비디오 스트리밍 서비스의 기술적 어려움
넷플릭스, 유튜브와 같은 비디오 스트리밍 서비스의 트래픽은 인터넷에서 많은 부분을 차지하는 트래픽이다.
그래서 이런 비디오 스트리밍 서비스가 갖는 기술적 어려움이 몇 가지 있다.
1. scalability (확장성)
10억명이 넘는 유저들이 안정적인 서비스를 제공받으려면 정말 크고 안정적인 네트워크를 갖고 있어야 한다.
2. heterogeneity (이질, 개인화 정도로 이해했다.)
유저마다 자신이 살고있는 곳의 네트워크 환경이 다양할 것이다.
우리나라는 광대역이 잘 깔려있어서 500Mbps 네트워크를 갖는 경우도 많지만 외국은 100Mbps 대역폭을 쓰는 곳도 굉장히 많다.
또 어떤 사람은 이동중에 스트리밍 서비스를 이용하고, 어떤 사람은 유선 네트워크를 이용해서 서비스를 이용한다.
스트리밍 서비스를 제공하는 회사는 이렇게 서로 다른 환경에서 접속하는 유저들이 모두 각자 환경에 최적화된 서비스를 이용할 수 있도록 제공하고자 하는 어려움이 있다.
그래서 넷플릭스, 유튜브같은 기업들은 이를 해결할 수 있는 방법으로 분산된 어플리케이션 계층의 인프라를 구축했다.
이를 가리켜 보통 'CDN, Content Distribution Network' 라고 한다.
그리고 이에 더해 원활한 서비스를 제공하기 위한 각 회사의 고유 솔루션 프로토콜을 사용한다.
(넷플릭스는 DASH 라는 프로토콜을 사용한다. 이 프로토콜에 대해서는 뒤에 설명한다.)
비디오 (멀티미디어)
먼저 비디오 관련 네트워크를 이야기하기 전에, '비디오' 가 정확히 무엇인지 정리해보자.
비디오는 매우 짧은 간격으로 찍힌 수많은 사진들을 나열한 것이다.
이런 사진(디지털 이미지)은 컴퓨터에게 있어서 '픽셀' 이라고 하는 색상, 밝기, 명암 정보들의 배열과 같다.
따라서 각각의 픽셀은 bit로 표현된다.
이 이미지 데이터를 디지털로 보내기 위해서는 적절한 인코딩 방법이 필요하다.
인코딩 방식에 따라 MP4, AVI 등의 확장자가 결정된다.
이때 인코딩을 할 때는 적절한 redundancy(중복성)를 이용해서 최대한 효율적으로 인코딩하는 것이 중요하다.
왜냐하면 매우 짧은 간격으로 찍힌 사진 특성상 두 사진 사이의 색상정보는 거의 차이가 없을 가능성이 매우 크기 때문에, 같은 픽셀 정보를 중복해서 저장하기보다, 중복된 픽셀정보를 잘 걸려내서 더 적은 데이터 양으로 동영상을 표현하는 것이 효율적이기 때문이다.
이때 중복된 픽셀을 제거하기 위해 두가지 관점에서 중복된 데이터를 제거한다.
첫번째는 spatial redundancy, 하나의 이미지 내에 중복되는 픽셀값을 적절히 짧게 표현하는 것을 말한다.
두번째는 temporal redundancy, 연속된 이미지와 이미지 사이에 겹치는 픽셀값을 적절히 짧게 표현하는 것을 말한다.
비디오를 인코딩하는 방식에는 2가지 기법이 있다.
1. CBR (constant bit rate)
비디오를 인코딩할 때, 인코딩 rate가 고정된 것이다.
각 프레임 (이미지) 마다 인코딩한 결과의 bit 사이즈가 모두 동일한 것을 말한다.
2. VBR (variable bit rate)
인코딩 rate가 spatial, temporal redundancy 에 의해 그때 그때 바뀌는 것을 말한다.
