TCP 개요
TCP 는 RFC 793 에서 처음 제시된 프로토콜로, 아래와 같은 특징을 가진다.
1. point - to - point 프로토콜
TCP는 하나의 sender 와 하나의 receiver 사이에 일어나는 통신에 대한 프로토콜이다.
(참고로 1:1 이 아닌 통신으로는 브로드캐스트(1:N, 모두가 수신하도록 전송하는 방법)와 멀티캐스트(특정 그룹만 수신하도록 전송하는 방법)가 있다.)
2. 신뢰성 제공, 정해진 순서에 따른 byte stream 제공
byte stream을 제공한다는 의미는 어플리케이션이 보낸 메세지 단위로 데이터를 전송하지 않는다는 의미이다.
여러 메세지에 대해서 메세지 단위로 구분해서 데이터를 보내주지 않고, 정해진 byte 단위로 구분해서 전송하므로, 어플리케이션이 생성한 메세지의 크기가 크다면 이를 여러개로 쪼개서 보낼 수도 있고, 크기가 작다면 하나의 전송 단위 안에 2개 이상의 메세지에 대한 내용이 동시에 담길 수 있다.
3. full duplex data
하나의 connection 내에서 양쪽 모두 서로 데이터를 주고 받을 수 있다.
즉, sender와 receiver의 역할이 고정되어 있지 않다.
이때 MSS (Maximum Segment Size) 를 이용해 세그먼트에 실어 나를 수 있는 데이터의 크기를 결정한다.
따라서 1MSS는 1세그먼트, 2MSS는 2세그먼트와 같이 생각할 수 있다.
4. 누적 ACK를 사용한다.
rdt 에서 공부한 누적 ACK 개념을 사용한다.
따라서 패킷 바이 패킷으로 ACK를 보내지 않고, 하나의 ACK로 여러 패킷에 대해 ACK를 표시할 수 있다.
5. 파이프라이닝
TCP는 패킷을 전송한 뒤 ACK를 기다렸다가 패킷을 전송하는 Stop and Wait 방식의 프로토콜이 아니다.
sender 윈도우를 설정하고, 그 윈도우 내에 있는 패킷은 ACK를 받지 않더라도 파이프라이닝 방식으로 전송한다.
따라서 TCP의 congestion control 과 flow control 은 이 윈도우와 밀접하게 관련이 있다.
6. 연결 설정 (connection - oriented)
TCP는 데이터를 주고받기 전, 사전에 handshaking 과정을 통해 연결을 설정한다.
말 그대로 클라이언트와 서버 사이에 악수를 하면서 사전에 어떻게 데이터를 주고받을지 규칙을 정하는 과정을 거친다.
이 과정을 거치면 클라인언트와 서버 각각 윈도우의 버퍼, 변수 등이 만들어진다.
7. 흐름 제어 (flow control)
데이터를 전송할 때, receiver의 버퍼를 넘치지 않는 선에서 데이터를 보내도록 조절하는 과정을 흐름 제어라고 한다.
TCP 헤더
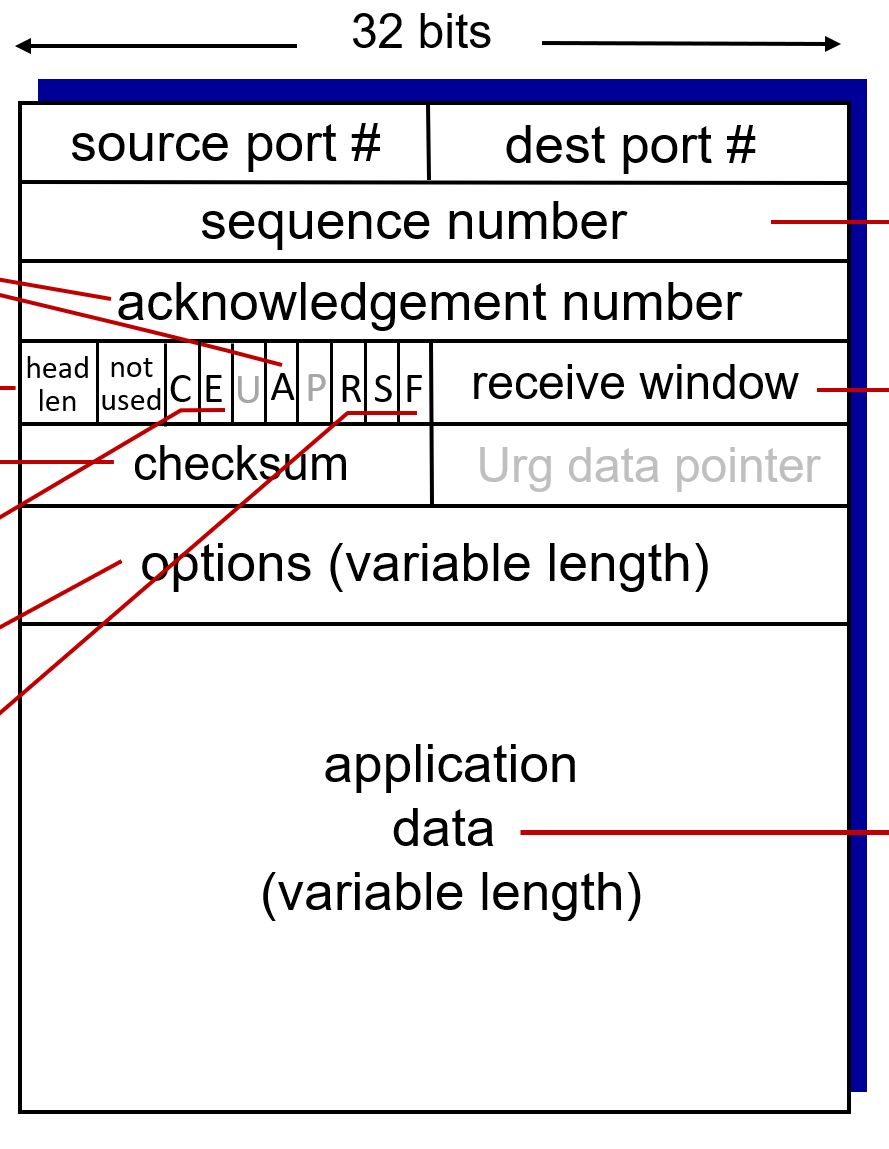
TCP 세그먼트는 그림과 같은 구조로 되어있다.
application data 부분은 가변 길이를 갖고 있고, 그 위쪽이 TCP 헤더의 내용이다.
TCP 헤더는 options 부분이 가변 길이를 갖고 있기 때문에, 헤더의 길이도 가변이다.
만약 options 가 비어있다면, 기본적인 TCP 헤더의 길이는 20byte가 된다.
options 필드에는 최대 40byte까지 데이터가 들어갈 수 있다.
따라서 TCP 헤더의 최대 크기는 60byte 이다.
(하지만 options 필드는 대부분의 경우 사용하지 않는다고 한다.)
header length 필드
그림에서 4번째 줄 첫번째 칸의 'head len' 부분이다.
이 필드에는 4byte 를 기본 단위로 하는 값을 표기한다.
따라서 만약 이 필드의 값이 5라면 헤더의 길이는 4*5 = 20byte, 즉 옵션이 없는 기본 헤더임을 의미한다.
이 값은 최대 15까지 될 수 있다. (헤더의 길이가 최대 60byte 이므로)
필드 중에 data length 필드는 존재하지 않는데, 데이터의 크기는 어떻게 알 수 있을까?
TCP가 어플리케이션의 메세지를 캡슐화하고 나서, 3계층으로 세그먼트를 보내면, 3계층은 다시 세그먼트에 IP 헤더를 붙여서 캡슐화한다.
이때 IP 헤더에 길이 필드가 들어있기 때문에 이를 통해 데이터 필드의 길이를 유추할 수 있다.
Port Number 필드
4계층 프로토콜에서 제일 중요한 것은 포트 번호이다.
