BNF 따라가기
BNF 문법은 나중에 YACC 라는 프로그램에 들어가 Parser 를 만든다. (야크는 파서 제너레이터이다.)
이번 글에서는 BNF 문법을 보고 주어진 C 코드를 파서가 어떻게 파싱하게 될 지 파싱트리를 그리는 과정을 직접해보고자 한다.
이 과정을 수행하려면 우선 lexical analyzer 에 의해 소스코드가 각각의 렉시컬 토큰 조각들로 구분이 되어있어야 한다.
소스코드에서 렉시컬 토큰을 추출하는 과정은 아래의 lex 코드를 참고하자.
// 강의록에서 ANSI C grammer, Lex specification.pdf 에 있는 코드입니다.
D [0-9]
L [a-zA-Z_]
H [a-fA-F0-9]
E [Ee][+-]?{D}+
FS (f|F|l|L)
IS (u|U|l|L)*
%{
#include <stdio.h>
#include "y.tab.h"
void count();
%}
%%
"/*" { comment(); }
"auto" { count(); return(AUTO); }
"break" { count(); return(BREAK); }
"case" { count(); return(CASE); }
"char" { count(); return(CHAR); }
"const" { count(); return(CONST); }
"continue" { count(); return(CONTINUE); }
"default" { count(); return(DEFAULT); }
"do" { count(); return(DO); }
"double" { count(); return(DOUBLE); }
"else" { count(); return(ELSE); }
"enum" { count(); return(ENUM); }
"extern" { count(); return(EXTERN); }
"float" { count(); return(FLOAT); }
"for" { count(); return(FOR); }
"goto" { count(); return(GOTO); }
"if" { count(); return(IF); }
"int" { count(); return(INT); }
"long" { count(); return(LONG); }
"register" { count(); return(REGISTER); }
"return" { count(); return(RETURN); }
"short" { count(); return(SHORT); }
"signed" { count(); return(SIGNED); }
"sizeof" { count(); return(SIZEOF); }
"static" { count(); return(STATIC); }
"struct" { count(); return(STRUCT); }
"switch" { count(); return(SWITCH); }
"typedef" { count(); return(TYPEDEF); }
"union" { count(); return(UNION); }
"unsigned" { count(); return(UNSIGNED); }
"void" { count(); return(VOID); }
"volatile" { count(); return(VOLATILE); }
"while" { count(); return(WHILE); }
{L}({L}|{D})* { count(); return(check_type()); }
0[xX]{H}+{IS}? { count(); return(CONSTANT); }
0{D}+{IS}? { count(); return(CONSTANT); }
{D}+{IS}? { count(); return(CONSTANT); }
L?'(\\.|[^\\'])+' { count(); return(CONSTANT); }
{D}+{E}{FS}? { count(); return(CONSTANT); }
{D}*"."{D}+({E})?{FS}? { count(); return(CONSTANT); }
{D}+"."{D}*({E})?{FS}? { count(); return(CONSTANT); }
L?\"(\\.|[^\\"])*\" { count(); return(STRING_LITERAL); }
"..." { count(); return(ELLIPSIS); }
">>=" { count(); return(RIGHT_ASSIGN); }
"<<=" { count(); return(LEFT_ASSIGN); }
"+=" { count(); return(ADD_ASSIGN); }
"-=" { count(); return(SUB_ASSIGN); }
"*=" { count(); return(MUL_ASSIGN); }
"/=" { count(); return(DIV_ASSIGN); }
"%=" { count(); return(MOD_ASSIGN); }
"&=" { count(); return(AND_ASSIGN); }
"^=" { count(); return(XOR_ASSIGN); }
"|=" { count(); return(OR_ASSIGN); }
">>" { count(); return(RIGHT_OP); }
"<<" { count(); return(LEFT_OP); }
"++" { count(); return(INC_OP); }
"--" { count(); return(DEC_OP); }
"->" { count(); return(PTR_OP); }
"&&" { count(); return(AND_OP); }
"||" { count(); return(OR_OP); }
"<=" { count(); return(LE_OP); }