따라서 플임마다 인코딩 결과의 bit 사이즈가 다를 수 있다.
대표적인 인코딩 예시로 MPEG 가 있다.
MPEG 1 은 CD-ROM 에서 사용하던 인코딩으로 1.5Mbps 대역폭이 필요하고,
MPEG 2 는 DVD 에서 사용하던 인코딩으로 3~6Mbps 대역폭이 필요하고,
MPEG 4 는 인터넷에서 사용하는 인코딩으로 64kbps ~ 12 Mbps 의 대역폭이 필요하다.
Stored 비디오 스트리밍
유튜브같은 회사는 어떻게 비디오를 스트리밍할까?

제일 단순하게 생각하면, 비디오 서버에 비디오 데이터가 저장되어 있고, (실시간 X)
이 데이터를 인터넷을 통해 클라이언트에게 보내준다고 생각할 수 있다.
이 경우 주요 기술적 문제는 서버와 클라이언트 사이의 이용가능한 대역폭이 실시간으로 변한다는 점이 있다.
비디오는 매우 큰 데이터이기 때문에 한번에 보낼 수 없고, 프레임들을 나눠서 보내줘야 한다.
하지만 대역폭이 인터넷 환경에 따라 실시간으로 변하기 때문에 100의 데이터를 서버에서 엑세스 네트워크의 라우터로 보낼 땐 괜찮았는데, 엑세스 네트워크 라우터에서 집으로 보낼 때는 대역폭이 좁거나, 트래픽이 몰려서 느리게 전달되거나 패킷이 손실될 수 있다. 이는 서킷 스위칭대신 패킷 스위칭 방식을 채택하고 있기 때문에 발생하는 문제이다.
또는 이동중에 비디오를 본다면, 엑세스 네트워크가 계속 변하기 때문에 대역폭이 변하기도 한다.
이를 해결하기 위한 다양한 테크닉이 있다.
예를 들면 전송하는 양을 줄이기 위해, 사용자가 눈치 채지 못하게 비디오의 퀄리티를 약간씩 낮춰서 보냄으로써 비디오가 끊기지 않게 보일 수 있도록 하는 기법도 있다.
여기서는 조금 다른 기법을 보려고 한다.
우선 비디오가 서버에 저장되고, 보내는 과정을 아래와 같이 볼 수 있다.

가로는 시간축이고, 세로는 누적 전송량을 의미한다.
우선 비디오를 녹화하는 시간이 있다.
초당 30프레임의 비디오를 녹화해서 서버에 잘 저장을 해두었다.
이때 클라이언트가 이 비디오에 대해 요청을 보내면, 서버는 비디오를 앞에서부터 조금씩 나눠서 보내준다.
비디오 데이터를 보낼 때 나누는 크기는 서버에서 고정하여 고정된 크기의 데이터를 보내주고 있다.
이 고정된 크기의 데이터가 network delay를 거쳐서 클라이언트에게 도착하면, 클라이언트가 받은 비디오 데이터를 실행하여 영상을 본다. (이때 network delay는 간단하게 고정되어 있다고 가정하자.)
이 경우는 매우 이상적인 경우이다.
우선 고정된 데이터를 보내는데 항상 일정하게 고정된 network delay를 거쳐 전송되고 있기 때문이다.
하지만 현실에서는 이런 이상적인 상황이 존재하지 않는다.
현실에서 발생하는 기술적 난관
사용자는 continuous playout 을 원하는 것이 당연한데, 서버에서는 이걸 제공하는 것이 기술적으로 쉽지 않다.
우선 위와 같은 이상적인 상황은 클라이언트가 비디오를 재생하는동안, 그 재생하는 시간 간격 (타이밍)이 항상 일정하게 맞아야 한다. 하지만 network delay (jitter 라고도 한다.) 는 시시각각 변하기 때문에 client-side 버퍼를 둘 필요가 있다.