따라서 첫번재 줄에는 source port 번호, destination port 번호가 들어간다.
Sequence Number 필드
TCP는 신뢰성있는 byte stream 을 전송하는 프로토콜이다.
따라서 현재 전송하고 있는 byte stream 을 나타내기 위해 seq number를 사용한다.
application data 부분에 들어있는 첫번째 byte에 대한 시퀀스 번호로 생각하면 된다.
Acknowledgement Number 필드
TCP가 전송하는 ACK의 번호가 담기는 필드이다. (리시버가 사용하는 필드)
Go-Back-N 에서 설명한것과 비슷하게, 패킷 단위 대신 시퀀스 단위로 어떤 시퀀스까지 잘 받았는지 한번에 누적 ACK로 대답한다.
Flag 필드
A 필드 : 지금 보내는 응답이 ACK라는 의미이다. 즉, Acknowledgement 필드에 있는 값이 의미있는 값이다.
R 필드 : Reset (RST), 연결 설정과 관련된 플래그이다. TCP 센더가 보낸 요청에 대해 어느 순간부터 리시버가 응답을 하지 않을 경우(머신 다운, 해킹 등), TCP 채널을 계속 열어두고 있으면 부담이 되기 때문에 센더가 연결 설정을 일방적으로 종료할 수 있다.
F 필드 : Finish (FIN), 통신을 마치고 정상적으로 연결 설정을 종료할 때 사용하는 플래그이다. 정상적인 연결 설정 종료를 위한 프로토콜도 따로 있는데, 그때 이 F필드를 활성화해서 보내면 정상적으로 연결을 종료하고 싶다는 의사를 표현하는 것과 같다.
S 필드 : Synchronize (SYN), 최초로 연결설정할 때 핸드쉐이킹에서 사용하는 필드이다. 이 필드를 활성화해서 요청을 보내면 너와 연결을 맺겠다는 의사를 표시하는 것과 같다. 따라서 이 필드를 활성화하여 전송할 때는 데이터를 담아보내지 않는다. 이 필드가 활성화 되었을 때 seq number 필드는 initial seq number 필드로 사용된다.
C, E 필드 : Congestion Notification 과 관련된 필드이다. 혼잡 제어에 대해 정리할 때 자세히 정리한다.
[자주 사용하지 않는 필드]
U 필드 : Urgent, 그림에서 urg data pointer 가 가리키는 위치까지의 데이터는 시급하게 빨리 처리해야 하는 데이터임을 나타내는 플래그이다.
P 필드 : Push, TCP에서 수신한 데이터를 수신하지마자 바로 어플리케이션으로 밀어 보내라는 의미의 비트이다.
Receive Window
Flow Control 을 위해 사용되는 필드이다.
리시버가 응답을 보낼 때, 자신의 버퍼의 남은 공간 크기를 보내준다.
센더는 이 값을 보고, 앞으로 얼마만큼의 데이터를 추가로 실어서 보낼 수 있는지를 파악하여 전송 데이터량을 제한할 수 있다. 따라서 리시버의 버퍼가 흘러넘치지 않도록 막는 역할을 수행한다.
Checksum
전송 중 비트 오류를 검사하기 위해 존재하는 필드, UDP 때와 마찬가지로 의미없는 필드이다.
Seq Number & ACK
Go-Back-N 과 Selective Repeat 에서는 '패킷' 단위로 시퀀스 넘버와 ACK 넘버를 부여했었다.
TCP에서는 Byte 마다 번호를 부여받는다.
예를 들어서 100바이트 데이터를 전송한다면, 첫번째 바이트의 번호가 0번 일 때, 100번째 바이트의 번호는 99번이 되는 식이다. (즉, 바이트마다 번호가 증가한다.)
이는 TCP가 Byte Stream 을 목적지에 전송하는 것이 목표인 프로토콜이기 때문이다.
따라서 TCP 헤더의 Seq Number 필드에 들어가는 값은, ISN (Initial Seq Number) 가 아니면 세그먼트 데이터의 첫번째 바이트에 해당하는 번호가 된다.
TCP 헤더의 S 플래그가 활성화 되어있다면, Seq Number 필드에 들어가는 값이 ISN, 앞으로 데이터를 주고받을 때 시작할 시퀀스 넘버의 번호이다. 그렇지 않다보면 주고받는 데이터의 첫번째 바이트에 부여된 번호를 가리키게 된다.
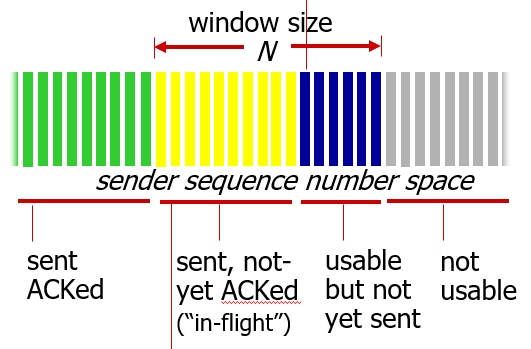
sender의 윈도우가 위와 같이 되어 있다고 해보자.
만약 파란색 부분에 있는 데이터를 보낼 때, sender 가 전송하는 TCP의 헤더에서 sequence number 필드는 첫번째 파란색 부분의 데이터의 첫번째 바이트를 가리킬 것이다.

