[기계학습심화] 4. 경사하강법의 확장 & SGD
경사하강법의 확장
지난 글에서 본 예제는 입력도 1차원이고 출력도 1차원인 간단한 예제였다.
그래서 그래프를 그려볼 때도 2차원 좌표평면에 점을 찍고, 해당 점들을 잘 나타내는 직선을 그었다.
하지만 실제로 주어지는 데이터는 이보다 고차원의 데이터가 많이 들어온다.
이제 경사하강법을 고차원 데이터에서 어떻게 활용할 수 있을지 확장해보자.
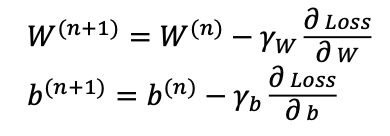
기존에 살펴본 경사하강법의 W, b 값 수정 공식은 위와 같았다.
선형회귀에서는 W, b 값 2개만 결정하면 되기 때문에 이를 다음과 같이 행렬로 표현할 수 있다.
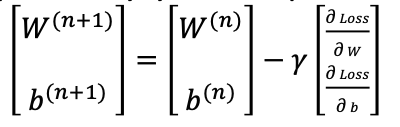
위 식에서는 learing rate 를 W, b 에서 서로 다르게 잡았지만, 위 행렬식에서는 같은 learning rate 를 가진다고 가정하였다.
이때 learing rate 오른쪽에 곱해진 행렬을 보면 Loss 함수를 W, b 에 대해서 각각 미분한 것이 요소로 들어가있는 행렬임을 볼 수 있다.
이렇게 어떤 함수를 각각의 변수에 대해서 모두 미분한 값을 벡터로 모은 것을 가리켜 Gradient 라고 부른다.
이를 한국어로는 '경사'라고도 하는데, 매번 기존의 W, b 값에서 경사를 빼주고 있기 때문에 '경사 하강법' 이라고 부르는 것이다.

그리고 Gradient 를 표현할 때는 위와 같이 역삼각형을 이용해서 표현한다고 한다.
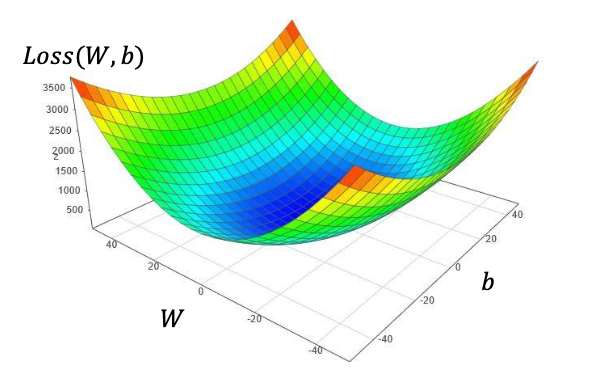
Loss 함수를 그래프로 그려보면 이렇게 나타난다.
W의 관점에서도 이차함수고, b의 관점에서도 이차함수로 보이는 이유가 이제 이해가 된다.
그리고 W의 관점에서 최저인 부분과 b의 관점에서 최저인 포인트를 찝으면 자연스럽게 전체 Loss 함수에서 최저인 부분이 찝어지는 것도 이해할 수 있다.
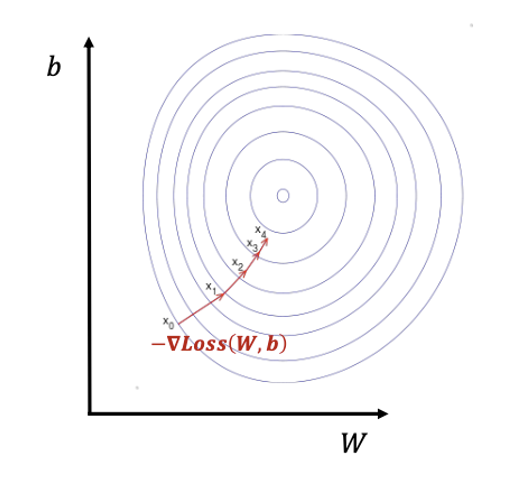
이 함수를 위에서 바라보고 등고선을 그려보면 위와 같이 나타낼 수 있다.
그리고 매번 Gradient를 구하고 업데이트할 때마다, 우리가 구하는 것은 W, b 값 하나하나를 구한 것이지만, 그 값을 모은 (W, b) 포인트는 점점 안쪽으로 들어가게 된다.

이제 조금 더 일반적인 상황을 생각해보자.
일반적인 상황에서는 x 로 들어오는 데이터가 하나의 숫자가 아니라 벡터가 들어올 수 있다.
