지난 글에서는 단점일도 FPU 명령어 사용 예제를 살펴보았다.
이번 글에서는 배정밀도 FPU 명령어 사용 예제를 살펴보고자 한다.
Double-Precision Floating Point Computation
배정밀도 연산자는 기존 연산자 끝에 s 대신 d 가 붙는 것만 다르다.
faddd
fsubd
fmuld
fsmuld (single * single = double, 피연산자는 single 이다.)
fdivd
fsqrtd
double 연산자의 피연산자 레지스터는 반드시 짝수번째 레지스터가 들어가야 한다.
%fi 와 %f(i+1) 의 2개 레지스터로 하나의 소수를 표현하기 때문이다.
연산 결과도 double 로 나오므로 짝수번째 레지스터를 사용한다.
데이터 형변환 명령어도 종류가 늘어났다.
fitod = int to double
fdtoi = double to i
fdtos = double to single
fstod = single to double
double <-> single 간 변환 명령어가 추가되었다.
추가적으로 printf 함수로 실수를 출력할 때는 (즉, "%.1f" 와 같은 방식으로 출력할 때) 반드시 인자로 double 형 인자를 넘겨야만 한다.
저렇게 작성하면 %o0 위치에 포맷팅 문자열을, %o1%o2 위치에 double 실수를 전달하면된다.
그런데 double 형 실수는 항상 짝수번째 레지스터에 들어있으므로, 저 위치에 넣으려면 4byte 씩 끊아서 넣어줘야만 한다.
예제1
간단한 출력 예제를 하나 살펴보자.
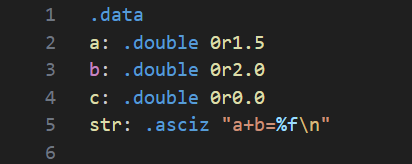
정적 공간에 선언하는 것은 .single 대신 .double 을 사용하는 것만 다르다.

메모리에서 데이터를 읽어올 때, double 단위로 읽어오므로 ldd 명령어를 대신 사용하였다.
읽어온 데이터는 짝수번째 fpu register 에 저장하였고, f4f5 에는 f0f1 + f2f3 의 값을 저장한다.
이 값을 메모리에 있는 변수 c 에 저장한다.

다시 c에 있는 값을 읽어와 짝수번째 o 레지스터에 저장한다.
문자열을 달아주고, o2o3 에 저장된 실수 데이터를 o1o2 에 저장하도록 위치를 옮겨준다.
그 뒤 printf 함수를 출력하면 끝이다.

실행결과는 위와 같다.
예제 2
앞에서 했던 원소 9개짜리 두 벡터를 내적하는 연산을 double 에서 해보자.
기존 코드를 재사용하겠다.

데이터 전역 선언부를 double 로 바꿔주었다.

반복문 내에서 곱셈을 계산하는 코드도 double 연산에 맞게 바꿔준다.
ld 대신 ldd 로 읽어오고, fmuls 대신 fmuld를, fadds 대신 faddd 를 사용한다.

반복문을 나온 결과도 std 로 저장해준다.
한번 결과값을 출력해보자.

Bus Error 가 발생했다....
이것도 한 30분동안 이것 저것 디버깅해봤는데, 내가 찾은 원인은 메모리 주소 정렬 문제였다.
double 형은 8byte 인데, SPARC는 4byte 시스템이라 메모리를 할당할 때 시작 위치를 기본적으로 4의 배수부터 시작해서 담아주는 것 같다.
그래서 .align 8 을 먼저 하고나서 데이터를 저장해야 했다.

이것 때문에 강의록 코드를 그대로 작성하였음에도 오류가 발생했었다.
이렇게 사진처럼 정렬을 한 뒤 실행하면 에러가 발생하지 않는다.
이제 디버거로 결과값을 찍어보자.
근데 계속 문제가 발생했다.
출력이 되기는 하는데, 값이 이상하게 나온다.
그래서 이 예제는 그냥 포기한다.
포기하게된 이유를 설명하고자 한다.

