Datapath
개요
이제 pipeline을 적용한 MIPS의 회로도를 그려보자.
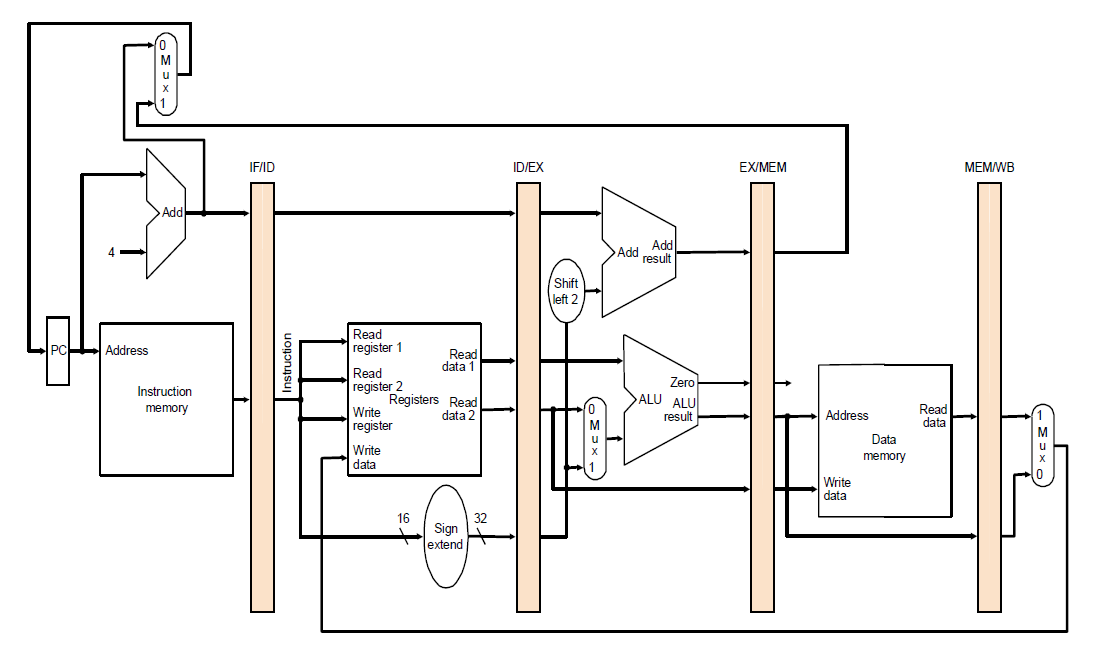
이 회로도는 j 명령어 (무조건 분기) 를 고려하지 않은 CPU 회로도이다.
먼저 단순하게 기존 single cycle 회로도에서 단계를 나눈 뒤, 단계 사이사이에 flip-flop(파이프라인 레지스터)을 넣어두었다. 하나의 스테이지 동작을 마친 뒤, 다음 스테이지에서 이어서 하기 위해 그때까지 수행한 값을 레지스터에 보관해두는 것이다.
각각의 파이프라인 레지스터 이름을 구분하기 위해, 어떤 단계 사이에 끼어있는 레지스터인지로 이름을 명시하였다.
이제 이 CPU는 동시에 최대 5개의 명령어를 처리할 수 있게 되었다.

예를 들면 위와 같이 특정 시점에서 5개의 명령어를 동시에 실행하고 있을 수 있다.
이 그림에서는 분홍색으로 색칠한 명령어가 제일 먼저 실행되었던 명령어일 것이다.
add명령어는 이제 막 instruction memory로부터 읽어들여져서 IF/ID 파이프라인 레지스터에 쓰여지고 있다. (왼쪽 색칠)
이때 다음 사이클의 라이징 엣지보다 setup 타임 만큼 빠르게 이미 쓰여지고 있다.
이때 IF/ID 파이프라인 레지스터가 내뱉은 명령어는 lw 명령어이다.
(이때 하나의 레지스터에 읽고 쓰기가 동시에 되는게 이해가 안되어서 질문했는데, 파이프라인 레지스터를 구성하는 flip flop은 D flip-flop 이다. 이때 D flip-flop은 D포트로 입력으로 받고, Q포트로 데이터를 내보내는 구조를 갖는데, 자신의 래치에서는 Q를 내보내고, D를 입력으로 받고 있다고 보면 된다고 한다. 조합회로처럼 들어온 값이 바로 나오는 것은 아니다. 다음 사이클이 되어야 이때 받은 D를 Q로 내보낸다.)
lw & sw 명령어의 실행과정

이번에는 명령어 하나가 실행되는 전체 흐름을 따라가보자.
먼저 IF 단계에서는 PC가 가리키는 주소값을 이용해 Instrunction Memory에서 명령어를 가져온다.
가져온 명령어는 IF/ID 파이프라인 레지스터에 보관한다.
그런데 IF/ID 파이프라인 레지스터에는 명령어만 보관되는 것이 아니다.
명령어를 가져오면서 연산해둔 PC + 4 값 역시 보관하고 있다.

