[기계학습심화] 10. 딥러닝 (1) - 선형 분류 모델
Linear Classification
지금까지 선형회귀, kNN, SVM, k-menas, PCA 등 지도/비지도 학습으로 회귀 및 분류 모델을 만드는 과정을 살펴보았다.
이번 글에서부터는 분류 모델 중 선형 분류 모델에 대한 일반적인 이야기에서 시작하여 딥러닝에 대한 정리를 시작한다.

기계학습은 결국 입력값과 출력값이 주어졌을 때 이 둘을 잘 매핑하는 함수를 찾는 문제였다.
이때 지도 학습은 입력값과 출력값을 모두 활용해서 함수를 찾고, 비지도 학습은 입력값만 가지고 함수를 찾는다는 차이가 있었다.

하지만 함수를 쌩으로 찾는 것은 쉽지 않다보니 함수의 형태를 정의하고, 그 함수식에서 비어있는 계수를 찾자는 parameteric approch가 등장했다.
파라미터를 찾을 때는 Loss function 과 Optimization 2가지가 활용된다.
Loss는 우리가 만든 함수 f 가 예측한 값 f(x) 와 실제 값 y의 차이를 에러라고 할 때, 그 에러의 총합을 말한다.
그리고 이 차이를 계산하는 방법에도 절댓값, 제곱오차 등 다양한 방법이 있었다.
Loss 값은 함수식에서 어떤 W, b 값을 사용하는지에 따라 달라지기 때문에 W, b 에 대한 함수처럼 생각할 수 있다.
이 함수를 Loss Function 이라고 부른다.
그리고 Loss Function 으로부터 가장 낮은 Loss 값을 갖는 최적의 W 를 찾는 것을 가리켜 Optimization 이라고 한다.
대표적인 Optimization 기법이 경사하강법(GD) 이다.

이제 간단한 이미지 분류 예제를 생각해보자.
이 모델은 50 * 50 * 3 = 7500 차원의 데이터를 입력으로 받아서, 입력으로 주어진 이미지가 5가지 종류의 물체 중 어떤 물체에 해당하는지 5차원 벡터로 응답하는 모델이다.
위 그림에서는 주어진 이미지가 자동차 이미지라면 5가지 종류 중 4번째 종류에 해당하여 <0, 0, 0, 1, 0> 이라는 응답을 내보냈다.
(이때 각 자리의 숫자가 나타내는 것은 확률이다. 첫 번째 종류일 확률 0, ... , 4번째 종류일 확률 1, 5번째 종류일 확률 0 과 같은 식이다.)

이 모델을 parametric approach 를 사용하여 학습시킬 때, 이렇게 함수의 형태를 선형 함수인 Wx 로 정의하고 W 를 찾는 문제로 바꾸어 풀 수 있다. 이렇게 선형함수를 사용하여 이미지를 분류하는 것을 Linear Classification 이라고 한다.
위 그림을 보면 함수를 f(X; W) 로 표현하였는데, X 는 입력으로 주어지는 데이터이고, W 는 학습시킬 파라미터를 가리킨다.
딥러닝 논문에서 자주 이렇게 세미콜론을 사용하여 입력 데이터와 학습시킬 파라미터를 구분해서 표기한다고 한다.
실제로는 W 대신 θ 를 자주 사용한다고 한다. 세타는 학습시킬 모든 파라미터를 모은 벡터를 의미한다고 한다.

이때 7500 x 1 크기의 데이터가 들어왔을 때 출력으로 5 x 1 크기의 데이터로 나와야 하므로, 변환행렬 W 의 크기는 5 x 7500 이다.

원하면 이렇게 bias 까지 포함해서 표현할 수 있으나, 이는 선택이라고 한다.
이 경우에는 W, b 가 학습의 대상이 될 것이다.
Loss Function
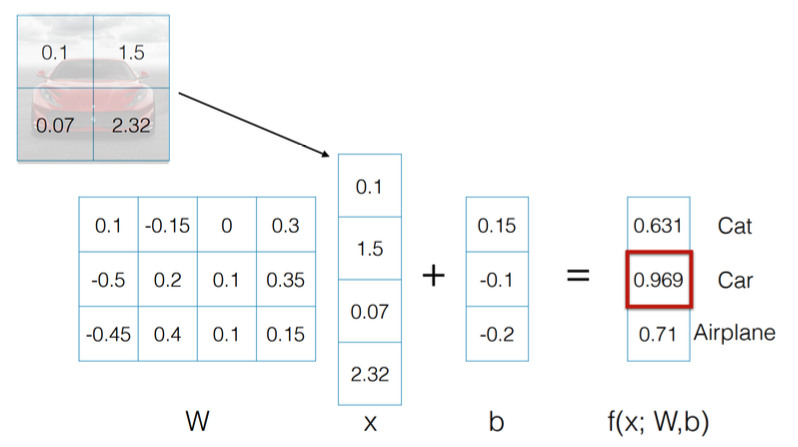
간단하게 예시를 보기 위해, 이미지의 크기를 4 x 4 크기로, 분류하려는 클래스의 수를 3개로 줄여보자.
잘 학습이 된 모델에 주어진 이미지를 데이터로 넣으면 이렇게 연산 결과 f(x; W,b) 로 나온다.
Cat, Car, Airplane 분류 모델의 출력 결과 이 이미지가 자동차일 확률이 96.9%로 제일 높으니 자동차로 분류한다.