이렇게 작성했는데, 뭔가 값이 잘 나오기는 하나, 예제와는 다른 값이 나온다.
강의록 코드를 직접 입력해봤는데도, 기존 단정밀도 내적 예제에서 사이즈만 double 로 바뀌었음에도 값이 이상하게 나온다.
gdb로 찍어보니 gdb는 단정밀도 기준으로 계산해서 보여주는 것 같았고, printf 를 해보니 잘 되었는데, 이상하게 printf 함수를 호출하고나면 f 레지스터의 값이 이상하게 바뀌는 건지 printf 함수 호출을 중간에 넣는지 안 넣는지 차이만으로 실행결과 값이 바뀌면서 이상한 상황이 펼쳐졌다.
이건 디버깅을 할 시간에 다른 파트를 공부하는게 더 낫겠다는 생각이 들어서 그냥 포기하기로 했다.
.data
.align 8
result: .double 0r0.0
a: .double 0r1.0, 0r1.5, 0r-1.5, 0r1.0, 0r-1.0, 0r1.0, 0r3.2E1, 0r2.1E2, 0r1.3E-3
b: .double 0r5.0, 0r4.0, 0r10.1, 0r0.25, 0r3.0, 0r5.0, 0r-2.5, 0r3.6, 0r9.0
str: .asciz "result: %f\n"
test_str: .asciz "k: %d, a[k]: %f, b[k]: %f\n"
test_str2: .asciz "k: %d, fmuld: %f\n"
.text
.global main
main:
save %sp, 104, %sp
! %f0f1 = f1
! %l0 = i, %l1 = k
! k = 0
mov %g0, %l1
! f0f1 = result;
set result, %o0
ldd [%o0], %f0
! for loop
mov 9, %l0 ! i = 9
loop:
cmp %l0, 0
ble break
nop
! address calculate
sll %l1, 3, %l3 ! l3 = k * 8
set a, %l4
set b, %l5
ldd [%l4 + %l3], %f2 ! f2f3 = a[k]
ldd [%l5 + %l3], %f4 ! f4f5 = b[k]
! set test_str, %o0
! mov %l1, %o1
! std %f2, [%fp-8]
! ldd [%fp-8], %o2
! std %f4, [%fp-16]
! ldd [%fp-16], %o4
! call printf
! nop
ldd [%l4 + %l3], %f2
ldd [%l5 + %l3], %f4
fmuld %f2, %f4, %f6 ! f6f7 = f2f3 * f4f5 = a[k] * b[k]
faddd %f0, %f6, %f0 ! f0f1 += f6f7
! set test_str2, %o0
! mov %l1, %o1
! std %f6, [%fp-8]
! ldd [%fp-8], %o2
! call printf
! nop
dec %l0 ! i--
ba loop
inc %l1 ! k++, delay slot
break:
fsqrtd %f6, %f8 ! f8f9 = sqrt(f6f7)
set result, %o0
std %f8, [%o0] ! [%o0] <- f6f7
test:
! set str, %o0
! set result, %o4
! ldd [%o4], %o2
! mov %o2, %o1
! mov %o3, %o2
! call printf
! nop
mov 1, %g1
ta 0
위 코드는 내가 이것 저것 출력해보면서 삽질했던 코드이다.
예상 기댓값은 기존 단정밀도 예제에서와 같이 25.xxx 값이 출력되어야 한다.

내가 실행했을 때 출력값이다.

반복하는 도중, 중간 곱셈 결과 값을 출력하는 printf 함수만을 추가했다.
각 곱셈 결과는 제대로 구했으나 이를 더하는 과정에 문제가 있는듯 하였고, 출력결과는 보다시피 출력 함수만 추가했을 뿐인데 0이 되어버렸다.
근데 성공했다!!!!

나중에 서브루틴 호출에서 정리하겠지만, 서브루틴을 호출하면 %f0 으로 직접 return value 를 전달할 수 있다.
그래서 내가 예측한 것은, printf 함수를 호출할 때마다 %f0 의 값이 (사실 %f0 값만 비정상적으로 바뀌는 건가 싶어서 %f10 에 저장해봤는데도 문제가 그대로 발생했다.), 정확히는 fpu 레지스터 자체가 그냥 초기화 되는 게 아닐까 라는 생각을 했다.
근데 일단 fmul, fadd 도 모두 잘 되니까, 그 중간 결과값을 매번 result 메모리 변수에 갱신해주었다.
마지막에는 result 메모리 값을 읽어와서 출력하도록 했더니 성공했다.
근데 진짜 이렇게까지 해야하나..?
이거 하나에 시험 당일 3시간을 투자한 나는 바보일지도...
실수를 매개변수로 함수 호출하기
이제 실수형 인자를 매개변수로 함수를 호출하는 방법에 대해 생각해보자.
함수에 매개변수를 넘길 때는 실수라고 하더라도 o 레지스터를 통해 넘겨야 한다.
그런데 fpu 레지스터에 있는 값을 직접 o 레지스터로 넘기는 것은 불가능하다.
그래서 이럴 때는 반드시 메모리를 경유해서 o 레지스터로 값을 보내야 한다.
반대로 return 값을 fpu에 보내고 싶을 때도 기본적으로는 i 레지스터에 반환값을 넣어서 반환한 뒤, 그 값을 부모함수의 o 레지스터로 받아서 메모리를 경유해 f 레지스터로 보내면 된다.
그런데 반환 값의 경우 한가지 예외가 있는데, return 값을 %f0 에 직접 다이렉트로 설정해줄 수 있다.
(내가 위 예제에서 삽질한 이유가 이것과도 관련 있지 않을까..)
이는 SPARC 가 이렇게 정해둔, conventional 한 것이다.
그리고 아주아주 중요한 점
SPARC 에서 integer register와 달리 %f 레지스터에 대해서는 Register Window 가 없다.
따라서 서브루틴을 호출하기 전에, 나중에 사용할 %f 레지스터의 값을 항상 메모리에 백업해두어야 한다.
실수 매개변수 예제 1
void main() {
static float a=3.0, b=2.5, c=0.0;
c = single_add(a, b);
}
float single_add(float a, float b) {
return a+b;
}
단순히 두 실수를 인자로 받아서 더한 뒤 돌려주는 예제이다.
스택 프레임 사이즈부터 계산하자.
main 의 스택 프레임 사이즈는 함수를 호출하고 있으나 따로 지역변수를 갖고 있지 않고, 6개를 넘는 매개변수도 없으니
기본 64
함수호출 4 + 24
총 92 byte 가 필요하며, 이를 8의 배수로 맞춰주면 96 byte 의 공간이 필요하다.
그런데 실수 값을 함수 인자로 넘길 때 메모리를 경유해야 하므로, 혹시 필요하다면 이를 고려하여 나중에 사이즈를 늘려주도록 하자.
single_add 함수는 실수를 2개 인자로 받는다.
이 값을 다시 메모리를 경유해 fpu -register 에 저장한 뒤, 덧셈을 해서 반환한다.
메모리를 경유할 때 4byte 의 공간이 필요하므로
기본 64
지역변수 4
다른 함수 호출 및 추가 매개변수 x
따라서 64 + 4 = 68 을 8의 배수로 맞춘 72byte 만큼을 할당해주도록 하였다.