꼭 데이터의 차원이 증가할 필요 없이, 지난 글의 몸무게 예측 모델을 만드는 것만 하더라도 여러 개의 데이터를 넣는 과정을 행렬로 한번에 계산할 수 있다.
그리고 이렇게 함수 모델을 정의했을 경우의 경사하강법 공식은 다음과 같이 나타낼 수 있다.
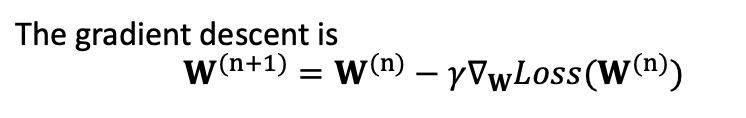
이렇게 하는 경우 경사하강법에서는 행렬 W 를 구성하는 모든 원소를 랜덤값으로 넣고, x 에 벡터를 넣어 Loss 를 계산하는 과정을 반복하여 행렬 W 를 구성하는 원소가 최소의 Loss 를 계산하도록 수정해나간다.
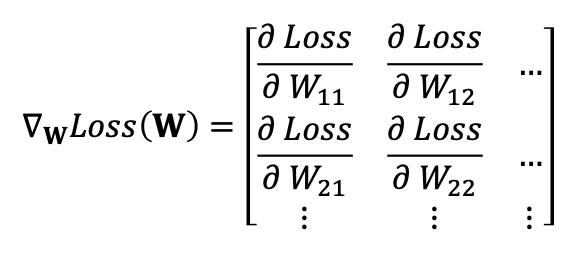
이때 행렬을 W 로 미분한다는 것은 Loss 함수를 행렬의 각 원소로 미분하는 것과 같다.
Stochastic Gradient Descent (SGD)
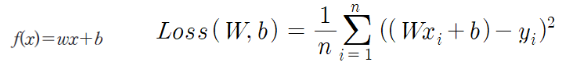
기존의 경사하강법 공식에서는 모든 데이터에 대해 매번 계산하고 더하는 과정을 반복하다보니 메모리와 CPU 연산량에 부담이 된다.
사실 우리가 원하는 것은 구체적인 미분 값도 물론 중요하지만 미분값의 부호, 즉 '방향' 을 아는 것이 제일 중요하다.
그런데 미분 값의 방향을 구하는데 꼭 모든 데이터에 대해 다 계산을 해볼 필요가 없다.
물론 모든 데이터에 대해 다 계산을 해야 제일 정확한 방향과 값이 나오겠지만, 100만 개, 1000만 개가 되는 데이터에 대해 열심히 계산해서 얻어내는 결과값이 미분값의 부호와, 그 기울기 값 정도라는 매우 작은 정보량의 데이터임을 감안하면 그다지 효율적이지 않다.
그래서 데이터를 다 쓰는 게 아니라 일부 데이터셋만 잘라내서 그 데이터 셋에 대해 Loss 합을 구하고 W, b 를 업데이트 하자는 아이디어가 나왔다.
이 기법이 Stochastic Gradient Descent, SGD 라고 하는 기법이다.
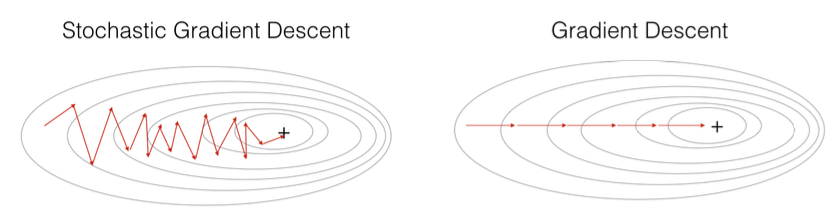
물론 SGD는 GD에 비해 일부 데이터만 사용하므로 정확도가 조금 떨어지는 경향이 있다.
하지만 조금 왔다갔다하더라도 훨씬 더 빠른 속도로 연산이 가능하며, 꾸준히 목표지점을 향해 나아가므로 결과적으로 더 빠르게 최적의 Loss가 되는 지점을 계산할 수 있다.
SGD는 100만개 데이터가 있을 때, 이걸 1000개씩 끊는다면, 일부 데이터를 가지고만 구하는 게 아니라, 1000개씩 끊은 데이터 1000 묶음을 1 묶음씩 돌려가면서 연산한다.
따라서 결과적으로는 모든 데이터에 대해 다 1번씩 연산하게 되고, 그렇게 100만 개 전체 데이터 셋에 대한 연산이 된 것을 가리켜 1 epoch 라고 한다.
다만 SGD도 단점은 있다.
SGD는 맨 처음에는 목표 기울기에 가까운 방향을 잘 찾는 경향을 보이는데, 점점 목표 기울기에 가까워질수록 목표 기울기에 수렴하지 못하고 마지막에 가서는 오히려 더 심하게 왔다갔다하는 경향이 있다.