그래서 이미지를 보면 알 수 있다시피, 레지스터에 들어오는 화살표가 2개이다.
따라서 32bit의 PC + 4 데이터 역시 추가로 저장하고 있다.
이 값을 저장하는 이유는 혹시 branch 명령어를 만나는 경우, 건너갈 주소를 계산해야 하기 때문에 필요하다.

이번엔 다음 사이클이 되어서 ID 단계가 되었다고 해보자.
그러면 IF/ID 파이프라인 레지스터에서 명령어를 가져온 뒤, 명령어를 해석해서 레지스터파일에 저장된 값을 가져온다.
만약 I 포맷이라면 sign extend까지 진행한다.
지금 가져온 명령어는 lw 명령어라고 가정하고 있으므로, t1 레지스터의 데이터가 rd1 으로 들어가고, 8 이라는 상수값은 sign extend 될 것이다.
그리고 s0 레지스터 번호는 write register 번호로서 들어간다.
그리고 이 과정에서 가져온 데이터, extend 된 상수는 모두 ID/EX 파이프라인 레지스터로 들어간다.
그리고 PC+ 4 값 역시 그대로 들어간다. EX 단계에서 필요하기 때문이다.
(아직 쌓인 것은 아니고 들어가고 있다.)
그런데 사실 지금 이 그림에서 잘못된 부분이 있다.
바로 write register 번호를 IF/ID 단계에서 가져오는 것이다.
지금 당장은 이게 맞는 것처럼 보이지만, 다음 스테이지로 넘어가게 되면 Write Register에는 그 다음 명령어에 적힌 rt 또는 rd 위치의 레지스터 번호가 들어오므로 lw 명령어에 기술한 레지스터 본호와 다른 번호가 들어온다.
이를 고친 회로도는 뒤에서 다시 보도록 하겠다.

EX 단계에서는 이전에 레지스터에서 읽어왔던 값들을 토대로 ALU 연산을 수행한다.
lw 명령어를 실행하므로, immediate 필드와 rs 레지스터의 값을 더해서 메모리의 주소를 계산할 것이다.
그 값은 EX/MEM 파이프라인 레지스터로 들어간다.

이전 스테이지에서 계산한 주소값을 이용해 메모리에서 값을 읽으면, 이 값을 MEM/WB 파이프라인 레지스터에 들여보낸다.
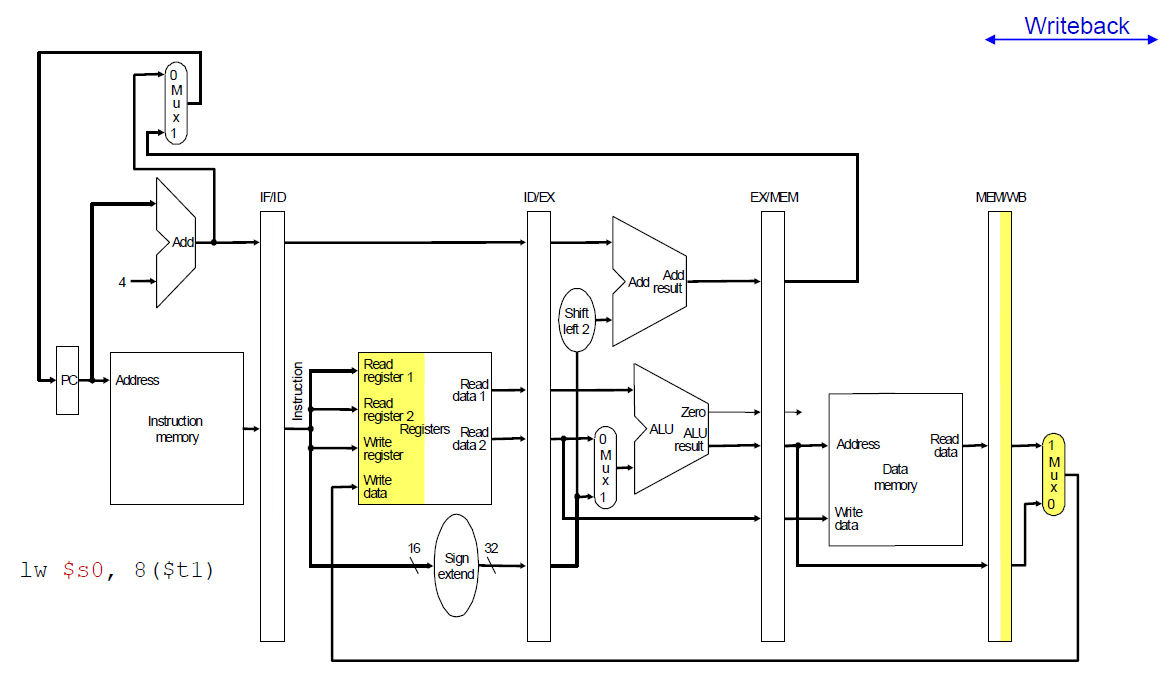
마지막 WB 단계에서는 메모리에서 읽은 값을 가져와 레지스터에 쓴다.
이때 이 그림은 아까 말한대로 잘못되었다.
이 회로대로라면 지금 시점에서 Write Register 에 들어오는 레지스터 번호는 lw 명령어에 기술했던 레지스터 번호가 아니라 현재 ID 단계에 있는 명령어에서 가져온 레지스터 번호가 들어온다.