그 밖에도 유튜브 같은 경우는 동영상을 일시정지했다가 앞으로 갔다가 뒤로갔다가 하면서 점프하기도 하고, 2배속으로 틀기도 한다. 또 비디오 패킷들이 유실되어서 다시 전송되어야 하는 경우도 있다.
그래서 이럴 때는 로딩중 이라는 동그라미를 그려놓고 그 시간동안 해당 지점의 데이터를 가져와서 보여주거나 광고를 넣는 방식을 사용한다.
Client - Side Buffer (playout buffering)
클라이언트 사이드 버퍼는 말 그대로 클라이언트가 데이터를 수신하자마자 바로 재생하는 것이 아니라 미리 조금씩 조금씩 저장해두는 것이다.
그리고 사용자에게 동영상을 보여줄 때는 이 버퍼에 저장된 내용을 조금씩 빼서 보여준다.
만약 네트워크 딜레이가 생겨서 다음 데이터가 늦게 도착한다면, 다음 데이터를 기다리는 동안 버퍼에 저장한 데이터를 보여준다.
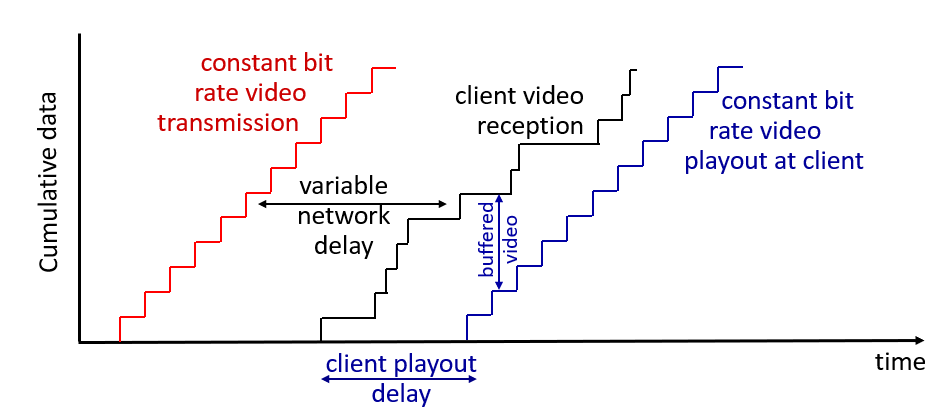
이를 그림으료 표현하면 위와 같다.
서버는 여전히 고정된 bit rate 로 비디오른 전송하는데, 클라이언트에 비디오가 도착하는 시간은 들쭉날쭉하다.
그래서 임의로 client playout delay 를 두어, 그 딜레이 분에 받은 비디오를 버퍼에 저장해두고, 클라이언트 입장에서는 끊김없이 비디오가 보이도록 할 수 있다.
모든 비디오 스트리밍 서비스를 제공하는 업체는 위 방식을 채택하고 있다.
상황에 따라 클라이언트 사이드 버퍼의 크기가 바뀔 수 는 있지만, 클라이언트 사이드 버퍼링 이후에 플레이 아웃 딜레이를 주는 것이 일반적이다.
DASH
DASH 는 넷플릭스에서 사용하는 솔루션으로, 멀터미디어 스트리밍 전용 프로토콜이다.
(Dynamic Adaptive Streaming of HTTP)
서버는 비디오 파일을 미리 여러 조각으로 나눠둔다.
이 조각을 'chunck' 라고 한다.
그리고 각각의 청크는 서로 다른 비율로 인코딩된다.
그래서 영화의 어떤 부분은 화질이 조금 떨어지게 만들어 전송할 데이터의 크기를 줄여서 네트워크가 혼잡한 상황에도 무리없이 보낼 수 있도록 한다.
이 화질을 고화질, 중화질, 저화질로 분류해서 같은 청크에 대해 서로 다른 인코딩 비율을 가질 수도 있다.