그렇다면 sender 입장에서 ACK를 수신할 때는 어떤 번호를 수신할까?

수신하는 세그먼트의 헤더는 위와 같을 것이다.
acknowledgement number 파트에 누적 ACK 번호가 담기고, A 플래그가 활성화된 헤더이다.
이때 TCP에서 수신 후 보내는 ACK 번호는 내가 잘 받은 번호의 바로 다음 번호를 ACK 번호로 보낸다.
만약 센더가 100바이트짜리 데이터를 보냈고, 각 바이트에 부여된 번호가 0번부터 99번까지였다면, 100 바이트 데이터를 모두 잘 받았을 때, ACK 로 99가 아니라 100 이라는 번호를 보내준다. (누적 ACK)
내가 다음부터 받기를 기대하는 번호를 보내는 것이다.
따라서 위 이미지와 같은 상황이 되기 위해서 receiver 가 보낸 ACK 번호는 노란색 영역의 첫번째 바이트에 해당하는 번호가 된다.
그렇다면 TCP는 순서를 벗어난 시퀀스 번호, 또는 ACK 번호를 받았을 때 어떻게 처리할까?
TCP는 이에 대해 '알아서 구현하라'는 방법을 취한다. ( TCP 스펙으로 명시하지 않았다.)
(하지만 실제로는 순서를 벗어났다고 버리는 방법을 취하는 경우는 거의 없다고 한다. TCP의 구현은 OS, 커널 영역에서 이루어지는데, 많은 운영체제에서 TCP를 구현할 때 순서를 벗어난 경우, 버리지 않고 받아들인다고 한다.)
예시

위 그림과 같은 상황을 생각해보자.
1. Host A 에서 유저가 입력한 'C' 라는 문자 (아스키 코드라면 1byte) 를 데이터로 실어 Host B 로 전송한다.
이때의 Seq number = 42, ACK = 79 라고 하자.
2. Host B 에서 데이터를 잘 받은 경우, Seq number + 1 을 Ack로 보낸다. (보낸 데이터의 크기가 1Byte 이므로, 다음에 받을 데이터의 번호는 43이 된다.)
이때는 Host B가 ACK를 보내는 'sender' 의 입장이 되므로, Seq Number는 자신이 수신한 ACK 번호인 79가 된다.
(자신이 수신한 ACK 번호가, 자신이 보낼 차례의 Seq 번호이기 때문이다)
그리고 서버는 단순하게 자신이 수신한 데이터를 echo back 하는 서버라고 해보면, 데이터 영역에 자신이 받은 'C' 를 실어서 보내줄 것이다.
3. Host A 는 echo된 'C'를 수신하면서 기존에 자신이 보냈던 요청에 대해 ACK도 같이 받는다.
ACK 번호가 43이었으므로, 자신이 추가적으로 Host B 에 데이터를 전송할 경우, 이때는 Seq 43으로 데이터를 전송할 것이고, Host A 가 수신한 Seq 79 에 대한 ACK 정보도 같이 보내야 하므로 ACK 필드에는 80을 담아서 보내줄 것이다.
헷갈리기 쉬우니 한쪽씩 생각을 해보자.
Host A 입장에서는 seq number = 42 로 'C' 라는 1byte 데이터를 보냈다.
이 'C' 라는 1byte 데이터에 매겨진 번호가 42인 것이다.
만약 Host B가 이를 잘 받았다면, 다음 byte 의 값인 43을 ACK로 보낼 것이고,
이후에 Host A가 추가적으로 Host B에 데이터를 보낼 때는 43을 seq number로 하여 보낼 것이다.
Host B 입장에서는 관점에 따라 자신이 요청을 보내는 입장이고, Host A 가 응답을 보내는 주체로 볼 수 있다.
Host A가 ACK = 79를 담아 데이터를 보내면, 기존에 보낸 데이터에 대해 78까지는 문제없이 수신되었음을 알게 되었다.
따라서 응답할 때는 seq number = 79 로 전송한다.
그리고 나중에 Host B 가 데이터를 수신할 때는 ACK 80을 받아야 할 것이다. (seq number == 79 일 때 1byte 데이터를 실어 보냈으므로)
Timeout (RTT, Round Trip Time)
TCP는 신뢰성있는 전송을 보장하기 때문에, 데이터가 유실된 경우 중간에 재전송을 해야 한다.
따라서 재전송의 기준으로서 timeout을 설정할 필요가 있다.
timeout의 값은 단순하게 생각해보면 1 RTT 보다 약간 길면 적절할 것이다.
내가 보낸 응답이 상대측에 도착한 뒤, 상대측에서 다시 나에게 응답이 올 때까지 걸리는 시간은 최소한 기다리는 것이 당연하다.
하지만 네트워크 상황은 수시로 바뀌니 이 시간에 딱 맞게 설정하기보다 약간 여유를 두는 것이 좋을 것 같다.
만약 1 RTT 보다 짧게 timeout을 걸면, premature timeout이 발생해서 loss가 없는데도 데이터를 계속 재전송하는 문제가 발생할 것이다.
만약 1 RTT 보다 너무 길게 timeout을 걸면, 중간에 loss가 발생했을 때 대처하는 시간이 늦어지므로 역시 성능상으로 좋지 못하다는 것을 예상할 수 있다.
어쨌든 제일 좋은건 1 RTT보다는 조금 긴, 적절한 timeout을 설정하는 것이 좋다는 것은 자명하다.
그런데 실제 인터넷 환경은 시시각각 바뀌기 때문에, RTT 역시 계속 바뀔 수 있어서 timeout 을 특정 RTT를 기준으로 고정할 수 없다. 똑같은 a - b 사이에 데이터를 주고받는다고 해도, RTT는 매번 바뀔 수 있다.
그래서 TCP는 실시간으로 매번 RTT를 측정하여, 측정한 값을 토대로 timeout을 동적으로 변경하는 방식을 취한다.
RTT를 측정하는 방법은 간단하다. sender가 세그먼트를 보낸 뒤, 그 세그먼트에 대해 ACK를 받을 때까지의 시간을 측정하면 된다. 이렇게 측정한 RTT를 샘플 RTT 라고 한다.
단, 여기에서 세그먼트를 '재전송' 한 경우는 샘플 RTT로 치지 않는다.
왜냐하면 재전송을 해서 받은 ACK가 기존에 보냈던 데이터에 대해 늦게 도착한 ACK 인지, 마침 두번째 재전송할 때의 ACK가 빨리온 것인지 구분할 수 없어서 정확한 RTT를 구할 수 없기 때문이다.
하지만 여전히 Sample RTT가 매번 바뀔 수 있다는 문제는 해결되지 않았다.
TCP는 이에 대응하기 위해, 과거에 측정한 RTT와 합하여 RTT의 평균을 통해 timeout을 설정한다.