따라서 이렇게 고치는 것이 맞다.
Write Register로 들어올 번호 값은 당장 들여보내는게 아니라 WB 단계까지 가서 쓰이므로, 그때까지는 이 5bit 값을 파이프라인 레지스터에 계속 보관하다가 WB단계에서 계속 보관했던 이 값을 가져다가 사용하도록 한다.
만약 sw 명령어를 실행한다면, 메모리에 접근하는 주소값을 계산하는 EX 스테이지까지는 동작이 똑같을 것이다.

차이점은 메모리에서 데이터를 읽어오는게 아니라 쓰는 동작을 하므로 색칠만 왼쪽에 하도록 바뀐다.
또 WB 스테이지는 일단 시간적으로는 거치기는 하겠지만, 아무 동작도 수행하지 않는다.
레지스터에 값을 업데이트할 게 없기 때문이다.
Control
개요
이제 이 회로도에 control 신호가 포함된 회로도 개요를 살펴보자.

기존 회로도에 주황색으로 control 신호들을 추가하였다.
이 모든 신호들은 Instruction Deocde 단계에서 샐성되는 신호들이다. 다만 배치할 때는 각 신호가 실제로 사용되는 스테이지에 배치하였다. (Reg Write 제외)
따라서 이 모든 신호들은 ID 단계에서 생성된 이후, 실제로 쓰일 때까지는 계속해서 파이프라인 레지스터에 보관되어야 한다.
(근데 PC Src는 첫번째 스테이지에서 쓰이는거 아닌가..?
→ 일단, PC Src는 ID 에서 생성하는 게 아니라, Branch, Zero 의 조합으로 4번째 스테이지에서 생성되는 신호이므로 '사용 시점' 기준으로 배치하는 신호에서 제외했다고 이해하였다.)

위 그림과 같이, 각 스테이지에서 필요한 신호들을 파이프라인 레지스터에 보관한다.
이때 기존의 single cycle과 다르게 추가된 컨트롤 신호가 존재한다.
ALU Op 신호 (ALU Control 자체가 추가되었다.) 와 Mem Read 신호 이다.
그림에서 PC Src 라는 신호를 4번째 스테이지에서 생성하고 있음을 알 수 있다.
그런데 사실 Zero 신호는 3번째 스테이지에서 생성되고, Branch 신호는 2번째 스테이지에서 바로 알 수 있다.
그럼에도 4번째 스테이지에서 만든 이유는 그냥 디자인 선택으로 4번째에서 생성하도록 하였다.
3번째 스테이지에 넣는 것이 약간의 시간단축이 있기는 하지만, 이렇게 디자인한 이유는 크리티컬 패스를 분산할 수 있기 때문이다.
만약 and 게이트가 세번째 스테이지에 들어간다면, 세번째 스테이지에서 1클락 사이클에 해야하는 일이 ALU 연산과 더불어 and 게이트 연산까지 추가로 해야하기 때문에, critical path의 길이가 길어지게 된다.
따라서 이 딜레이를 분산시켜주기 위해 4번째 스테이지로 미룬 것이다.
이를 정리하면 아래와 같다.

각각의 신호들이 어떤 스테이지에서 사용되는지를 나타낸 것이다.
RegWrite는 사용되는 시점은 WB 스테이지이지만, 배치 자체는 ID stage에 되어있다.
이렇게 총 8개의 (비트로는 9bit, ALU op 가 2비트이므로) 신호가 있다.

Single Cycle MIPS 컨트롤 신호를 정리했던 진리표 모습이다.
여기에서 각 컨트롤 신호 bit 들이 어떤 단계에서 사용되는지를 추가로 분류하면 위와 같다.