그리고 이 각각의 인코딩 결과물을 서로 다른 파일로 저장해두고, 사용자의 클라이언트 환경에 맞추어서 만약 환경이 좋지 않은 사용자라면 저화질 청크를 보내주고, 환경이 좋은 사용자라면 고화질 청크를 보내주도록 한다.
이 파일들은 여러 CDN(content distribution network, 간단히 말해 파일 서버) 노드에 저장해둔다.
그리고 이 파일 서버들은 여러군데에 위치해 있고 서로 연결되어 있다.
클라이언트는 manifest 파일을 서버로부터 받는다.
이 파일에는 각각의 청크 파일들이 어디에 위치해 있는지 정보가 적혀있다.
일종의 파일 메뉴판이라고 생각하면 된다.
그래서 클라이언트는 자신의 상황을 보고 이 상황에 맞는 청크 데이터를 골라 서버에게 주문하면, 서버는 해당 청크 파일을 CDN에서 보내주게 된다.
그리고 이때 필요한 청크 파일이 무엇인지 결정하는 역할을 클라이언트에 있는 intelligence 가 하게 된다.
즉, 클라이언트는 주기적으로 서버와 클라이언트 사이의 대역폭을 측정해서 그 결가를 토대로 적절한 인코딩의 청크를 매니페스트 파일을 보고 요청한다.
또한 클라이언트는 자신의 버퍼 크기를 참조해서, 자신의 버퍼가 넘치지 않도록, 도 버퍼가 비어있지 않도록 적절하게 요청 시점까지 결정한다.
그리고 마지막으로 어떤 CDN에 청크를 요청할지도 클라이언트가 결정한다.
경우에 따라서는 대역폭이 크지만 나와 멀리 떨어진 서버에 요청을 보내고, 대역폭이 줄어들었다면 더 가까이 있는 CDN에 요청을 스위치할 수 있다.
비록 이름이나 디테일한 알고리즘은 다를 수 있어도, 아마존 프라임, 유튜브, 넷플릭스 모두 기본적으로 이 3가지 기법을 사용하고 있다.
여기에 더한 추가적인 솔루션은 회사들이 공개하지 않는 자신들만의 기술로서 갖고 있다.
그래서 디테일한 솔루션을 알아낼 때는 리버싱을 통해 추측할 수밖에 없다.
CDN
위에서 DASH 프로토콜을 설명하면서 CDN 이야기를 했었다.
그렇다면 CDN은 무엇일까?
CDN은 Content Distribution Network 의 줄임말이다.
이 CDN이 없다면 대다수의 스트리밍 서비스들은 제대로 서비스를 할 수 없을 것이다.
CDN은 스케일링 문제 (대다수의 사용자에게 서비스를 제공하는 것) 를 해결하기 위해, 사용자들 근처에 서버를 두겠다는 아이디어를 사용한다. 사용자 근처에서 클라이언트와의 대역폭이 보장되는 위치까지 가겠다는 것이다.
그래서 그 위치에서 클라이언트가 요청하는 콘텐츠를 클라이언트 가까이서 서비스할 수 있도록, 콘텐츠를 분배하는 네트워크(CDN)를 만들겠다는 것이다.
수백, 수천만의 사용자들에게 끊김없이 콘텐츠를 제공하는 것은 기술적인 어려움이 많다.
이를 위한 첫번째 해결책은, 하나의 매우 거대한 서버를 하나 두는 아이디어가 있다.
물론 이렇게 두면, 당연히 single point of failure가 되는 것은 자명하다.
이 서버 하나에 문제가 생기면 모든 서비스가 중지되는 것이기 때문이다.
또 서버와 거리가 매우 먼 클라이언트는 매우 긴 프로파게이션 딜레이를 갖는다.
모든 요청이 서버 한 곳에 모이기 때문에 네트워크 혼잡도 발생할 여지가 크다.