">=" { count(); return(GE_OP); }
"==" { count(); return(EQ_OP); }
"!=" { count(); return(NE_OP); }
";" { count(); return(';'); }
("{"|"<%") { count(); return('{'); }
("}"|"%>") { count(); return('}'); }
"," { count(); return(','); }
":" { count(); return(':'); }
"=" { count(); return('='); }
"(" { count(); return('('); }
")" { count(); return(')'); }
("["|"<:") { count(); return('['); }
("]"|":>") { count(); return(']'); }
"." { count(); return('.'); }
"&" { count(); return('&'); }
"!" { count(); return('!'); }
"~" { count(); return('~'); }
"-" { count(); return('-'); }
"+" { count(); return('+'); }
"*" { count(); return('*'); }
"/" { count(); return('/'); }
"%" { count(); return('%'); }
"<" { count(); return('<'); }
">" { count(); return('>'); }
"^" { count(); return('^'); }
"|" { count(); return('|'); }
"?" { count(); return('?'); }
[ \t\v\n\f] { count(); }
. { /* ignore bad characters */ }
%%
yywrap()
{
return(1);
}
comment()
{
char c, c1;
loop:
while ((c = input()) != '*' && c != 0)
putchar(c);
if ((c1 = input()) != '/' && c != 0)
{
unput(c1);
goto loop;
}
if (c != 0)
putchar(c1);
}
int column = 0;
void count()
{
int i;
for (i = 0; yytext[i] != '\0'; i++)
if (yytext[i] == '\n')
column = 0;
else if (yytext[i] == '\t')
column += 8 - (column % 8);
else
column++;
ECHO;
}
int check_type()
{
/*
* pseudo code --- this is what it should check
*
* if (yytext == type_name)
* return(TYPE_NAME);
*
* return(IDENTIFIER);
*/
/*
* it actually will only return IDENTIFIER
*/
return(IDENTIFIER);
}
이제 BNF 문법을 보면서 추출한 렉시컬 토큰들로 파싱트리를 만들어보자.
%token IDENTIFIER CONSTANT STRING_LITERAL SIZEOF
%token PTR_OP INC_OP DEC_OP LEFT_OP RIGHT_OP LE_OP GE_OP EQ_OP NE_OP
%token AND_OP OR_OP MUL_ASSIGN DIV_ASSIGN MOD_ASSIGN ADD_ASSIGN
%token SUB_ASSIGN LEFT_ASSIGN RIGHT_ASSIGN AND_ASSIGN
%token XOR_ASSIGN OR_ASSIGN TYPE_NAME
%token TYPEDEF EXTERN STATIC AUTO REGISTER
%token CHAR SHORT INT LONG SIGNED UNSIGNED FLOAT DOUBLE CONST VOLATILE VOID
%token STRUCT UNION ENUM ELLIPSIS
%token CASE DEFAULT IF ELSE SWITCH WHILE DO FOR GOTO CONTINUE BREAK RETURN
상단에는 사용하는 Lexical 토큰들을 정의해두고 있다.
예를 들어 제일 처음에 나오는 IDENTIFIER 라는 토큰은 lex 코드를 보면 마지막에
int check_type()
{
/*
* pseudo code --- this is what it should check
*
* if (yytext == type_name)
* return(TYPE_NAME);
*
* return(IDENTIFIER);
*/
/*
* it actually will only return IDENTIFIER
*/
return(IDENTIFIER);
}
check_type() 함수에 의해 생성된다.
(return 문을 통해 반환된 내용물, 즉, 토큰은 yacc 로 넘어간다)
check_type() 함수는 언제 호출되었던가?
{L}({L}|{D})* { count(); return(check_type()); }
이 부분에서 호출된다.
처음에 문자 (L) 가 오고, 그 뒤에 문자 또는 숫자가 0번 이상 반복되면, 이를 식별자 (변수명, 함수이름 등) 로 본다는 것이다.
%start translation_unit
BNF의 시작은 이렇게 정의한다.
translation_unit 에서부터 시작한다.
이 말은 이 non-terminal 이 파싱트리의 루트가 된다는 의미이다.
탑-다운으로 파고가면 translation_unit 이 어떻게 확장되는지 그 정의를 보면 된다.

