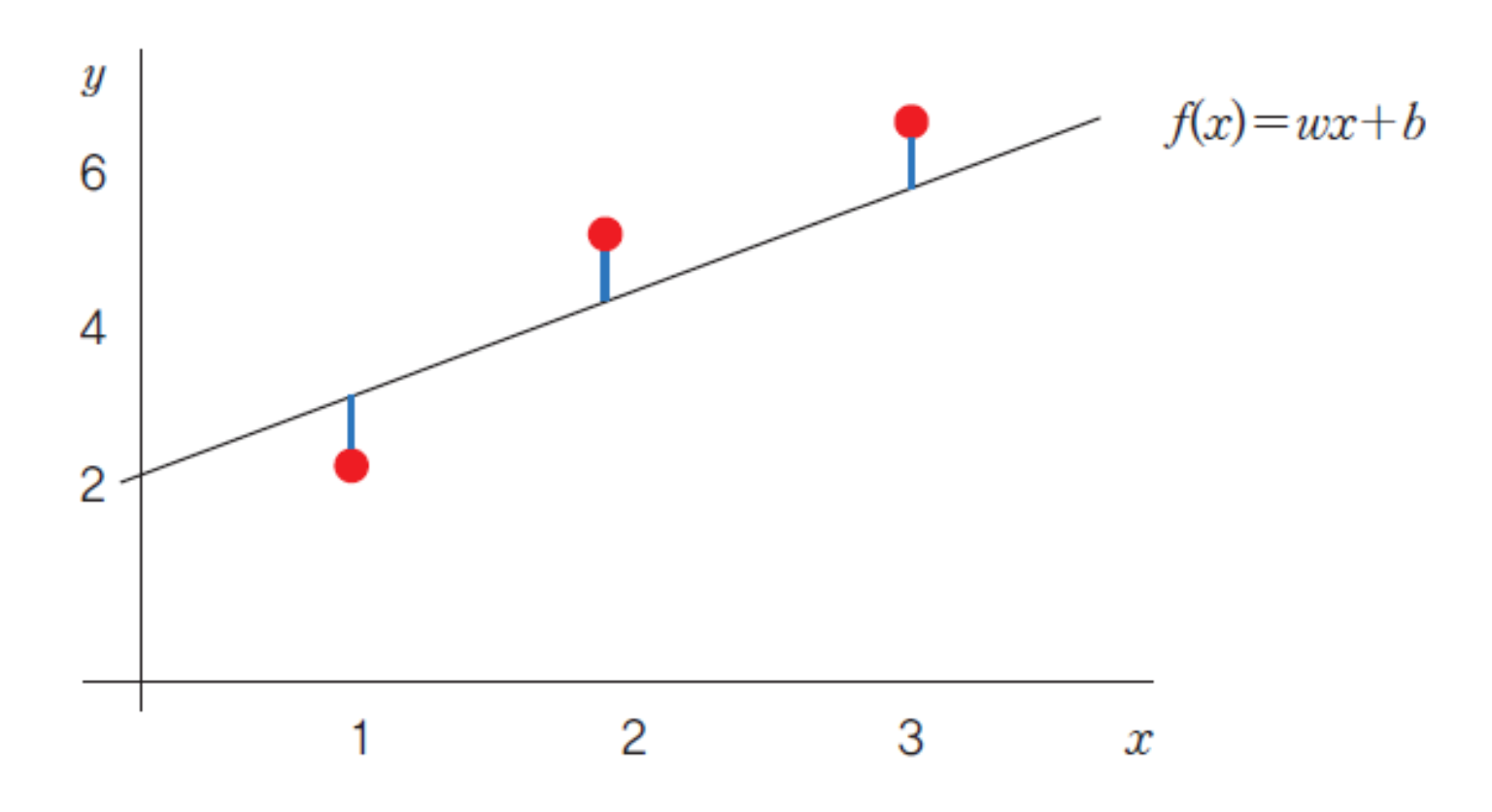
그 기준으로 삼기에 가장 좋은 것은 점과 직선 사이의 거리를 재는 것이다.
만약 모든 훈련용 데이터들과 직선 사이의 거리를 다 더했을 때 그 합이 최소가 된다면 제일 분포를 잘 나타내는 직선이라고 할 수 있지 않을까?
(참고 - 수학에서 y = f(x) 라고 쓰는 것과 달리, 기계학습에서 f(x)와 y는 다르다. f(x)는 x라는 입력에 대한 모델의 예측값이고, y 는 x에 대한 실제 데이터의 값이다.)
이를 조금 다르게 표현하면, 모델의 예측값과 실제 값 사이의 '오차'를 최소화하는 모델이 제일 좋은 모델이 아닐까? 로 말할 수 있다.
그리고 오차를 줄이는 방법은 다음과 같은 방법을 사용하면 되지 않을까?
1. 처음에는 임의로 w, b 값이 설정되어 있다.
2. 해당 모델에 훈련용 데이터를 넣어서 오차를 계산한다.
3. 오차가 줄어들도록 w, b 값을 수정한다.
4. 다시 2번부터 반복한다.