최종적으로 컨트롤 신호들이 생성된 이후 파이프라인 레지스터에 보관되는 과정을 포함하여 묘사하면 위와 같이 그릴 수 있다.
예시

처음에 IF 단계에서 lw 명령어를 가져온다.
가져온 명령어는 파이프라인 레지스터에 저장한다.
PC + 4 값도 파이프라인 레지스터에 저장한다.

그 다음 클럭사이클의 모습이다.
IF 단계에서는 새로운 명령어 sub 를 가져왔다.
ID 단계에서는 파이프라인 레지스터에서 가져온 lw 명령어를 해석하여 레지스터 파일에서 데이터를 읽고, sign extend 한 뒤 파이프라인 레지스터에 데이터를 저장한다.
이떄 명령어를 해석해서 얻은 control 신호들도 파이프라인 레지스터에 보낸다.
중요한 것은 RegWrite 신호는 바로 가져다가 쓰는게 아니라, WB 단계까지 계속 보관했다가 마지막에 WB 단계에서 갖고와서 쓰는 것이다.

EX 단계에서는 ID/EX 파이프라인 레지스터에 담긴 컨트롤 신호 값을 읽어서 실행한다.
이때 sub 명령어를 해석하는 ID 단계에서는 ID/EX 파이프라인 레지스터에 새로운 컨트롤 신호값을 보낸다.

메모리에 값을 읽어온다. 이때 MemRead 신호가 활성화되어야 읽어올 수 있다.
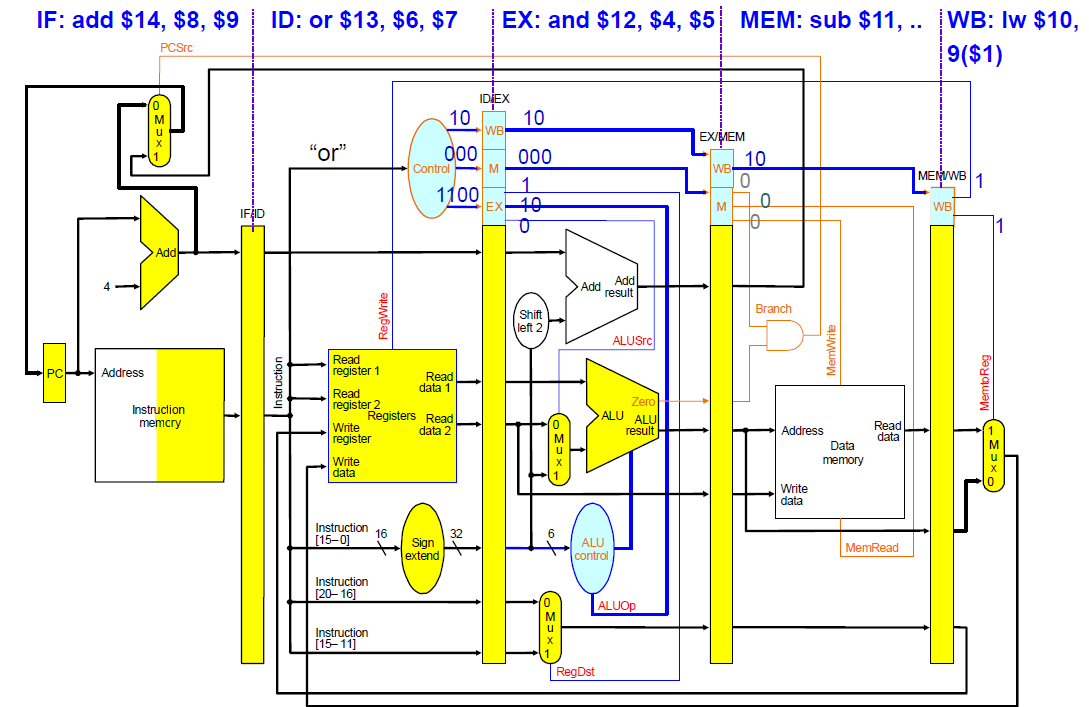
메모리에서 읽은 값을 레지스터에 쓴다.
이후 명령어들도 비슷한 과정을 거쳐 실행된다.
'CS > 컴퓨터 구조' 카테고리의 다른 글
| [컴퓨터 구조] 21. Pipeline MIPS (5) - 회로 개선 (Control Hazard) (0) | 2024.06.02 |
|---|---|
| [컴퓨터 구조] 20. Pipeline MIPS (4) - 회로 개선 (Data Hazard) (0) | 2024.06.02 |
| [컴퓨터 구조] 18. Pipeline MIPS (2) - Hazard (0) | 2024.05.30 |
| [컴퓨터 구조] 17. Pipeline MIPS (1) - 기본 아이디어 (1) | 2024.05.30 |
| [컴퓨터 구조] 16. Single Cycle MIPS - 성능 (0) | 2024.05.29 |