translation_unit 은 external_declaration 또는 translation_unit 오른쪽에 external_declaration 이 오는 형태라고 한다.
이 말은 다시말해, external_declaration 이 공백을 기준으로 구분되어 1개 이상 나열된 형태를 말한다.
재귀문이 왼쪽에 있으므로 left associativity 하고, 해석할 때는 왼쪽부터 해석하게 된다.
external_declaration 은 어떻게 확장될까?

function_definition 또는 declaration 으로 확장된다.
function_definition 은 아래와 같다.

뭔가 굉장히 복잡하다.
이제 탑-다운 방식으로 따라가는 건 힘들어 보인다.
따라서 바텀-업 방식으로 BNF 문법을 따라가보자.
바텀 업 방식에서 가장 기본이 되는 것은 primary_expression 이다.

IDENTIFIER, CONSTANT, STRING_LITERAL 셋 모두 렉시컬 토큰, 즉 Terminal 이다.
IDENTIFIER, CONSTANT, STRING_LITERAL 토큰이 단독으로 들어오면, 이들은 모두 primary_expression 으로 release 된다.
또는 expression 을 괄호로 감싼 형태도 primary_expression 이라고 한다.
괄호를 따옴표로 감싼 이유는 저 각각의 괄호도 토큰이기 때문이다.
"(" { count(); return('('); }
")" { count(); return(')'); }
lex 코드를 보면 이런 부분이 있었다.
문자 (, ) 를 만나면 이 자체를 토큰으로 반환하도록 하고 있다.
primary_expression 은 아래와 같이 postfix_expression 으로 release 될 수 있다.

말 그대로 뒤에 뭐가 붙은 expression 이다.
자세히보면 저 문법은 결국 primary_expression 뒤에 무언가 온다는 것을 의미한다.
[ ] 가 오거나 (배열)
( ) 가 오거나 (매개변수 없는 함수 호출)
( 매개변수 리스트) 가 오거나 (매개변수 있는 함수 호출)
.IDENTIFIER 가 오거나 (구조체 멤버 변수 접근)
포인터 기호 뒤에 IDENTIFIER 가 오거나 ( -> 연산자 뒤에 멤버 변수가 오는 것)
INC_OP 또는 DEC_OP 가 올 수 있다. (a++, a-- 와 같은 것이다. INC_OP, DEC_OP 도 모두 토큰이다.)
다시 post_expression 은 unary_expression 으로 releaes 된다.

이 말은 결국 postfix_expression 앞에 ++, -- 같은 연산자가 오는 상황을 말한다.
프로그램은 결국 리프에 가까울 수록 실행의 우선순위가 높다.
따라서 ++a-- 라는 코드는 먼저 a-- 를 실행하고, 그 결과에 대해 ++a 를 실행한다는 것을 알 수 있다.
a-- 는 postfix_expression 이라서 리프에 더 가까운 반면, ++a 는 unary_expression 리프에서 더 멀기 때문이다.
이후로는 이런식으로 트리가 쭉쭉 그려지다가 결국 start 에 해당하는 translation_unit 을 만나면 멈출 것이다.
Example
한번 말이 나온김에 ++a-- 라는 코드의 파싱트리를 그려보자.

++a--; 라는 문장은 하나의 statement 이므로, statement_list 까지밖에 확장할 수 없다.
statement_list 는 start 위치에 있는 논 터미널이 아니다.
따라서 이렇게 한 문장만 쓰면 파서가 에러를 낼 것이다.
원래 이 문장은 결국 함수 안에 있어야 하므로, { } 로 감싼 compound_statement 로 확장되고, 이게 다시 function_definition 으로 확장된 뒤, external_declaration, translation_unit 순으로 확장되어야 한다.
이렇게까지 확장되면 더 이상 문법적으로는 문제가 없는 코드가 된다.
하지만 a 라는 변수가 선언된 적이 없으므로 문맥상 문제가 있어, symantic analyzer 가 이를 잡아 다시 에러를 내려고 할 것이다.
BNF 유추 예제
지금까지 BNF 와 C언어 코드를 보고 파싱트리를 작성하는 과정을 따라가보았다.
BNF, C코드, 파싱트리 3가지는 항상 같이 나오며 상호 보완한다.
만약 C코드와 파싱트리만 주어진다면 이를 보고 BNF 를 유추할 수 있고,
BNF 와 파싱트리만 주어진다면 이를 보고 C 코드를 유추할 수 있다.
한번 어떤 코드에 대한 AST (Abstract Syntax Tree) 가 다음과 같이 있고, 그에 대한 Parsing Tree 가 아래와 같이 있다고 해보자.