이때 w, b 2개 미지수의 값을 구하려면 몇 개의 데이터가 필요할까?
미지수가 2개이므로 2개의 데이터만 있으면 충분할 것이라고 생각하기 쉽지만, 통계학에서는 그렇지 않다.
우리는 두 점을 정확하게 지나는 직선을 찾는 것이 아니라, 여러 점들의 분포에 대한 '경향성' 을 나타내는 직선을 찾아야 하기 때문이다.
따라서 2개 이상의 점들이 있을 때, 그 중에 2개를 콕 집는다고 원하는 직선을 찾을 수 있다는 보장은 할 수 없다.
게다가 여러개의 점이 주어지면 그 모든 점을 정확히 지나는 직선은 존재하지 않는 경우가 대부분이다.
즉, 우리는 방정식이 y = f(x) 가 성립하는 f(x) 가 아니라, y와 f(x)의 차이(오차)가 최소가 되는 f(x) 를 찾아야 한다.
그리고 그런 f(x)는 점(데이터)들의 개수가 많으면 많을수록 정확해질 것이다.
이때 y와 f(x) 의 차이를 나타낼 때는 '절댓값'을 취하는 방법과 '제곱'을 하는 방법이 있다.
이번 글에서는 이 중에서 '제곱'을 사용하는 '제곱 오차'를 사용해보자.
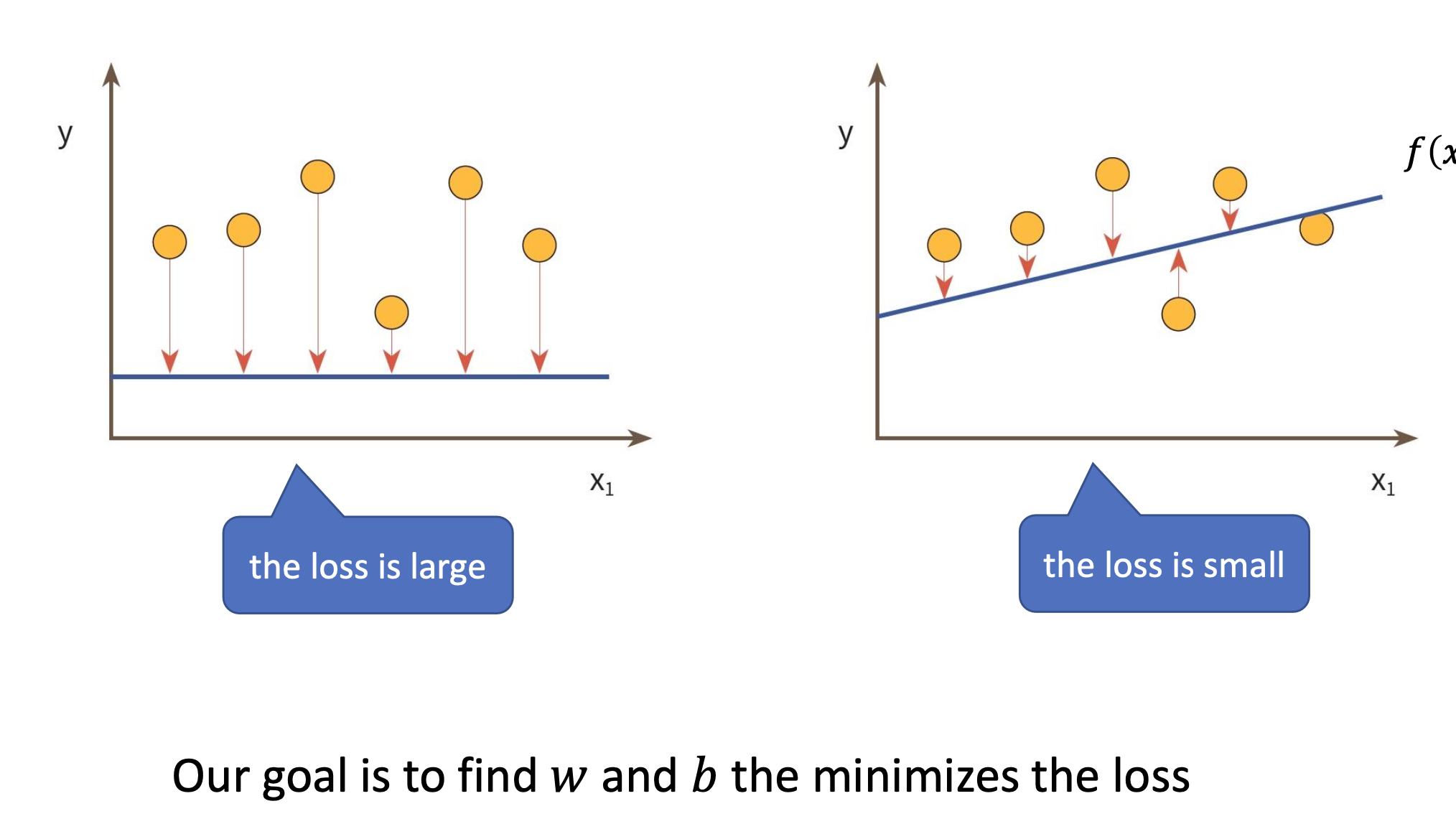
좋은 모델은 입력으로 주어진 모든 점들을 비슷하게 설명할 수 있어야 한다.