마지막에 보는 mini-batch 데이터 셋에 조금 튀는 데이터가 있다면 그 데이터에 영향을 받아 목표 기울기에서 벗어나게 되기 때문이다.
GD는 그냥 계속 돌리다보면 알아서 0에 점점 가까워지므로 몸출 수 있는데, SGD는 위와 같은 경향이 있기 때문에 이 문제를 해결하기 위해서 점점 learning rate 를 낮추는 방법을 쓴다.
그러면 미분값이 0에 수렴하지는 않을 수 있더라도, 그 근처 어떤 값으로는 수렴하게 하는 것이다.
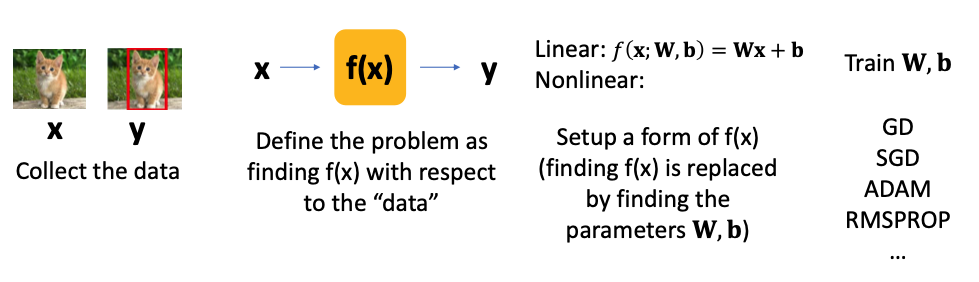
지금까지 선형회귀, GD, SGD 내용을 정리하였다.
이 내용은 기계학습의 구체적인 하나의 방법이지만, 이 방법을 통해 우리는 '기계학습의 전체적은 과정' 을 이해할 수 있었다.
기계학습을 위한 제일 첫 번째 단계는 데이터를 수집하는 것이다.
모델을 학습시키려면 데이터는 반드시 필요하고, 그 데이터의 질이 높고 많을수록 모델의 정확도는 올라간다.
그 다음은 이 데이터를 가지고 어떤 문제를 풀 것인지 정의해야 한다.
어떤 데이터가 주어졌을 때 어떤 결과가 나오기를 기대하는지 입력과 출력을 정의해야 한다.
그러면 이 문제는 이제 입력과 출력값을 매팡하는 함수 찾기 문제로 바뀐다.
다음 단계는 함수의 형태를 정의하는 것이다.
우리는 그 함수의 형태 중에서 선형 함수의 형태를 정의하였고, 함수의 형태가 정해진 후에는 함수식을 구성하는 계수를 찾는 문제로 바뀌게 되었다.
마지막 단계는 그 계수를 찾는 것이고, 지금까지 GD, SGD 라는 테크닉을 공부하였다.
하지만 이 외에도 ADAM, RMSPROP 과 같은 테크닉도 있다고 한다.
다양한 기법들이 있지만, 이 기법들의 궁극적인 목적은 항상 똑같다.
Loss 가 제일 작은 함수식의 W, b 값을 찾는 것이다.
앞으로 정리할 기계학습 관련 내용도 모두 이 프로세스와 관련되어 있다.
기계학습이 중간에 크게 발전하지 못 했던 것도 '함수의 형태를 정의'하는 단계에서 어떤 함수를 사용해야 할 지 몰랐기 때문이었다.
하지만 이 함수의 형태를 '뉴럴 네트워크' 형태로 정의하고 문제를 푸는 딥러닝 기법이 등장하고나서 기계학습도 한 단계 진보할 수 있었다.
이 프로세스도 조금 더 파고들면 그 안에서 다양한 기법이 존재한다.
예를 들어 데이터 셋을 구하는 것도 데이터의 수가 적다면 기존 데이터를 잘 합성해서 새로운 데이터를 생성하도록 한다거나, 입력값으로 데이터를 쌩으로 넣지 않고, 중간에 특징이 되는 데이터를 뽑는 전처리 단계가 들어갈 수도 있다.
출력값의 형태도 예를 들어 사물 인식이라고 한다면, 그 바운딩 박스가 그려진 이미지 전체를 출력으로 줄 수도 있지만, 바운딩 박스 4개 점의 (x, y) 좌표, 즉 8개 숫자값을 출력으로 정의할 수도 있다.
이렇게 입력값의 형태, 출력값의 형태를 정의하는 방법에 따라서도 모델의 성능 차이가 존재할 수 있다.
앞으로도 이런 디테일한 부분도 고려하여 하나씩 정리할 예정이다.