이를 보고 거꾸로 BNF 문법을 유추해보자.
먼저 a, b, c, d, e, f 라는 변수명은 모두 <primary> 라는 논터미널로 release 된다.
그리고 그 이외에 primary 로 바뀌는 경우는 보이지 않는다.
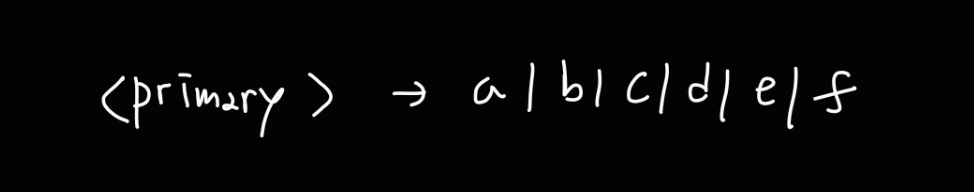
이를 다음과 같이 표현할 수 있다.
primary 위를 보면 primary 가 <term> 으로 release 되는 것을 볼 수 있다.
그런데 term 에서 거꾸로 봤을 때, term 은 단수히 primary 로만 확장되지 않는다.
term / primary 또는 term * primary 로도 확장된다.

이를 이렇게 작성할 수 있다.
EBNF 를 사용한다면 더 간단하게 표현할 수 있을 것 같지만, 일단 BNF 로 작성하였다.
다시 term 에 대해서 보면, term 은 expression 으로 reduce 된다.
그런데 expression 입장에서보면 term 하나로만 extends 되는 것이 아니라 expression +/- term 으로 extend 되기도 한다.

이를 이렇게 BNF로 작성할 수 있다.
그리고 expression 이 파싱트리의 루트이므로, extends 되는 시작점, 스타팅 논 터미널이라고 볼 수 있다.
C언어의 declaration 구문 파싱 예제
typedef unsigned long int ul_int;
위 구문을 파싱해서 파싱트리를 그려보자.
우선 위 코드에 대해 laxical analyzer가 lexical token 들을 다음과 같이 돌려준다.

이제 이 토큰들을 reduce 해서 파싱트리를 만들어보자.

각각의 타입들을 type_specifier로 reduce 했다.
그 이후에 specifier_qualifier_list 로 reduce를 시켜봤는데, type_name 까지 올라간 뒤로 막혀버리고 말았다.
이럴 때는 다시 내려와서 다른 reduce 방법이 있는지 찾아보면 된다.
bottom-up 방식으로 파싱트리를 만들땐 이게 힘들다 ㅋㅋ

BNF 를 보니 declaration_specifier 라는 것도 있었다.
이걸로 확장하면, typedef 의 storage_class_specifier 와도 연결 지을 수 있을 것 같다.
근데 declaration 과 관련된 BNF 를 찾다보니 파싱트리에서 IDENTIFIER 에 대한 reduce 도 잘못되었음을 발견했다.

이 BNF를 사용해서 확장하자.

최종적으로 위와 같이 파싱트리가 그려진다.
또 다른 예제를 보자.
ul_int my_ul_int;
위에서 정의한 사용자 정의 타입에 대한 파싱을 해보자.
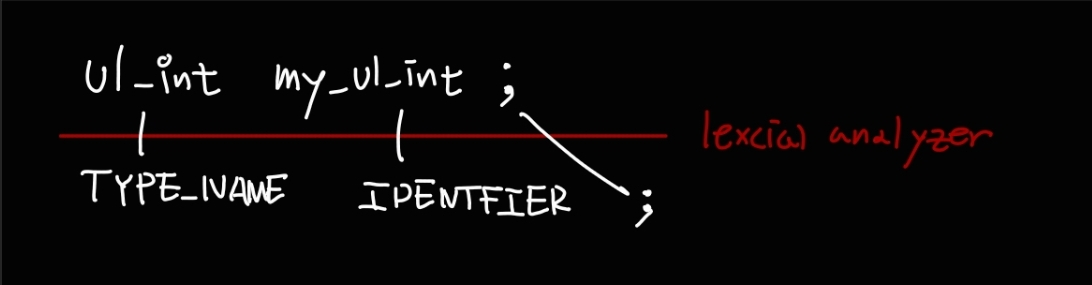
사용자 정의 타입이기 때문에 ul_int 가 TYPE_NAME 토큰으로 바뀐다.

TYPE_NAME 토큰의 생성은 비록 주석처리 되어있긴 하지만, 이 과정은 본래 lex 코드의 check_type 함수에서 진행된다.

TYPE_NAME 은 type_specifier로 reduce 된다.
이게 유일한 reduce 방법이다.
identifier는 reduce 방법이 다양하니, type_specifier 와 같이 reduce 될 수 있는 구문을 찾아보자.


후보군이 2개나 있다.
기존 코드가 변수를 선언하는 문장이니까 한번 declaration 쪽으로 가보자.