그러려면 모든 입력값에 대한 '제곱 오차'의 합(=모델의 총 오차)이 제일 작으면 좋을 것이다.
이때 기계학습에서는 '모델의 총 오차' 를 가리켜 '로스(Loss)' 라고 부른다.
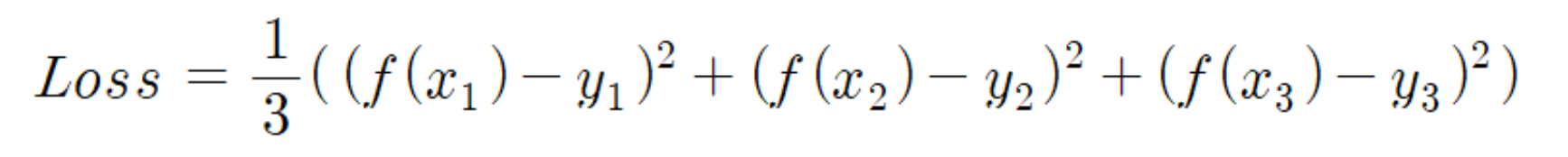
그리고 중요한 요소는 아니지만, 보통 데이터의 개수가 많아지면 Loss 의 크기도 커지다보니 데이터의 개수로 이를 나눠주기도 한다.
(의미상으로는 제곱 오차의 평균이 되겠다. 하지만 사실 나눠주지 않아도 지장은 없다.)
위의 식은 입력 데이터가 3개일 때 Loss 를 구하는 식을 나타낸다.
이를 n개 데이터에 대한 Loss 를 구하는 식으로 일반화하면 다음과 같다.
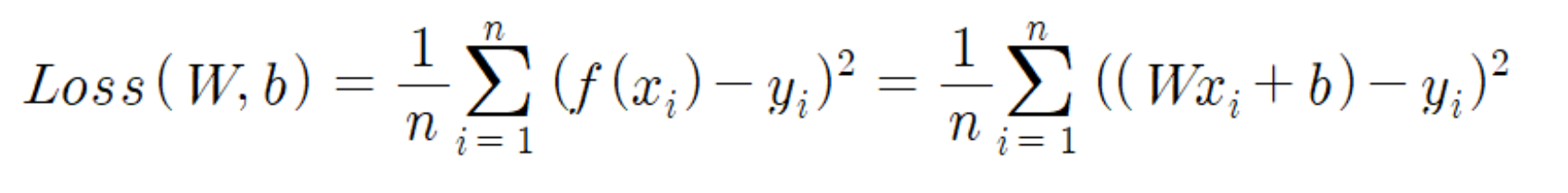
물론 여기에서도 1/n 을 곱하는 것은 선택이다.
(참고 - 지금은 선형모델에 대해 설명하고 있지만, 선형 모델과 상관없이 모든 Loss 는 위와 같이 표현한다. 단지 선형모델에서는 f(x)의 형태가 linear form 일 뿐이다.)
그리고 입력으로 주어지는 값 x, y 는 모두 고정되어 있기 때문에 Loss 값은 오직 W, b 에 의해서만 바뀔 수 있다.
따라서 Loss 값을 (W, b) 의 입력에 대한 결과값으로 보는 하나의 함수로 생각할 수 있다.
그러면 최종적으로 우리가 찾고자 하는 것은 Loss 값을 최소로 만드는 (W, b) 를 찾는 것, 즉, Loss(W, b) 의 최소값을 찾는 것이 목표가 된다.
이를 그림으로보면 위와 같다.
그러면 어떻게 해야 Loss(W,b) 의 최소값을 찾을 수 있을까?
정답은 '미분'이다.
