[기계학습심화] 5. KNN & Hyperparameter
지난 글까지 지도학습으로 만들 수 있는 모델 중 선형회귀 모델에 대해서 정리하였다.
이번 글부터는 지도학습으로 만들 수 있는 분류 모델 중 KNN 이라는 모델에 대해 정리해본다.
KNN
내가 사용하던 핸드폰을 중고로 판매한다고 생각해보자.
그러면 휴대폰 사양도 올리고, 사진도 올리고, 가격도 올릴 것이다.
이때 중고폰의 가격을 정할 때는 '시세'를 참고해서 정한다.
'시세'라고 하면 나와 같은 기종, 사양, 상태의 핸드폰이 최근 얼마에 거래되고 있는지를 보는 것이다.
기계학습에서는 '사양, 기종, 상태'와 같은 시세 평가 기준 역할을 하는 것을 가리켜 '피처' 라고 부른다.
현재 데이터의 피처를 알고, 이 피처와 비슷한 피처들을 찾아 그 피처들의 가격과 비슷하게 가격을 매기는 것과 같다.
KNN 알고리즘을 사용한 분류 방법도 이와 비슷하다.
kNN 알고리즘은 데이터를 분류하는 간단한 알고리즘으로 이름 그대로 'k 개의 가장 가까운 이웃' 들의 상태를 현재 데이터의 상태로 매핑한다.

먼저 주어진 그림과 같이 데이터가 분류되어있다고 해보자.
각 데이터는 (x1, x2) 라는 특성을 갖고 있고, 자신의 특성값에 따라 class 가 결정된다.
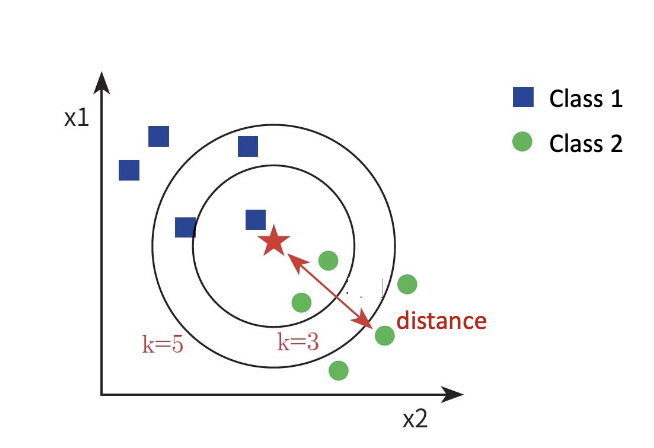
이때 새로운 데이터(★)가 하나 들어왔다고 해보자.
이 데이터를 class1, class2 중 하나로 분류하려고 할 때 어떻게 분류해야 할까?
kNN 알고리즘에서는 이 데이터와 가장 가까운 데이터를 k 개 뽑고, 주변 데이터들의 class 를 확인해서 제일 많이 속한 class 로 이 데이터를 분류한다.

kNN 알고리즘은 간단하다.
먼저 분류할 새로운 데이터를 기준으로 다른 모든 점들과의 거리를 계산한다.
그리고 그 거리를 정렬해서 제일 가까운 순으로 k개의 데이터를 뽑아서 그들이 속한 class 에 투표하여 제일 높은 득표수를 얻은 class로 분류한다.
이때 k값은 1로 잡아도 되고 임의의 숫자로 잡아도 된다.
다만 임의의 숫자로 잡는 경우 홀수로 잡는 경우가 많다. 분류시 4:4 와 같이 동률이 나오면 하나로 결정하기 힘들기 때문이다.

kNN과 같은 알고리즘을 사용하면 주어진 이미지가 어떤 동물을 나타내는지 분류하는 작업을 할 수 있다.
물론 이미지를 분류할 때는 단순히 픽셀값만 가지고 분류하면 정확도가 높지 않기 때문에 다양한 요소를 고려해야 한다.