이를 수식으로 나타내면 위와 같다.
현재 측정한 Sample RTT 를 얼마나 반영하는지는 알파 값에 따라 달려있다.
이 값은 보통 0.125 정도로 설정한다고 한다.
이때 내가 당장 지금 측정한 RTT를 곧바로 timeout 기준으로 삼지 않는 이유는 Sample RTT 값이 네트워크 상황에 따라 순간적으로 얼마든지 툭 튀어올랐다가 줄어들었다가 할 수 있기 때문이다.
위와 같은 방법을 EWMA (Expotentional Weighted Moving Average) 라고 한다.
이제 이 값을 토대로 실제 timeout 에 사용할 값을 결정해보자.
Estimated RTT 를 곧이 곧대로 timeout 기준으로 삼기에는 premature timeout 이 발생하기 쉽기 때문이다.
따라서 실제 timeout 값을 결정할 때는 Estimated RTT 에 safety margin을 둔다.
그런데 만약 RTT 를 측정할 때마다 들쭉날쭉하게 변화했다면, safety margin을 크게 두고, 크게 변화가 없었다면 safety margin을 작게 두는 것이 합리적이다.
따라서 safety margin 값은 아래와 같이 분산을 이용해서 결정한다.

Dev RTT 가 RTT를 측정했을 때의 그 분산 값이다.
이 분산 값에 4를 곱한 값을 safety margin 으로 둔다.
(곱하기 4인 이유는 실험적으로 이게 제일 적절하다는 것이 나와서 이렇게 쓴다고 한다.)

이때 Dev RTT를 구할 때도 Estimated RTT를 구할 때와 비슷하게 과거에 구한 Dev RTT를 같이 활용한다.
기존 Dev RTT 에 새로 구한 편차를 특정 비율 반영하는 방식으로 구한다.
(이 비율은 일반적으로 0.25를 사용하는데, 이 역시 실험적으로 이 값이 적절하다고 나와서 쓴다고 한다.)
정리하면 TCP는 timeout을 설정해야 하는데, 인터넷 환경 특성상 그 환경이 자주 변하기 때문에 한번 측정한 RTT 값을 그대로 활용할 수 없어 Estimated RTT를 구해서 이 값을 통해 과거의 RTT를 반영한 RTT를 사용한다.
그리고 RTT를 그대로 timeout 값으로 두는 것이 아니라 안전 마진을 두기 위해서 분산값을 활용하는데, 이 분산 값 역시 이전에 구한 분산 값을 일정비율 반영하여 크게 벗어나지 않도록 설정한다.
TCP sender & receiver
Sender
TCP의 sender가 어떻게 동작하는지 간단하게 각 이벤트 별로 동작을 살펴보자.
- 상위 어플리케이션으로부터 메세지를 받은 경우
우선 어플리케이션이 보낸 메세지를 세그먼트의 payload에 집어넣는다.
이때 TCP는 메세지의 경계를 유지한 채 그대로 보내준다는 보장을 하지 않는다.
따라서 메세지를 얼마나 잘라 넣을지는 TCP가 알아서 결정한다.
만약 상대편 버퍼의 공간이 넉넉하지 않다면, 어플리케이션 데이터를 잘라서 작게 만들어 보낼 수도 있다.
세그먼트를 만들면, 세그먼트의 seq number를 부여한다.
이때 이 번호는 payload 데이터의 첫번째 바이트에 대한 넘버이다.
또 만약 타이머가 돌아가고 있지 않다면 타이머를 세팅한다.
이때 타이머는 가장 오랫동안 ACK를 받지 못한 세그먼트를 기준으로 하나만 설정된다. (Go-Back-N 방식에 가깝다)
이때 타이머가 종료되는 timeout 시간은 위에서 정리한 그 시간으로 정해진다.
- ACK를 수신한 경우
ACK를 수신한 세그먼트를 표시한 뒤, 윈도우를 슬라이딩 시킬 수 있다면 슬라이딩 시키고, 다시 어플리케이션으로부터 받을 메세지가 있다면 메세지를 받는다.
그리고 ACK를 받지 못한 전송한지 가장 오래된 세그먼트에 대해 타이머를 다시 설정한다.
- Timeout이 발생한 경우
만약 timeout이 발생하면 timeout이 발생한 그 세그먼트를 재전송하고, 다시 타이머를 시작한다.
이 내용을 FSM 으로 표기하면 아래와 같다.
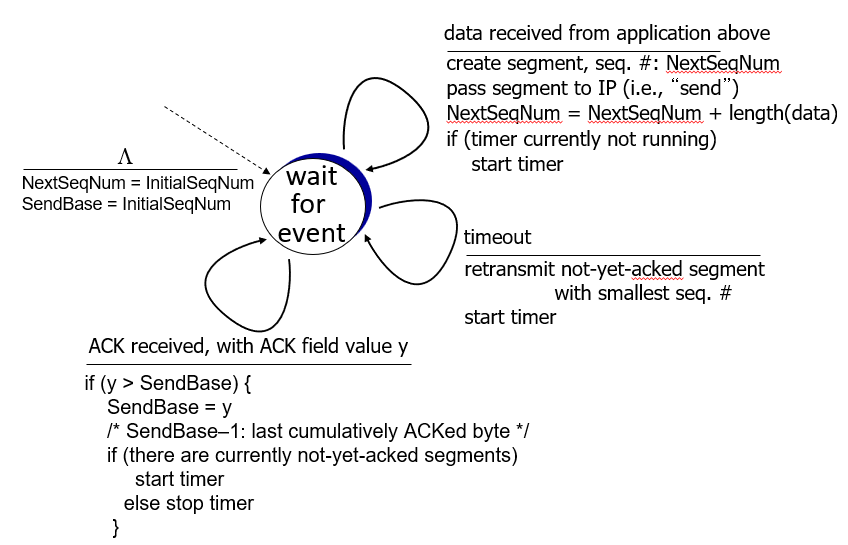
초기 상태에서는 initial seq num으로 next seq num 과 send base를 초기화 해둔다.
핸드 셰이킹을 해서 상대방과 약속한 초기 시퀀스 번호이다.
(정확히는 Initial Seq Number+1 에서 시작을 해야하지만 여기서는 그냥 Initial Seq Number 라고 표기했다.)
상위 어플리케이션으로부터 데이터를 받았다면,
NextSeqNum을 Seq Number로 하는 세그먼트를 만들고 IP에 세그먼트를 전달한다. Next Seq Number는 세그먼트에 들어있는 데이터 크기만큼 + 시키면 된다. (세그먼트의 크기 X)
그리고 타이머가 구동되고 있지 않다면 타이머를 구동시킨다.
만약 타이머가 expired 즉, 만료되어서 timeout이 발생했다면
ACK를 받지 못한 가장 오래된 세그먼트를 다시 보낸다.
(즉, ACK를 받지 못한 가장 작은 Seq 번호를 가진 세그먼트를 재전송한다.)
그리고 다시 타이머를 가동한다.
이 부분에서 한가지 의문점이 들었다.
왜 Go-Back-N 과 달리, Timeout 이 발생했을 때, 모든 unACKed 세그먼트를 재전송하는게 아니라, 가장 오래된 세그먼트 하나만 재전송하는걸까?