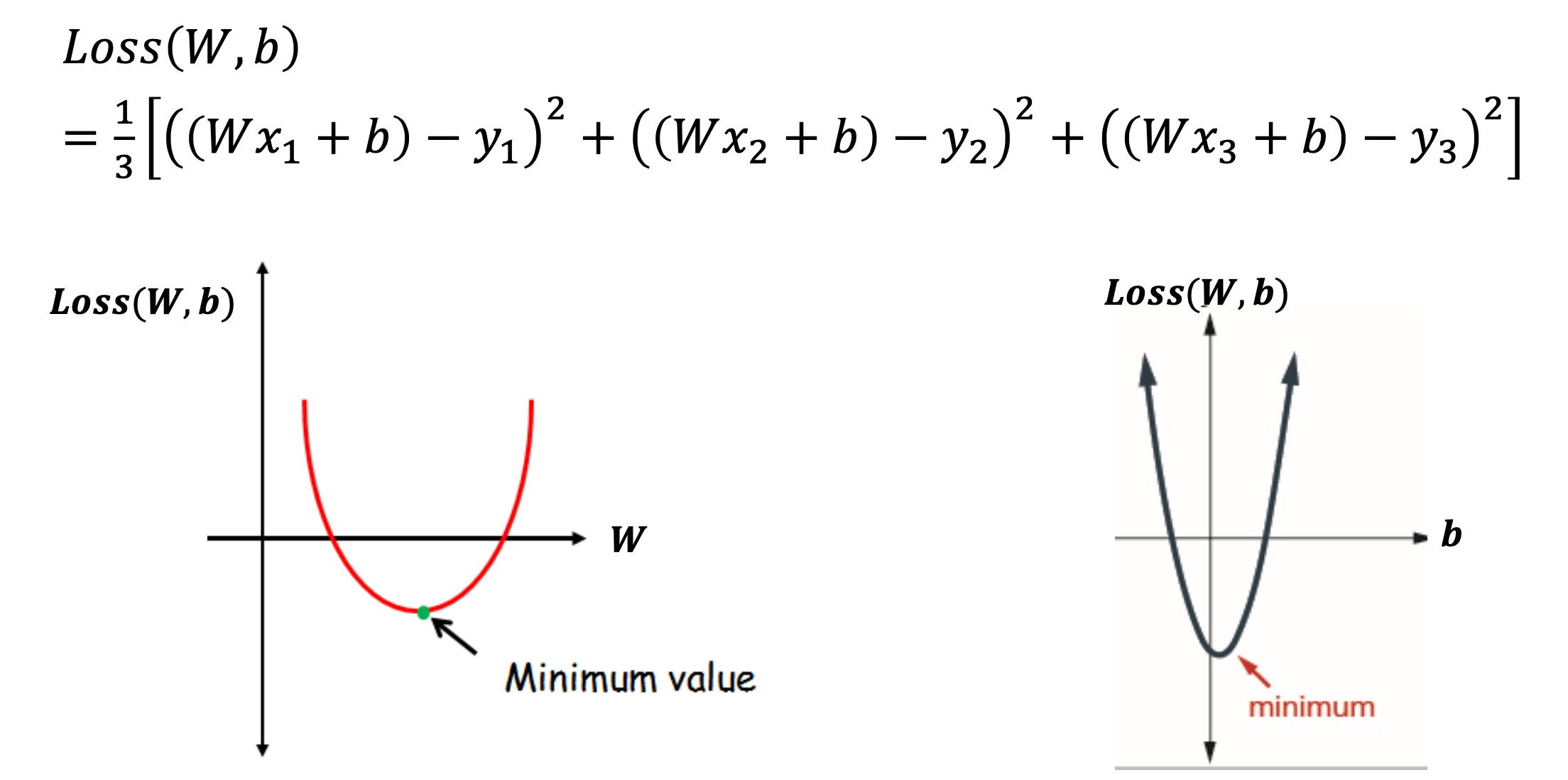
입력 데이터가 3개일 때 Loss(W, b) 를 풀어서 쓰면 위 사진에서 보는 것과 같은 식으로 나타낼 수 있다.
이때 위 식에서 제곱을 풀어서 다 계산하면 W 에 대한 2차식, b 에 대한 2차식이 나오는 것을 볼 수 있다.
그리고 W, b 중 하나의 값을 고정하고 그래프를 그린다고 하면 위와 같이 W에 대한 이차곡선, b에 대한 이차곡선이 나오며, 각각에 대한 최소값 포인트가 존재한다.
따라서 Loss(W, b) 를 W 에 대해서 미분하고, b에 대해서 미분해서 각각의 최소값이 되는 포인트(=미분값이 0인 점)를 찾으면 우리가 원하는 W, b 를 구할 수 있다.
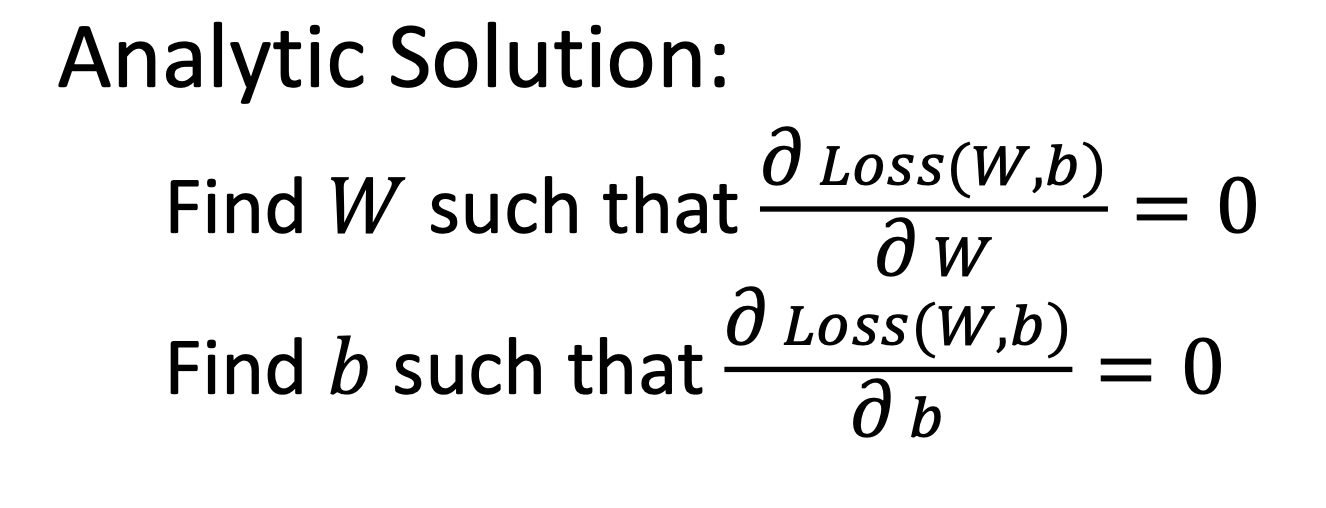
그리고 이런 방식을 Analytic Solution 이라고 부른다.