kNN 알고리즘은 이웃을 선택할 때 '거리'를 기준으로 선택한다.
이때 사용하는 '거리' 는 다양한 방법으로 구할 수 있다.
- L2 distance (유클리드 거리)
두 점사이의 거리를 구할 때 흔히 사용하는 피타고라스의 정리를 활용한 방법이다.
(선형회귀에서 Loss 를 구할 때 제곱오차를 활용한 것과 관련이 있다. 제곱오차를 사용할 때는 루트를 씌우나 안씌우나 답이 같으니 굳이 씌우지 않았을 뿐이다.)
- L1 distance (맨하튼 거리)
두 점사이의 각 좌표값 차이의 절댓값을 더한 것

예를 들어 두 이미지간의 차이를 계산할 때 픽셀값을 각 위치별로 빼서 그 차이의 '절댓값'을 구하고 그 절댓값의 합을 거리로 볼 수 있다.
- Hamming Distance
두 데이터를 구성하는 각 성분을 하나씩 비교하여 다르면 1을 더해서 거리를 구하는 방법
두 문자열 사이의 유사도를 측정할 때 사용한다. (문제해결기법에서도 다뤘었다.)
- 코사인 유사도
점 두개를 벡터로 나타냈을 때, 두 점 사이의 각을 보는 것이다.
이 각이 0도에 가까울수록 (cos값이 1에 가까울수록) 유사도가 높다.
kNN을 사용해서 데이터를 분류할 때 어떤 거리를 사용할지 결정하는 것도 중요하다.
거리를 재는 방법마다 서로 다르게 거리를 측정할 수 있기 때문이다.

이 그림은 각 점들을 분류한 상태를 보여준다.
각 점의 색은 그 점이 분류된 클래스를 나타내고, 배경색은 새로운 점이 해당 영역에 찍혔을 때 해당색의 클래스로 분류되는 영역을 나타낸다. 그리고 이렇게 영역을 그리다보면 영역과 영역 사이의 경계선이 그려진다.
이 경계선을 가리켜 Decision Boundary 라고 부른다.
그런데 지금 경계선을 보면 굉장히 들쭉날쭉한 경향이 있다.
또한 노란색 영역이 초록색 영역 한 가운데 들어가있는 경우도 있다.
현재 그림은 kNN에서 k = 1 일 때 분류되는 영역을 나타낸 것이다.
이렇게 1-NN은 decision boundary 가 들쭉날쭉하게 그려지는 특징이 있다.
이렇게 들쭉날쭉하게 경계선을 그리도록 유도하는 독특한 데이터를 가리켜 '아웃라이어' 라고 말한다.
아웃라이어 데이터들은 데이터의 패턴을 찾을 때 방해한다.
그렇다면 k값을 조금 늘려서 영역을 그려보면 어떨까?

이 그림은 k = 3 일 때의 영역을 나타낸 그림이다.
확실히 k = 1 일 때보다 영역에서 들쭉날쭉한 부분이 사라지고 더 부드러워진 것을 볼 수 있다.

그리고 outlier 데이터들에게 크게 영향을 받지 않고 경계선을 그리는 것을 알 수 있다.
그런데 그림을 보면 하얀색으로 색이 칠해지지 않은 영역들이 존재한다.
k 값이 1보다 커지면 이렇게 동점이 생겨서 어디로 분류해야 할 지 모호해지는 영역이 생긴다.
예를 들어 1 1 1 1 로 같은 거리가 3개를 넘어가서 존재하면 이 중에 3개를 어떻게 고를지 모호해지므로 분류할 수 없거나
거리순으로 1 1 1 을 뽑았는데, 1 1 1 세 개 거리가 모두 서로 다른 클래스에 속한 경우에도 클래스를 분류할 수 없다.
이렇게 k 값이 커지면 모호해지는 영역이 생겨 분류가 안되는 경우가 생기는 것이 KNN 방식의 단점이다.