전체코드는 이렇게 간단하게 사용할 수 있다.
정적 메모리에 값을 할당해두었기 때문에, main 함수에서는 스택 메모리가 아니라 data section 메모리에서 값을 가져와 레지스터에 넣으면 되니 96바이트만 있으면 충분하다.
single_add 함수에서는 사실 4byte만 있어도 수행 가능하지만, 코드 가독성을 위해 8byte의 지역변수를 선언해 위와 같이 fpu register 로 전달받은 값을 옮겨 연산 후, %f0에 결과를 저장해 반환하였다.

실수 매개변수 예제 2
이번엔 single 이 아니라 double 형을 받아보자.
같은 C 코드에서 모든 double 을 single 로 바꾼 예제이다.
void main() {
static double a=3.0, b=2.5, c=0.0;
c = double_add(a, b);
}
double double_add(double a, double b) {
return a+b;
}
double 의 경우 레지스터를 2개씩 사용하므로 위 함수에서는 매개변수로 4개의 o-register 를 사용한다.
다행히 그 갯수가 6개를 넘지 않으므로, 스택 프레임 사이즈는 예제 1과 같다.
double_add 함수의 경우, 전에는 4byte 2개에 대해 8byte로 선언했지만, 이젠 8byte 1개에 대해 8byte 의 지역변수를 선언한 것으로 생각하고 코드를 작성하였다.

이렇게 작성하였다.
ld st 명령어를 모두 ldd std 로 바꿔주고 single 도 double 로 바꿔주었다.
double_add 함수 내에서는 %fp-8 하나를 이용해 f- 레지스터로 값을 넘겨주었다.
실행결과는 아래와 같이 잘 나온다.

double 의 경우, gdb로 찍어보면 single 기준으로 보여주기 때문에 이렇게 printf 함수를 이용해 출력하였다.
강의록에선 double_add 함수의 스택프레임 사이즈를 92 + 8 = 100 의 8의 배수인 104로 잡았는데 왜 굳이 그렇게 잡았는지 모르겠다.
위에서 했던대로 72byte 만 잡아도 충분하다.
실수 포인터 매개변수 예제
이렇게 매번 f-register 의 값을 o-register 로 메모리를 경유해 옮긴 다음 계산하는 것은 너무 불편하다.
그냥 주소값을 넘겨서 call by reference로 함수를 사용해보자.
void main() {
static double a=3.0, b=2.5, c=0.0;
c = double_add(&a, &b, &c);
}
void double_add(double* a, double* b, double* c) {
*c = *a + *b
}
포인터를 사용하는 경우, double_add 에서 메모리를 경유하는 행위가 없으므로 double_add 의 스택프레임 사이즈는 64byte 만 선언해도 된다.

이렇게 작성할 수 있다.

실행결과도 동일하게 나온다.
이것으로 2023년 2학기 SPARC 어셈블리 언어 전공 수업에 대한 모든 내용을 정리하였다.
다음 글에서는 기말고사 대비로 용어들과 헷갈릴만한 수업 내용, 과제 내용을 다시 정리해보고자 한다.
'CS > 어셈블리' 카테고리의 다른 글
| [SPARC] 40. 기말고사 대비 정리 (0) | 2023.12.08 |
|---|---|
| [SPARC] 38. FPU Instructions 사용 예제 (단정밀도) (0) | 2023.12.08 |
| [SPARC] 37. 실수 계산 & FPU & FPU Instructions (0) | 2023.12.07 |
| [SPARC] 36. Floating Point (0) | 2023.12.07 |
| [SPARC] 35. Bubble Sort 구현 (2) | 2023.12.07 |