(그런데 개인적인 궁금증은 W, b 가 서로 독립적이라고 볼 수 있는 건지 궁금해진다. 하나는 기울기고 하나는 y 절편이니까 의미상으로는 독립적일 것 같기는 한데..)
그런데 이렇게 0으로 두고 방정식을 푸는 방법은 선형 회귀와 같이 간단한 모델에서는 사용할 수 있지만, 일반적으로는 사용할 수 없다.
오차를 구할 때 제곱오차가 아닌 다른 방식을 사용할 수도 있고, 애초에 사용하려는 모델의 형태가 선형 모델이 아닌 다른 모델을 사용할 수도 있는데, 이 경우 사용하는 모델에 따라 근을 구할 수 없는 경우도 존재하기 때문이다.
(다항식의 형태라고 하더라도 4차 다항식까지는 근이 반드시 존재하지만, 5차부터는 근이 존재함이 보장되지도 않는다.)
그래서 조금 더 일반적인 상황에서도 W, b 값을 결정하는 방법으로 '경사하강법'이 등장했다.
경사 하강법
경사하강법은 Practical Solution 으로, 반복 계산을 통해 점점 최적에 가까워지며 W, b 값을 찾는 방법이다.
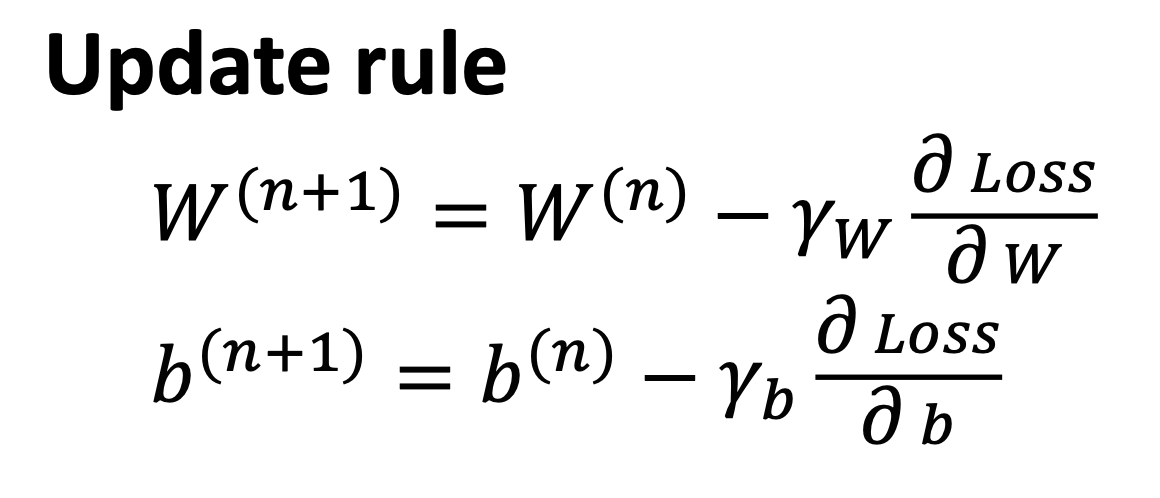
경사하강법에서는 초기 (n = 1) 의 W, b 값은 랜덤으로 세팅하고, 그 다음의 W, b 값을 구할 때는 위 규칙에 따라 업데이트 한다.