GPT 설명은 timeout 발생 == 네트워크 혼잡 상황 발생으로 간주하고, 세그먼트를 하나씩만 재전송한다고 한다.
그리고 가장 작은 Seq Number 의 세그먼트 이후에는 잘 도착했더라도, TCP는 순서를 중요시 여기므로 이를 처리하지 않아서 모두 보낼 필요가 없다라는 말을 한다.
우선 TCP의 혼잡제어는 이 장 뒷부분에 나오므로 그때 공부한 내용으로 다시 이해해서 적어보고자 한다.
(이때 추가 의문점, 가장 오래된 패킷만 재전송하고, 타이머를 다시 세팅하면, 그 다음으로 오래된 패킷에 대해서는 타이머가 의미 없어지지 않는거 아닌가 싶은데.. 이 부분도 고민을 좀 더 해봐야겠다.)
만약 ACK를 수신했고, 그 번호가 y 라면
1. y <= send base 라면, ACK번호는 잘 수신한 번호 + 1을 보내는 것이 TCP의 방식이므로 내가 보낸 데이터를 모두 받지 못했다는 의미이다. 따라서 아무것도 하지 않는다.
2. y > send base 라면, 내가 보낸 데이터 중 y-1까지는 잘 보내졌다는 의미이다.
따라서 send base 를 y까지 옮기도록 윈도우를 슬라이딩하고, 만약 아직 ACK를 받지 못한 세그먼트가 있다면 타이머를 다시 설정한다. 만약 그런 세그먼트가 없다면 타이머를 중지시킨다.
Receiver
receiver도 각 이벤트 별로 어떤 액션을 취하는지 살펴보자.
- 순서대로 도착한 세그먼트를 수신했을 경우 (in-order segment), 또는 이미 ACK를 보낸 세그먼트가 온 경우
세그먼트가 순서대로 왔다는 의미는 리시버가 기다리고 있는 순번의 세그먼트가 도착했다는 뜻이다.
이때 리시버의 선택지는 2가지이다.
1. 새로운 업데이트된 ACK를 즉각 보낸다.
2. 다음 순번의 세그먼트가 올 때까지 기다렸다가 한번에 ACK를 보낸다.
이때 TCP는 2번 방식을 취한다.
이를 delayed ACK 라고 한다.
약 500ms까지 다음 세그먼트를 기다려보고, 다음 세그먼트가 도착하지 않으면 그때 ACK를 보낸다.
순서대로 세그먼트가 잘 도착하고 있다면,그 다음 세그먼트도 잘 도착할 것이라고 예측할 수 있으니, 기다렸다가 한번에 ACK를 보내는 것이 receiver 입장에서는 더 편할 것이다.
TCP는 누적 ACK를 쓰기 때문에 이 방식이 잘 맞기도 하다.
(모든 세그먼트에 대해 ACK를 일일히 보낼 필요가 없다.)
따라서 만약 500ms를 기다리는 동안 새로운 in-order 세그먼트가 도착했다면, 그때는 두번째 세그먼트에 대해 누적 ACK를 전송한다. (여기에서 추가로 계속 기다리면 sender에서 timeout이 발생할 수 있으니 이제는 전송한다.)
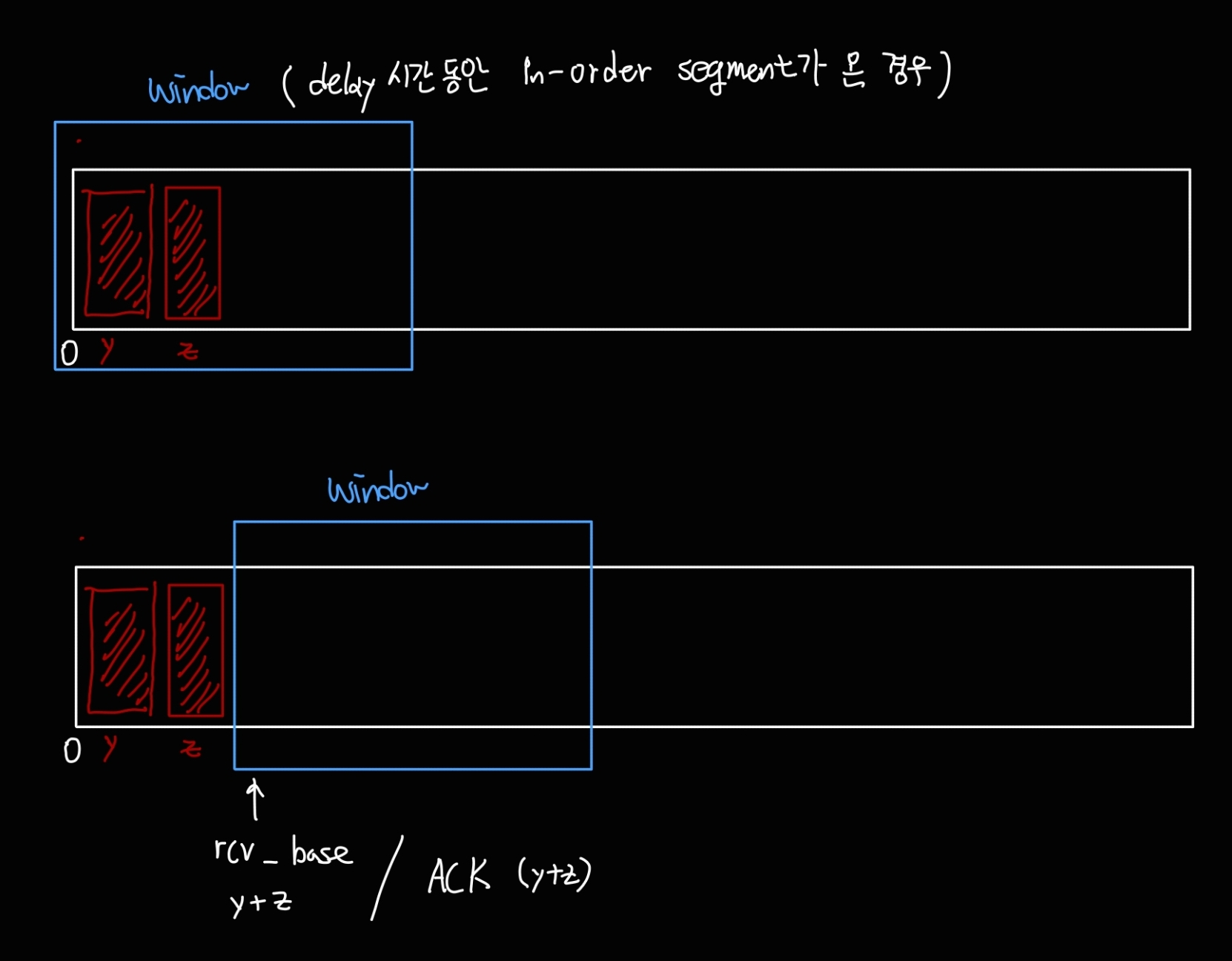