따라서 이 옵션은 당연히 확장성을 감당하기 힘든 옵션이다.
특정 지역에서만 서비스하겠다면 의미가 있을 수 있지만, 넷플릭스같은 다국적 기업은 이렇게 할 수 없다.
두번째 옵션은 CDN을 도입하는 것이다.
여기에서도 hit ratio가 중요한 역할을 한다.
클라이언트가 요청한 콘텐츠가 마침 근처에 있는 CDN에 있을 확률이 높은 것이 좋다는 것이다.
근처의 CDN에 없다면 멀리 떨어진 CDN으로부터 가져와야 하기 때문이다.
그래서 어느 지역 사용자들이 주로 어느 컨텐츠를 많이 찾는지를 분석하고 예측하는게 매우 중요해졌다.
이런 CDN 솔루션을 제공하는 회사가 akamai, limelight 와 같은 회사다.
이 회사들이 채택하고 있는 정책은 크게 2가지가 있다.
1. enter deep
최대한 사용자 근처로 가깝게 가자는 뜻이다.
즉, 엑세스 네트워크까지 들어가서 CDN 서버를 많이 두자는 것이 목표다.
akamai가 주로 채택하고 있는 정책이다.
2. bring home
다수의 서버를 사용자 근처에 enter deep 하기보다, 사용자에게서 조금 멀더라도 방대한 크기의 고성능 서버를 두겠다는 정책이다.
대신 엑세스 네트워크에 들어가진 않지만 근처에 POP(Point Of Presence) 이라는 걸 둘 수 있다.
여러 ISP 네트워크의 연결 지점이라고 생각하면 된다.
원래는 통신 용어인데, 엑세스 네트워크 (ISP 네트워크) 를 연결하는 지점, 거대한 스위치로 연결된 지점으로 볼 수 있다.
limelight 사가 채택하는 방식이다.
Example : Netflix
CDN의 예제로 넷플릭스를 살펴보자
넷플릭스는 동일한 컨텐츠를 여러군데의 CDN에 복사하여 저장하고 있다.
이때 사용하는 것이 OpenConnect CDN 이다.
이 CDN은 넷플릭스 자사의 CDN 솔루션이라고 보면 된다.
넷플릭스는 과거에 전문 CDN 업체의 서비스를 통해 서비스를 제공했다.
akamai, limelight, 또 다른 3의 회사 이렇게 3개의 회사로부터 서비스를 받았다.
그런데 점차 넷플릭스의 사용자가 들어나자 직접 서버를 구축하자는 생각을 해서 OpenConnect 라는 솔루션을 직접 도입했다.
이 솔루션은 넷플릭스 자체 CDN이라 타사의 콘텐츠는 지원하지 않는다.
만약 사용자가 매드맨 이라는 영화를 요청하면, 서비스 프로바이더가 manifest 파일을 리턴한다.
그러면 클라이언트는 이 파일을 보고 자신의 네트워크 환경에 맞는 청크 파일을 요청한다.
(물론 넷플릭스 요금제에 따른 화질 제한이 있기도 하다)
OTT는 Over The Top 의 약자이다.
(CDN 을 이용한 컨텐츠 제공 서비스를 지칭하는 말처럼 쓰이지만, 실제론 관계가 없다.)
그냥 공중에서 파일이 뚝 떨어지듯 제공된다고 해서 쓰는 것 같다..
OTT 가 가진 기술적 문제는 네트워크 혼잡이 발생했을 때, 이를 동적으로 어떻게 잘 처리해서 사용자의 불편을 최소화하느냐는 것이다.
사용자의 접속환경은 매번 시시각각 바뀔 텐데, 그럼에도 불구하고 스트리밍 서비스를 계속 제공할 수 있는 방법을 찾는 것이다.