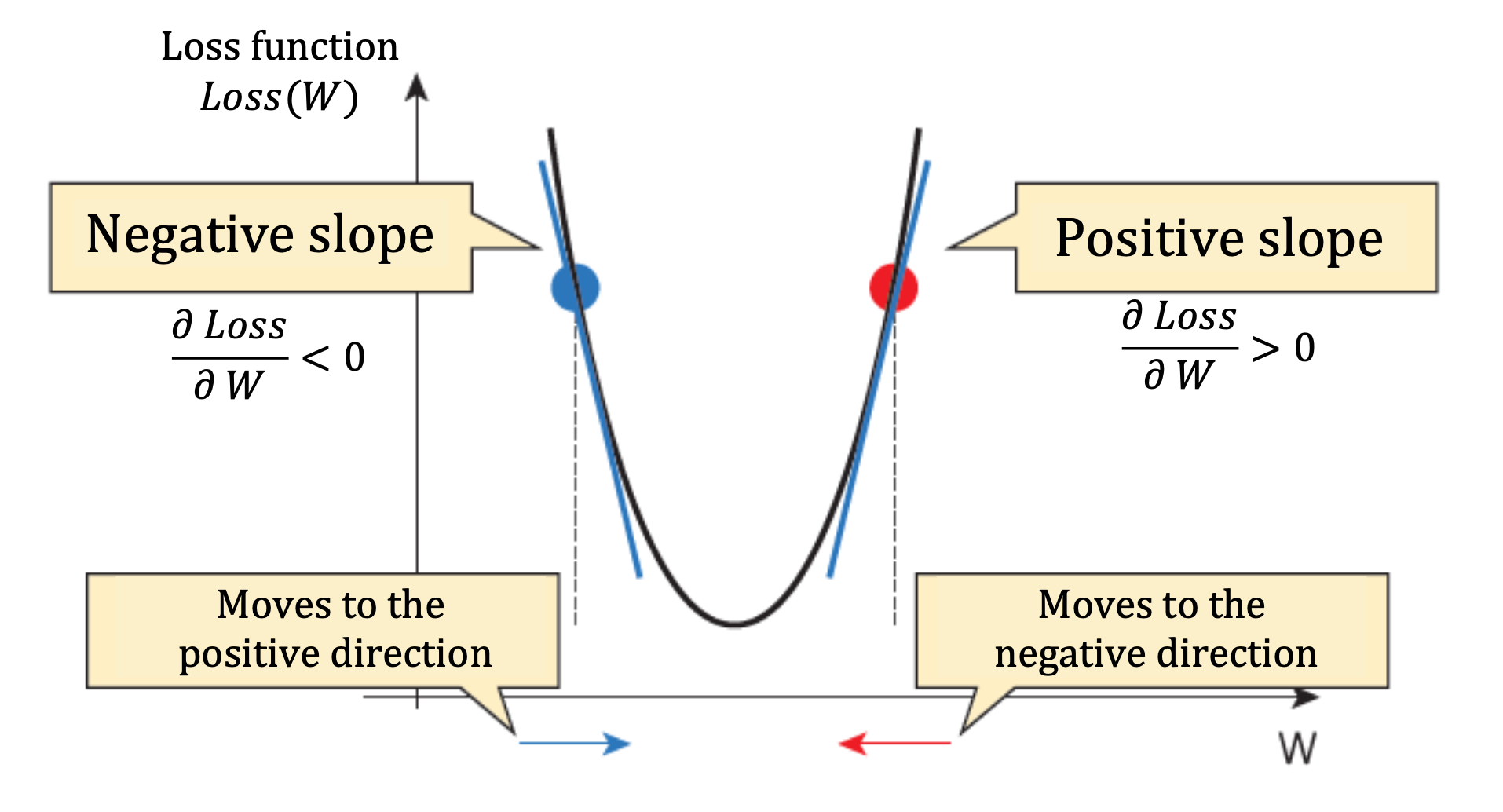
이 업데이트 규칙의 원리는 위와 같다.
먼저 W를 업데이트 하는 상황을 살펴보면, 특정 W 값에 대해 Loss(W,b) 의 기울기가 양수라면 기울기가 0에 가까울 수록 좋은 것이므로 다음 기울기는 감소해야 하고, 기울기가 음수라면 0에 가깝게 보내기 위해 다음 기울기는 증가해야 한다.
그러려면 그 다음 W의 값은 기울기가 양수일 땐 감소해야 하고, 기울기가 음수일 땐 증가해야 한다.
따라서 계산한 기울기 (δ Loss / δ W) 의 반대방향 (-) 으로 이동시키도록 W를 옮긴다.
그래서 update rule을 보면 기울기의 음수를 기존의 W(n) 에 더해주는 것이다.
이때 W값의 이동폭을 조절하기 위해 𝛄 를 곱해주는데, 이 감마값을 가리켜 Learning Rate 라고 부른다.
그리고 이 과정을 계속 반복하다보면 점점 기울기가 0에 가까워지는 W, b 값으로 수렴하게 되고, 그렇게 멈춘 순간의 W, b 값이 우리가 찾으려는 W, b 값이다.
이를 일반화하면
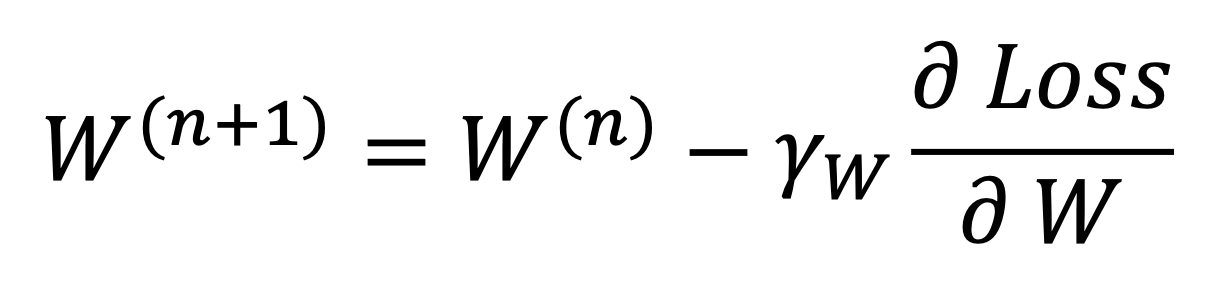
이렇게 나타낼 수 있다.