- 순서를 벗어난 세그먼트가 도착하는 경우
순서를 벗어난 세그먼트가 왔다는 뜻은, 현재 예측하고 있는 seq number보다 큰 번호가 도착했다는 의미이다.
(gap이 발생한 상황이다.)
이 상황에서는 즉각적으로 ACK를 보내며, ACK의 번호는 기다리고 있는 바이트의 seq 번호가 될 것이다.
즉, duplicate ACK를 보낸다. (Go-Back-N과 비슷)
이렇게 하는 이유는, 순서를 벗어난 세그먼트가 토착했다는 의미는 중간에 네트워크 상황에 문제가 발생했을 가능성이 있다는 뜻이다. (물론 라우팅 과정에서 세그먼트가 서로 다른 경로를 타고와서 뒷 순번 세그먼트가 먼저 도착했을 수도 있지만, 흔한 상황은 아니다.) 따라서 이 상황을 sender에게 신속하게 알리기 위해, 순서를 벗어난 세그먼트가 온 경우, sender에게 빠르게 상황을 알린다.
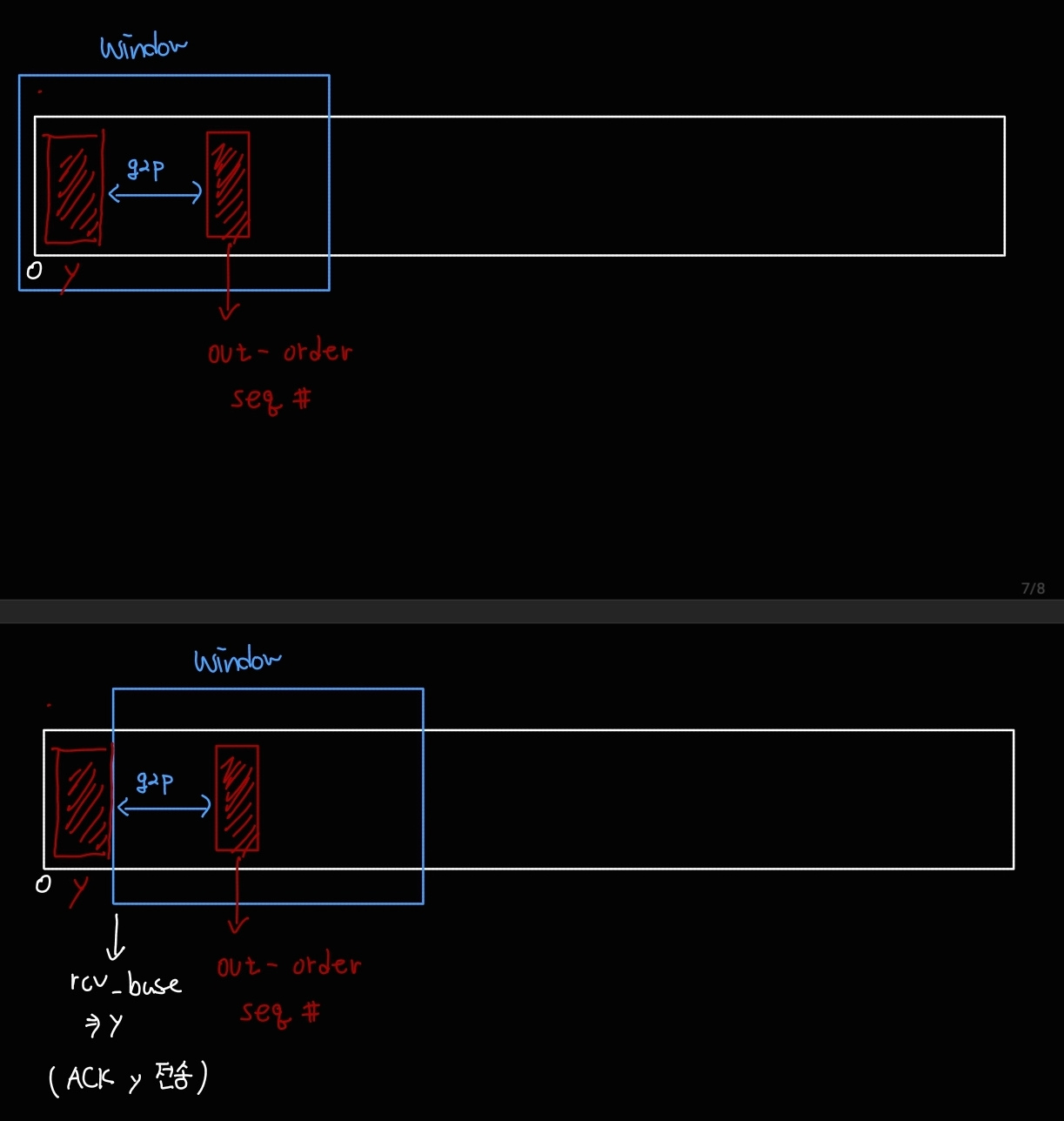
위 이미지는 delay 상황에서 순서를 벗어난 세그먼트가 온 경우, 즉각 ACK를 보내는 상황을 나타낸다.