또 같은 k 값을 설정했다고 하더라도, 어떤 방식으로 거리를 구하는 지에 따라 영역이 조금씩 다르게 그려질 수 있다.
왼쪽은 L1 거리를 사용하였고, L2 거리에 비해 Decision Boundary가 울퉁불퉁하게 그려지는 것을 볼 수 있다.
위 예제는 스탠포드에서 만든 다음 웹사이트에서도 확인할 수 있다.
http://vision.stanford.edu/teaching/cs231n-demos/knn/
Hyperparameter
선형 회귀는 기계학습을 통해 선형 모델의 파라미터 W, b 값을 결정하는 것이 목표였다.
이런 값들을 가리켜 'parameter' 또는 'trainable parameter' 라고 부른다.
그런데 KNN 에서 k 값을 얼마로 사용할 지, 어떤 거리 측정 방법을 사용할 지는 우리가 얼마로 사용하겠다고 직접 결정해야 하는 값들이다.
이렇게 우리가 임의로 결정해야 하는 변수 값들을 가리켜 Hyperparameter 라고 한다.
그리고 하이퍼 파라미터들이 튜닝의 대상이 된다.
하이퍼 파라미터를 튜닝할 때는 기본적으로 파라미터에 넣을 수 있는 모든 값들을 넣어보면서 어떤 값이 제일 좋은 결과를 내는지 확인하는 방법을 쓴다.
이때 튜닝하는 구체적인 방법들을 고민해보자.
1. 모든 훈련용 데이터 셋으로 하이퍼 파라미터를 찾는다.
제일 간단하게는 하이퍼 파라미터를 세팅하고 기존에 모델을 학습시킬 때 사용할 모든 데이터 셋을 넣고 학습시켜서 어떤 하이퍼 파라미터가 좋은지 판단할 수 있다.
어떤 하이퍼 파리미터가 좋은지 판단하는 것은 테스트 데이터에 대해 얼마나 잘 맞추는지 정확도를 가지고 판단한다.
그런데 이 방법은 학습 데이터와 하이퍼 파리미터를 판별하는데 사용한 데이터가 동일하기 때문에 좋은 방법이 아니다.
k = 1 일 때 무조건 정확도가 100% 로 나오기 때문이다
예를 들어 하이퍼 파라미터를 튜닝하는 과정을 따라가보면
1. k값을 임의로 지정한다. (k = 1)
2. 해당 k값으로 세팅한 모델을 모든 데이터셋을 활용해 학습시킨다.
3. 학습된 모델에 모든 데이터 셋을 넣어보며 올바르게 분류하는지 확인한다.

이때 k 값을 세팅하고 학습시킨 데이터 셋과, 해당 모델이 올바르게 분류하는지 검증하는 데이터 셋이 동일하다.
사실상 k = 1 로 세팅시킨 모델에 똑같은 데이터를 2번 넣는 것과 다를 바가 없다.
그러면 검증할 때 무조건 잘 분류했다고 검증할 수 밖에 없다.
그리고 특히 k = 1 이라면 정확도가 무조건 100%로 나온다.
검증 데이터를 넣을 때마다 모델을 학습시킨 데이터셋에 자기 자신이 들어있으므로 거리가 0인 점이 반드시 존재하기 때문이다.
그리고 k 값이 증가하면 k개를 뽑았을 때 거리가 0인 점 최소 1개와, 거리가 0보다 큰 점이 여러 개 포함될텐데, 이때 거리가 0보다 큰 점들이 거리가 0 인 점과 다른 클래스라면, 그 다른 클래스로 해당 점을 분류하면서 모델의 정확도가 당연히 떨어질 수 밖에 없다.
따라서 k = 1 일 때 무조건 성능이 정확도 100%로 찍힐 수 밖에 없으므로 의미가 없다.
(극단적인 케이스가 무조건 가장 좋다고 판정한다.)
하지만 우리는 아웃라이어를 피해서 모델을 훈련시키기를 원할 수도 있으므로 이런 상황에서는 다른 방법으로 하이퍼파라미터를 튜닝해야 한다.