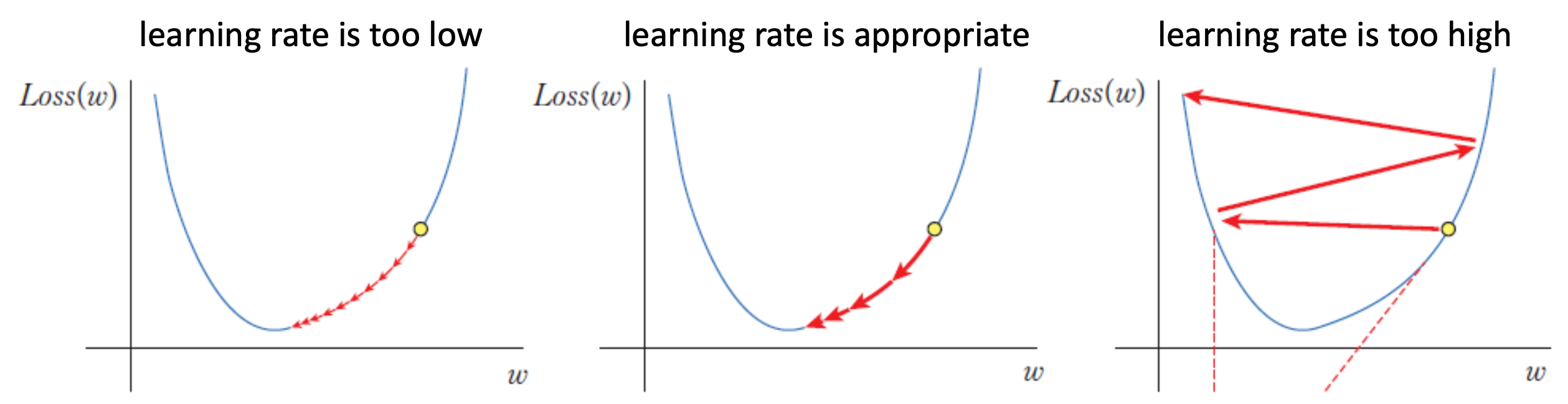
그런데 경사하강법에서는 learning rate 를 '적절하게' 설정하는 것 중요하다.
만약 너무 작은 값을 사용하면 최적의 값에 도달하기까지 너무 시간이 오래 걸리고, 너무 큰 값을 사용하면 원하는 값에 수렴하는 게 아니라 오히려 발산하기도 한다.
그러면 어떤 값이 제일 적절한가? 라고 물어보면.. 사실 알 수 없다.
따라서 적절한 임의의 값으로 넣어주어야 하는데, 대신 현재 값이 적절한지 아닌지는 판단하는 방법이 있다.
바로 매 단계를 반복할 때마다 Loss 값이 감소하고 있는지를 보는 것이다.
만약 반복해서 계산을 하고 있는데 Loss 값이 감소하고 있지 않다면 그 learning rate는 잘못된 값이므로 조금씩 튜닝해주면 된다.
(learning rate 를 자동으로 튜닝하는 기법도 있다. SGD, 딥러닝의 ADAM 옵티마이저 등)
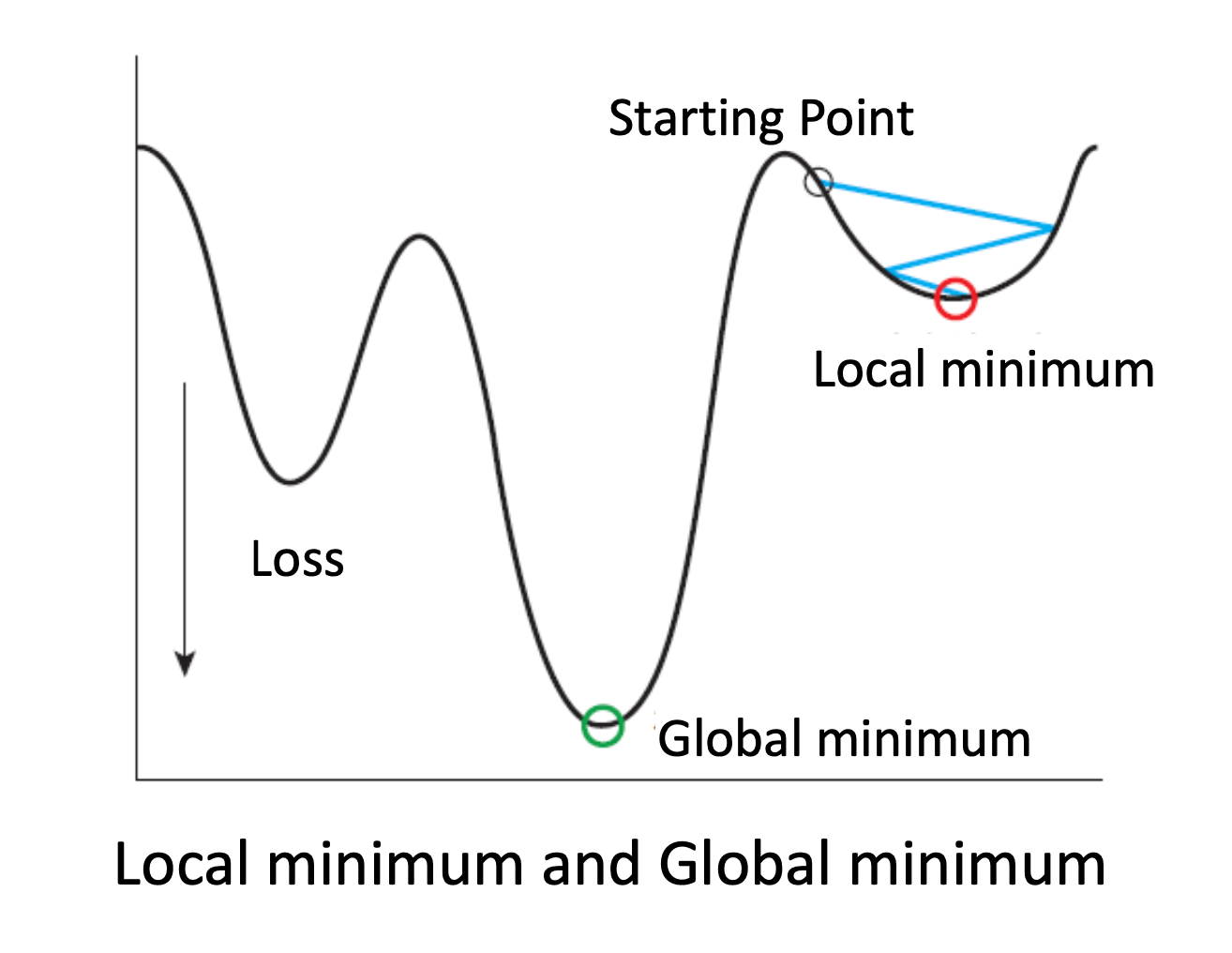
그런데 경사하강법은 치명적인 문제가 하나 있다.
바로 Local Minimun 문제이다.
(이 문제는 지금도 해결하지 못했다고 한다. 해결할 수 있다면 노벨상이나 필즈상을 받을 거라고..)
모델이나 오차 계산 방법에 따라 Loss 함수의 그래프가 이차곡선이 아니라 위와 같은 형태로 바뀔 수 있다.
그런데 경사하강법은 기울기가 0에 수렴하기만 하면 멈추기 때문에 운이 없으면 위와 같이 내 주변에서는 최소이지만 (local minimum) 전체적으로 봤을 땐 최소가 아닌 지점에서 멈출 수도 있다.
그래도 현재 머신러닝에서는 이렇게 하나의 local mininum 을 찾는 것에 만족하고 있다고 한다.