이 모델에 고양이 이미지와 비행기를 넣었을 때도 잘 분류하는 것을 보면, W, b 가 적절히 잘 세팅된 것 같다.

하지만 이렇게 W, b 값이 바뀌면 모든 이미지를 고양이로 분류하는 모델이 나오기도 한다.
즉, 모델의 성능을 W 가 결정하는 것은 자명한데, 어떻게 해야 '좋은' W 를 찾을 수 있을까?
컴퓨터에게 '좋은' W 를 찾도록 시키려면 '좋은 W' 를 수치화해서 기준을 세워주어야 한다.
그리고 그 기준으로 지금까지 Loss 를 활용하였다.

지도학습 방식으로 이미지와 분류 결과를 알려주고, W1, W2 값을 각각 세팅한 모델에 이미지를 넣고 계산한 결과가 <0, 1, 0> 이라는 결과값에 제일 가까운 W1 을 더 좋은 W로 선정하는 것이다.
이때 '결과값에 더 가깝다' 를 판별하는 방법(=Loss를 계산하는 방법)으로 크게 L1 Loss, L2 Loss, Cross-Entropy 가 있다.
L1 Loss

L1 Loss 는 각 성분 차이의 절댓값을 모두 더한 것이고, loss function 은 오른쪽 그림과 같은 형태의 그래프를 그린다.
오차가 발생했으면 딱 그 오차가 발생한 만큼만 Loss 가 증가한다. (선형적 증가)
L2 Loss

L2 Loss 는 각 성분 차이의 제곱을 모두 더한 것이다.
f(x; W, b) 와 y 벡터의 L2 Norm 을 모두 더해서 평균을 낸 것이라고도 할 수 있으며,
Loss function 은 오른쪽 그림과 같이 2차함수 형태의 그래프가 그려진다.
오차가 발생하면, 오차가 발생한 것의 제곱만큼 Loss 가 증가하므로
오차가 작을 때는 loss 페널티가 적었다가, 오차가 증가하면 기하급수적으로 Loss 페널티가 증가한다.
Cross-Entroypy

Cross-Entropy 는 위 그림과 같이 log 를 사용하여 Loss 를 계산한다.
교수님께서 자세한 내용은 뒤에서 설명하신다고 하고 넘어가셨다.
(CNN의 4가지 주요 레이어 중 Softmax 레이어에서 활용하는 듯 하다.)

그래서 이렇게 그래프를 합쳐보면 Loss 함수를 어떤 것을 사용하는지에 따라 오차에 따른 페널티 정도가 달라진다.

따라서 위 그림과 같이 오차가 미세하게 다르게 나와서 W1, W2 중 어떤 것을 선택해야 할 지 미묘할 때가 있다.

그런 상황에서는 Loss 함수를 어떤 것을 사용하는지에 따라 W1, W2 중 어떤 것이 더 좋은 지 선택이 갈릴 수 있다.
따라서 Loss Function 을 어떤 것으로 선택할지 결정하는 것도 중요하다.
Loss Function 을 어떤 것으로 사용하는지는 우리가 정해주어야 한다. (즉, 하이퍼파라미터)
어떤 함수를 사용할 지는 데이터의 특성과 환경을 고려하여 선택한다고 한다.
Regularization
Loss와 관련하여 Overfitting 과 Underfitting 이라는 중요한 개념이 있다.

우리는 지금까지 제일 작은 Loss 가 최적이라고 생각하면서 Loss 를 줄이기 위해 노력하였다.
그런데 과연 Loss 가 무조건 작을 수록 좋을까?
위 그림을 보면 왼쪽 그래프는 함수가 데이터의 경향성을 잘 나타내지 못하고 있다.
딱 봐도 Loss 가 매우 큰 상태일 것이다.
가운데 그래프는 데이터의 경향성을 어느 정도 적절히 잘 나타내고 있다.
Loss 가 어느 정도 존재하지만 그렇게 크지는 않을 것으로 예상된다.
오른쪽 그래프는 데이터들을 모두 하나의 선으로 연결하다시피 경향성을 나타내고 있다.
이런 그래프로 새로운 점의 위치를 예측하면 부정확하게 나올 것이다.
하지만 Loss 는 세 그래프 중에 제일 작다.
그래서 이런 경우에는 학습 과정의 Loss 는 매우 작지만, 테스트 셋에 대한 Loss 는 매우 크게 나온다.
이렇게 데이터의 복잡도에 비해 모델의 복잡도가 너무 높으면 (다항식으로 치면 차수가 너무 높은 경우) 위 오른쪽 그래프와 같이 Overfitting (과적합) 문제가 발생할 수 있다.
반면 데이터의 복잡도에 비해 (데이터가 2차 곡선의 형태를 그리고 있는 상황) 모델의 복잡도가 너무 낮으면 (1차 함수 모델 사용) Underfitting 문제가 발생한다.
그래서 그 중간의 적절한 지점을 잘 조율해서 모델의 복잡도를 결정해야 한다.
데이터에도 분명 오차는 존재하기 때문에, 어느 정도의 오차는 허용해주어야 한다.
(outlier 데이터나 노이즈가 끼는 경우, 설문 조사 등에서 실수로 잘못 대답하는 등)