그래서 이 기술적 문제를 해결하기 위해 중요한 핵심 포인트가 CDN 노드에 어떤 컨텐츠를 둘 것인지 결정하는 것이다.
이를 위해 인공지능을 활용한다.
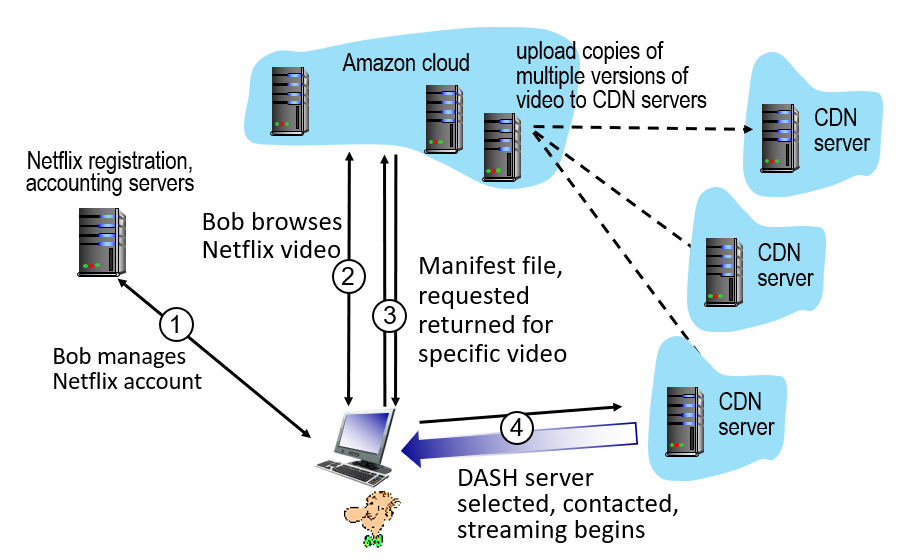
다음은 넷플릭스가 실제로 운영하는 방식이다.
넷플릭스는 유저의 회원가입, 요금제 관리만을 담당한다.
넷플릭스가 유저의 계정을 인증해주면, bob 은 amazon cloud 에 있는 넷플릭스 서비스를 통해 비디오를 검색하고, 요청한다.
그러면 아마존 클라우드에 있는 서버가 요청한 비디오에 대한 manifest 파일을 돌려주고, 컴퓨터는 이 정보를 토대로 DASH 프로토콜을 이용하여 적절한 비디오를 골라 넷플릭스의 OpenConnect CDN 서버에 데이터를 요청한다.
이번엔 자체 CDN이 아니라 타사의 CDN을 사용하는 경우, 어떤 과정으로 비디오를 보는지 DNS 개념을 가지고 함께 보자.

Bob 이 어떤 온라인 영화 사이트에서 영화를 보겠다고 요청을 보냈다.
그러면 bob의 로컬 DNS 서버는 해당 영화 URL을 가져올 IP주소를 얻기 위해 영화사이트의 authoratative DNS 서버에 질의를 보낸다.
그러면 영화사이트의 DNS 서버는 CDN 솔루션 회사의 도메인을 돌려주고, bob의 컴퓨터는 다시 CDN의 해당 네트워크에 요청을 보내서 실제 영화 데이터를 가져온다.
'CS > 컴퓨터 네트워크' 카테고리의 다른 글
| [컴퓨터 네트워크] 15. Transport Layer (1) : 트랜스포트 계층 개요 (0) | 2024.04.20 |
|---|---|
| [컴퓨터 네트워크] 14. Application Layer (7) : Socket Programming (0) | 2024.04.19 |
| [컴퓨터 네트워크] 12. Application Layer (5) : DNS (0) | 2024.04.18 |
| [컴퓨터 네트워크] 11. Application Layer (4) : HTTP/2 (0) | 2024.04.16 |
| [컴퓨터 네트워크] 10. Application Layer (3) : Web Cache (0) | 2024.04.16 |