이 상황에서 추가적으로 온 세그먼트도 여전히 순서를 벗어났다면, 즉각적으로 ACK를 보낸다.
이때의 ACK번호는 여전히 ACK y 가 된다. (duplicated ACK)
- gap을 채우는 세그먼트가 도착한 경우
순서를 벗어난 세그먼트가 도착하면, duplicate ACK를 보내면서도, 리시버는 도착한 세그먼트를 마킹해둔다.
이때 그 gap을 완전히 또는 부분적으로 채우는 세그먼트가 도착하면, TCP는 즉각적으로 ACK를 보내면서 윈도우를 슬라이딩한다. 그러면 추가로 윈도우에 공간이 생기기 때문에, 그 추가된 공간을 sender에게 알려줄 수 있다.
이때 보내는 ACK는 갭을 채우고, 슬라이딩한 후에 남아있는 gap의 낮은 번호 끝을 가리킬 것이다.

따라서 위 그림과 같은 상황이라면, ACK 번호는 y + y` + y`` + y``` 이 될 것이다.

그림과 같이 부분만 채우는 경우, 채워진 부분까지 슬라이딩하고, ACK번호는 y + y` 으로 전송한다.
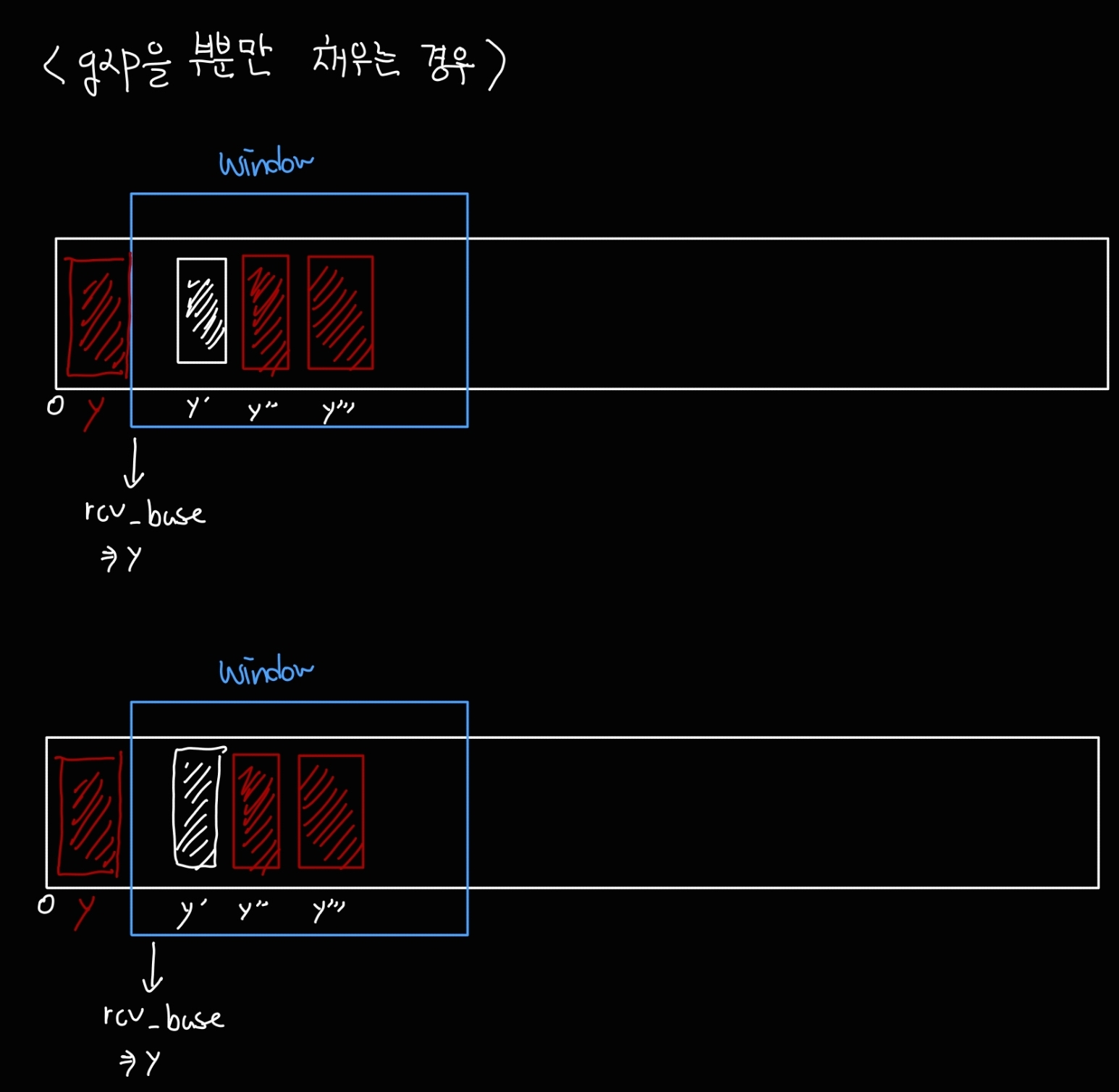
gap의 뒤쪽 일부를 채우는 경우에는 일단 갭이 메워졌으니 ACK를 보내기는 하지만 슬라이딩도 하지 않고, 자신의 rcv_base인 y를 여전히 ACK로 보낸다.
TCP 재전송이 발생하는 경우
1. ACK가 유실된 경우
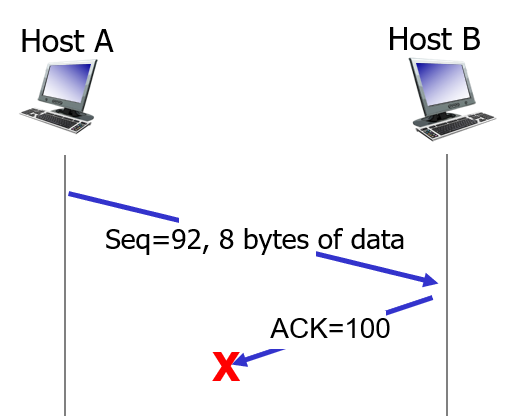
92 seq 번호로 8바이트의 데이터를 보내면, ACK는 100을 보낸다.
(92, 93, 94, ..., 99 까지 8개 데이터를 커버 후, 100번째 바이트를 수신하기를 원함)