이런 과적합 문제를 방지하기 위해서 모델을 어느정도 부드럽게 바꿔주는 기법도 존재한다.
경험적으로도 데이터의 경향성을 설명할 때는 최대한 단순하고 간단하게 설명해야 그 특성과 잘 맞아떨어진다.
머신러닝에서 모델의 과적합을 방지하기 위해서 사용하는 기법을 가리켜 Regularization (정규화) 라고 한다.
정규화는 모델이 데이터에 너무 잘 들어맞지 않도록 방해하는 역할을 한다.

간단하게 아이디어를 보면 기존의 Loss 함수와 달리 Data Loss 만 사용하는 것이 아니라 정규화 함수를 더해서 로스 함수를 구성한다.
이 과정에서 예측값의 오차를 너무 최소로 구하지 말라고 λ 라는 가중치를 곱해준다.
람다는 Data loss 와 Regularization 사이의 비중을 조절하는 역할을 한다.
Regularization 함수는 loss 를 정확하게 구하는 것을 방해하여 모델이 더 단순하게 나오도록 만든다.
예를 들어 L1 norm 을 사용한 R(W)의 경우, 크기가 작은 W 계수들을 0으로 보내서 모델을 간단하게 보낸다.
(통계학에서는 '라소' 라고 부른다.)
그 밖에도 L2 정규화를 사용하는 Ridge 와 같은 방법도 있다.
Optimization
머신러닝에서 제일 중요한 것은 결국 제일 작은 Loss를 만드는 W를 찾는 것이다.
그리고 이런 W를 찾는 과정을 의인화해서 '학습한다' 고 표현한다.
Optimization 방법은 크게 3가지가 있다.
Random Search

W를 랜덤으로 생성하고 Loss 를 계산하는 것을 반복한다.
반복하면서 지금까지 구한 Loss 중에 제일 작은 값이 나왔던 W를 선택한다.
마치 브루트포스같이 단순 무식한 방법인데, 이 방법의 단점은 너무 느리다는 것이다.
Loss 값이 어느 범위에서 존재하는지 알고 있다면 랜덤값의 생성 범위를 제한하여 단점을 조금 보완할 수 있지만, 그럼에도 너무 느리다.
Analytic Solution

두 번째 방법은 GD에서 처음 설명했던 대로, Loss 함수를 미분하고, 그 결과값을 0으로 둔 뒤에 방정식을 푸는 것이다.
리니어한 경우(Wx + b)와 같이 W가 단순한 경우에는 이 방법을 적용할 수 있지만, 함수가 복잡해지면 이 방법을 적용할 수 없다.
함수식에 log, cos 과 같은 값이 들어가면 0 에서의 값을 구할 수 없는 경우가 존재하기 때문이다.
Numerical Solution

그래서 등장한 것이 경사하강법이다.
미분값이 0이 되는 지점을 향해 계속 이동하면서 Loss 가 거의 줄어들지 않는 지점에서 맘춰 그때의 W를 취하는 방법이다.
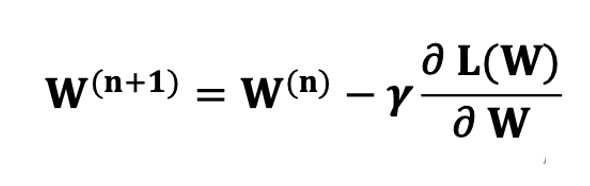
경사하강법을 이용하면 W는 기울기의 반대 방향으로 이동하게 되는데, 어느정도 이동할 지 learning rate 를 통해 조절해줄 수 있었으며, 이 값은 우리가 직접 결정해야 하는 하이퍼파라미터였다.
다만 이 방법도 local minima 문제, 미분값이 너무 커서 컴퓨터가 다룰 수 있는 범위를 벗어나면 무한대로 가버리는 경우, 미분값이 너무 작아서 컴퓨터가 다룰 수 있는 정확도를 벗어나면 그냥 0이 되어버리는 문제, 컴퓨터를 사용하다보니 오차에 의해 미분값이 부정확하게 나오는 문제 등이 존재한다.
지금까지 딥러닝을 정리하기에 앞서 Loss, Regularization, Optimization 에 대해 간단하게 정리해보았다.
다음 글부터는 본격적으로 딥러닝의 기본 아이디어와 개념들을 정리하고, 대표적인 딥러닝 예시로 CNN 을 정리해본다.