이렇게 확장되었다.
더 확장이 되려면 IDENTIFIER가 type_qualifier 또는 type_specifier 둘 중 하나로 reduce 되어야 할 것 같다.

우선 type_qualifier 로 탑다운해서 들어가보니, 여기는 아닌 것 같다.
type_specifier도 INT 같은 타입들 토큰들이 reduce 되는 것이었으니 아니었다.
그럼 어쩔 수 없이 그냥 declaration_specifiers 자체에서 더 reduce 될 수 있는지 찾아보자.

이 구문을 발견했다.
왠지 적용이 될 것 같다.
init_declarator_list 로 파고들어보자.




IDENTIFIER를 발견했다!!
따라서 최종 파싱트리는 아래와 같다.
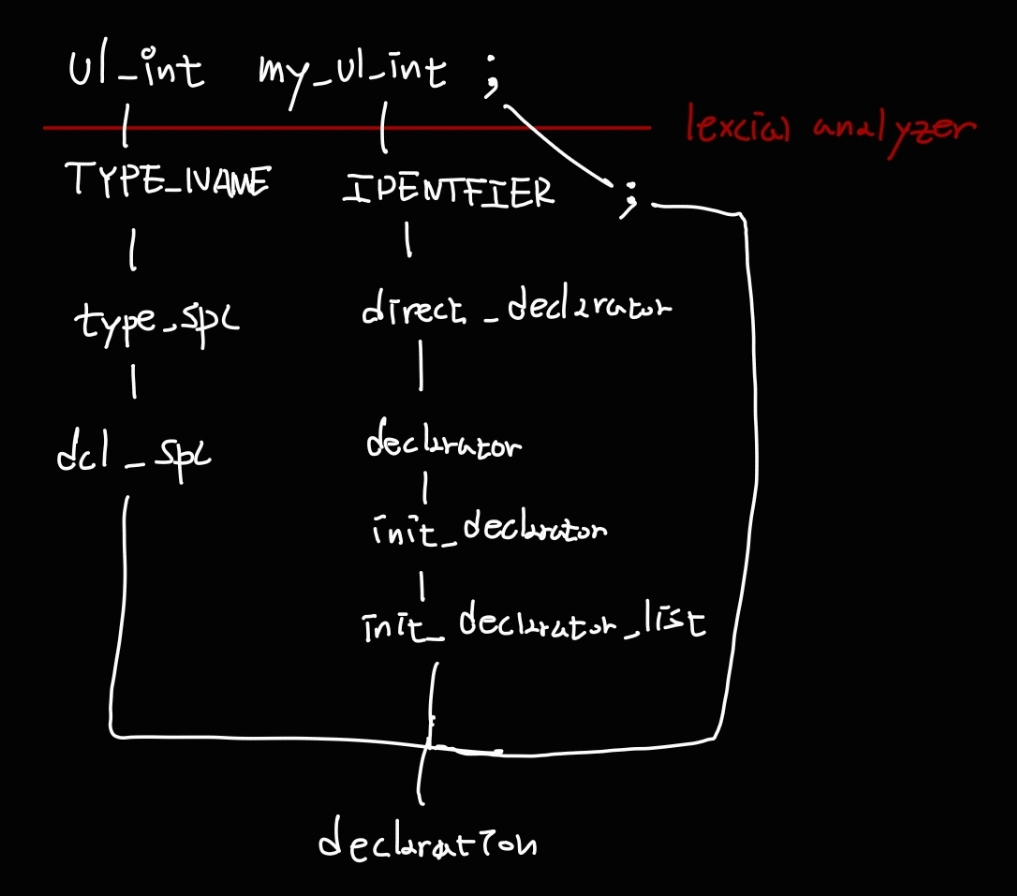

강의록 파싱트리와 동일하다.
'CS > 프로그래밍언어론' 카테고리의 다른 글
| [ lex / yacc ] error: 'AUTO' undeclared (first use in this function) 해결 (0) | 2024.05.03 |
|---|---|
| [프로그래밍언어론] 7. Parsing Problem (0) | 2024.04.19 |
| [프로그래밍언어론] 5. Lexical and Syntax Analysis (0) | 2024.04.17 |
| [프로그래밍언어론] 4. Semantics (0) | 2024.04.16 |
| [프로그래밍언어론] 3. Syntax 와 BNF, Parse Tree (2) | 2024.04.13 |