그래서 이 문제를 해결하기 위해 우리가 가지고 있는 전체 데이터셋을 쪼개는 방법을 떠올릴 수 있다.
하이퍼 파라미터를 테스트하는 용도의 test 데이터 셋과, 훈련용 train 데이터셋을 나누는 것이다.
실제로 따라가보면
k = 1 의 정확도를 검증하기 위해서 k = 1로 세팅한 KNN 모델을 train 데이터로 학습시킨다.
그리고 이 모델에 test 데이터를 넣어보면서 정확도를 체크한다.
이 과정을 k = 2, 3, 4... 에 대해 반복하고 거리를 재는 방법을 L1, L2 distance 로 바꿔가면서 또 해본다.
그러면 test 데이터에 대해 제일 높은 정확도를 보이는 k 값과 거리 계산 방법을 채택할 수 있다.
이때 test 데이터는 당연히 모델을 학습시킬 때 사용하면 안된다.
수능 문제를 잘 푸는 모델을 학습시킬 때 2020년 수능 문제를 넣어서 학습 시킨뒤, 그 모델에 2020년 수능 문제를 넣어서 검증하면 당연히 정확도가 100%로 나올 수 밖에 없다.
그런데 이 방식도 여전히 문제가 있다.
하이퍼 파라미터를 검증하는 용도의 데이터셋이 정해져 있기 때문에, 그 하이퍼 파라미터의 값은 'test 데이터 셋에 대해서만 잘 동작하는' 하이퍼 파라미터일 수도 있는 것이다.
(하이퍼 파라미터를 결정할 때 계속 똑같은 'test' 데이터 셋에 대해 학습시켰기 때문)
그래서 이를 검증하기 위해 최종적으로 모델의 성능 평가용 데이터가 필요하다.

그래서 이렇게 또 데이터 셋을 분리해서 최종 평가용 데이터 셋을 둘 수 있다.
train 은 모델을 학습 시키는 용도의 데이터 셋
validation 은 하이퍼 파라미터를 튜닝할 때 사용하는 데이터 셋 (기존의 test set에 해당)
test 는 최종 모델의 성능을 평가할 때 사용하는 데이터 셋이다.
보통 train 데이터는 전체에서 70% 정도를 사용하고, 나머지 30%를 검증용으로 사용한다고 한다.
그런데 처음엔 이렇게 분리하는 게 더 좋은 이유가 이해가 안됐다.
교수님은 validation set 으로 튜닝한 파라미터가 test 에서도 잘 일반화되어 동작할 것이라고 믿고 한다고 말씀해주셨는데, 그렇게 믿을 수 있다면 굳이 test set 을 분리해서 검증할 이유가 없다고 생각했기 때문이다.
(비유를 validation set 은 모의고사, test set 은 수능처럼 생각할 수 있다고 말씀해주셨다.)


지피티 말로는 파라미터를 튜닝하는 과정에서 매번 똑같은 validation set 을 가지고 튜닝했기 때문에 어쩌면 이 모델은 그 validation set 에 잘 맞는 하이퍼 파라미터로 튜닝되었을 수 있기 때문에 이를 검증하기 위해 test set 이 별도로 필요하다고 한다.
헷갈리지 않게 정리하면
validation set은 성능 테스트를 통해 하이퍼 파라미터를 튜닝하기 위한 목적이고,
test set은 정말로 성능을 테스트하기 위한 목적이다.
따라서 validation set 을 통해서 테스트한 성능이 ~ 나와서 좋다! 라고 하는 건 말이 안된다.
그 성능이 좋았기 때문에 그 하이퍼 파라미터 값으로 세팅이 된 것이고, 실제 성능은 test 데이터 셋으로 검증한다.
(실제로 딥러닝 할 때도 에포크를 얼마로 하고, learning rate 를 얼마로 할지 정해야 하는데, 이때 validation set 을 사용해서 이 하이퍼 파라미터들을 결정한다.)
만약 test 데이터 셋을 넣었더니 validation set 에서 본 것보다 성능이 안 좋게 나왔다면 어떨까?
그 경우가 바로 validation set 에만 잘 맞는 하이퍼 파라미터로 튜닝된 경우다. (이를 validation set 에 over-fitting 되었다고 표현한다.)
그리고 이 문제를 해결하기 위한 아이디어가 바로 Corss-Validation 이다.