지금까지 선형회귀와 선형 회귀 모델에서 최적의 모델을 찾는 경사 하강법에 대해 정리하였다.
간단하게 요약하면 다음과 같다.
1. 기계학습은 주어진 데이터를 잘 설명하는 함수를 찾는 것이다.
2. 그 중에서 지도학습의 '회귀' 문제는 주어진 데이터의 '분포' 를 잘 나타내는 함수를 찾는 것이다.
3. 그런데 함수를 쌩으로 찾는 것은 불가능해서 함수의 '형태'를 먼저 정의해주고 해당 형태를 가진 함수 중에서 제일 잘 나타내는 함수를 찾는 아이디어를 떠올렸다.
4. 먼저 제일 간단한 형태인 '선형 함수' 로 생각하여 회귀 문제를 해결하는 것을 가리켜 '선형 회귀' 라고 한다.
선형 회귀에서는 f(x) = Wx + b 에서 W, b 를 찾는 문제로 바뀌어 간단해진다.
5. 이때 데이터의 분포를 가장 잘 나타내는 선형함수를 찾기 위해, 주어진 데이터들과 선형 함수 사이의 오차의 합 (=Loss) 이 최소가 되는 (W, b) 를 찾으면 된다. 이때 (W, b) 값에 대한 Loss 값을 Loss(W,b) 와 같이 함수로 나타낼 수 있다. (=Loss Function)
6. 우리가 원하는 것은 Loss 함수의 최소값을 찾는 것이므로 자연스럽게 미분을 떠올릴 수 있다. 그런데 단순히 '미분값이 0인 지점' 을 찾기 위해 방정식을 푸는 것은 일반적인 상황에 모두 사용할 수 있는 것은 아니다.
7. 그래서 일반적인 상황에도 모두 사용할 수 있도록 랜덤값에서부터 시작해 기울기가 0이 되는 지점을 향해 (W, b) 값을 반복적으로 수정하는 경사 하강법이 등장했다.
다음 글에서는 선형 회귀에서 경사하강법을 사용해 실제로 최적의 모델을 찾는 방법을 실제 파이썬 코드 구현과 함께 정리해본다.