만약 리시버는 데이터를 잘 받았는데 ACK가 중간에 유실된다면 사진과 같이 timeout 이벤트가 발생한 이후 다시 동일한 세그먼트를 보낼 것이고, 리시버는 이미 받은 데이터를 또 받았으므로 내가 받고자 하는 번호인 ACK 100을 보낼 것이다.
그리고 이 데이터는 상위 어플리케이션에서 이미 받아간 데이터이므로 올려보내지 않고 버릴 것이다.
2. ACK가 느리게 와서 premature timeout이 발생한 경우

기존과 유사한 시나리오이다.
이번엔 연속적으로 2개의 세그먼트를 보내는 상황을 생각해보자.
seq 92 에서 8byte를 보내고, seq 100 에서 20byte를 보냈고, Host B는 각각에 맞는 ACK를 보냈고, 모두 Host A 에 도착했다.
그런데 중간에 premature timeout이 발생했다고 해보자.

ACK 100을 받기 전에 timeout이 일찍 발생해버린 것이다.
이때 Host A 가 재전송한 세그먼트가 도착했을 때, Host B 입장에서는 seq 119까지 잘 받았고, 120번째 데이터를 받을 차례이다.
따라서 ACK 100 이 아니라, 자신이 받기를 기대하는 ACK 120을 전송한다!
Host A는 이미 ACK120을 받았으므로 send_base가 120으로 슬라이딩되었고, 이때 중복 ACK인 120을 받으면 윈도우를 슬라이딩할 필요없이 동일한 send_base로 둔다.
3. 여러 세그먼트 중 일부가 유실되었을 때

세그먼트를 여러개 보냈을 때, 위 사진과 같이 앞에서 보낸 세그먼트에 대한 ACK는 유실되고, 뒤에 보낸 ACK만 살았다고 해보자.
Host A 입장에서는 seq 92 에 대한 ACK는 받지 못했고, seq 100에 대한 ACK만 받은 상황이다.
이때는 어떻게 처리할까?
앞에서 못받은 ACK는 신경쓸 필요가 없으니 무시한다.
왜냐하면 ACK 120을 받았다는 의미 자체가, 119까지는 잘 받았고 이제 120을 받을 차례라는 뜻이기 때문이다.
만약 92에 대한 세그먼트가 Host B에 잘 도착하지 않았다면 ACK로 92가 왔을 것이다.
Fast retransmit

그림과 같은 상황을 생각해보자.
pipeline 방식으로 수많은 세그먼트를 전송하는 상황이다.
이때 seq 100 가 중간에 유실되었다고 해보자.

그러면 이후에 전송되는 3개 세그먼트에 대해서도 모두 동일하게 ACK 100이 전송될 것이다.
이를 통해 동일한 ACK 번호가 여러번 수신되면 중간에 세그먼트가 유실되었다는 것을 역으로 유추할 수 있다.
TCP는 이렇게 동일한 ACK번호가 연속으로 3번 들어오게 되면, loss가 발생했다고 간주하고,
timeout이 지나지 않았더라도 유실된 것으로 예측되는 세그먼트를 재전송한다.
( 유실된 것으로 예츠고디는 세그먼트 == ACK를 받지 않은 세그먼트 중 가장 작은 seq 번호를 갖는 세그먼트)
일단 중복해서 ACK가 오고 있다는 것은 내가 보낸 세그먼트가 receiver 에게 도착은 잘 하고 있다는 의미이면서, 중간에 gap이 발생했을 가능성이 크다는 것을 의미한다.
'CS > 컴퓨터 네트워크' 카테고리의 다른 글
| [컴퓨터 네트워크] 22. Transport Layer (8) : TCP 연결 설정 (3-way handshake) (0) | 2024.05.28 |
|---|---|
| [컴퓨터 네트워크] 21. Transport Layer (7) : TCP Flow Control (흐름 제어) (0) | 2024.05.28 |
| [컴퓨터 네트워크] 19. Transport Layer (5) : Go-Back-N (GBN), Selective Repeat (SR) (0) | 2024.05.24 |
| [컴퓨터 네트워크] 18. Transport Layer (4) : rdt 3.0 (0) | 2024.04.24 |
| [컴퓨터 네트워크] 17. Transport Layer (3) : rdt의 개념과 발전 (rdt 2.0 ~ rdt 2.2) (0) | 2024.04.21 |