위에서 말한 문제는 하이퍼 파라미터를 튜닝할 때 매번 같은 데이터 셋을 가지고 튜닝했기 때문에 발생한 문제였다.
특히 데이터를 잘못 잘라서 어떤 특징을 위주로 가진 데이터셋을 잘못 자르면 하이퍼 파라미터가 잘못 튜닝되기 쉽다.
그렇다면 튜닝할 때 사용하는 validation set 을 매번 바꿔주면 되지 않을까? 라는 생각을 떠올릴 수 있다.
따라서 위와 같이 데이터를 fold 단위로 쪼개고, validation set 을 fold 중 하나를 고르는 방법을 취하면 특정 data set 에 맞춰서 하이퍼 파라미터가 튜닝되지 않도록 방지할 수 있다.
또 이렇게 validation set 을 돌려가면서 사용하면 모델을 학습할 때 사용하는 트레이닝 데이터 양이 늘어나는 효과도 있다.
위 그림 예시는 5-folds cross validation 방식으로, test 데이터 셋 이외의 데이터 셋을 5개 fold 로 나눠 사용한다.
그림에서는 3가지 구성만 보여주었지만, 이렇게 5개로 쪼갠 경우에는 5개의 성능을 모두 구해서 그 평균 성능을 최종 성능으로 본다.
만약 k 값이 1, 3, 5, 7 로 4가지 후보가 있고, 거리 측정 방법에 L1, L2 로 2가지 방법이 있다면
테스트할 하이퍼 파라미터 조합은 총 8가지이고, 이 8가지 조합을 5가지 fold 구성에 대해 반복적으로 구해야 하므로 총 40번의 실험을 해야 한다.
이때 5가지 fold 구성에 대해 실험한 결과의 평균 성능을 8개 구하면 그 8가지 평균 성능 중에서 제일 좋은 성능을 보이는 하이퍼 파라미터 조합을 최종 모델의 하이퍼 파라미터 값으로 결정한다.
(이 방법이 n-fold cross validation 방식이다.)
다만 이 방법의 단점은 fold 를 나눌 수록 실험을 반복해야 하다보니 굉장히 복잡해진다.
따라서 데이터 셋의 규모가 작은 경우에 이 방법을 활용해야 하고, 빅 데이터를 구할 수 있는 경우(주로 딥러닝)에는 이렇게 하기보다 3번째 아이디어를 자주 활용한다. (training, validation, test 데이터 셋만 정적으로 분리하여 사용)

이 그래프는 5-fold cross validation 방식으로 kNN 알고리즘의 k 값을 튜닝한 결과이다.
각각의 점은 특정 k 값에서 각 fold 별 cross-validation 정확도를 나타내고, 파란색 선은 그 평균값을 구해 이은 것이다.
이렇게 보면 평균값이 제일 높은 구간이 k = 7 인 순간이라고 한다.
(k = 7 일 때 validation set 에 대한 성능이 제일 좋았으므로, test 데이터 셋에서도 일반화가 될 거라고 믿고 고르는 것)
이렇게 kNN 알고리즘과 kNN 알고리즘으로 모델을 학습시키는 과정에서 등장한 하이퍼 파라미터의 개념을 정리해보았다.
kNN 알고리즘은 학습 시간이 없다는 장점이 있다. 그냥 훈련 데이터를 뿌려놓는 것으로 학습이 끝나기 때문이다.
대신 이 모델에서 새로운 데이터에 대해 분류(추론)할 때 훈련데이터 모두와 거리를 구하고, 최상위 k 개 데이터를 선별해야 하므로 시간 복잡도가 O(N) 이다. (정렬까지 하려면 O(n log n) 아닌가?)
시간복잡도가 O(n) 이라는 것은 데이터의 숫자가 늘어날 수록 추론 시간이 늘어난다는 뜻이고, 이는 머신러닝에게 있어 큰 단점이다.
머신러닝은 보통 훈련시간이 오래 걸리는 것은 괜찮아도, 추론은 빠르게 되기를 원하기 때문이다.
예를 들어 구글에서 검색할 때 kNN 알고리즘을 사용한다는 것은 내가 입력한 검색어를 구글에 있는 모든 데이터 셋과 비교해서 제일 유사한 것을 순서대로 보여준다는 것과 같다.
당연히 검색 시간이 매우 오래 걸릴 것이다. 그리고 교수님 말씀으로는 알고리즘 특성상 결과도 잘 안 나온다고 한다.
(k값이 1보다 커지면 회색지대가 생겨 분류할 수 없는 영역이 생기는 문제)
다음 글에서는 kNN 알고리즘을 실제 코드로 구현해보고자 한다.