명령형 언어는 변수가 중요하다.
이때 변수는 6가지 속성을 가질 수 있었다.
address, name, value, type, scope, lifetime 이다.
이번 글에서는 이 중 type 에 대해 자세히 정리하려고 한다.
Data Type
데이터 오브젝트와, 그 오브젝트들에 대해 미리 정의된 연산들을 모은 collection을 정의한 것을 말한다.
descriptor는 변수의 attributes 의 collection을 말한다.
하나의 오브젝트는 사용자 정의 타입의 인스턴스를 나타낸다.
모든 데이터 타입에 대한 설계시 문제는 어떤 연산들을 정의해야 하는지, 그리고 이들의 동작을 어떻게 명시할 것인지가 중요하다.
과연 이것이 필요한 데이터 타입인가, 어떤 오퍼레이션이 필요한가, 어떻게 이들을 정확하게 표시할 것인가를 고민해야 한다.
Primitive Data Type
거의 모든 프로그래밍 언어는 primitive data types 의 집합을 제공한다.
primitive data type은 다른 데이터 타입들을 이용해서 정의되지 않는 타입들을 말한다.
(예를 들면 문자열 타입은 문자타입에 기반해서 정의될 수 있으니 primitive data type이 아님)
대다수 primitive data type은 하드웨어 자체에서 제공한다.
(reflections sof the hardware), 그리고 소수의 primitive 데이터 타입은 하드웨어가 제공하는 타입에 약간 기능을 추가해서 만드는 경우도 있다.
Integer
거의 모든 하드웨어 (CPU) 가 integer type을 제공한다.
언어에 따라 8가지의 서로 다른 정수형 타입이 존재하기도 한다.
(자바의 경우, byte, short, int, long)
Floating Point
마찬가지로 많은 하드웨어가 부동소수점 타입을 지원한다.
(과거 CPU는 지원하지 않기도, 요즘도 일부러 지원 안하는 경우가 있다고 한다. 하드웨어가 많이 필요하기 때문.)
부동소수점은 실수를 모델링하지만, 정확하지는 않을 수 있다.
과학적 목적으로 사용되는 언어는 최소한 float, double 2가지 타입을 지원한다.
그리고 더 많은 타입을 지원하기도 한다.
float, double 은 보통 하드웨어에서 지원하는 타입이다.
이 실수표현에 대한 표준은 IEEE Floating Point Standard 754에서 명세하고 있다.
Complex
일부 언어는 복소수 타입도 지원한다. (C99, Fortran, Python..)
복소수 각각의 값은 두 float 으로 구성되며, 각각 실수, 허수를 나타낸다.
파이썬에서는 literal form 이 존재한다.
(7 + 3j) 와 같이 복소수를 표현할 수 있다.
Decimal
회사에서 사용하는 비즈니스 어플리케이션의 경우 Decimal 타입을 지원하기도 한다.
(COBOL, C# 등)
예를 들면, 미국에서는 1달러, 100센트와 같은 단위를 사용한다.
10진수 자릿수 제한을 둔 BCD 라는 형태로 인코딩을 해서 저장한다.
따라서 돈을 표현할 때 달러를 표시하는 부분과 cent를 표시하는 부분을 분리해야 한다.
그래서 정확성을 높이는 대신 범위가 제한되고 메모리가 낭비되는 특징을 가진다.
예를들어 100센트를 표현할 때는 0부터 99센트만 나타내면 되므로, 7bit가 필요하다.
(7bit로 128까지 나타낼 수 있으니까)
그런데 128을 다쓰는게 아니라 99까지만 쓰니까 7bit를 써도 약간의 메모리 낭비가 발생한다.
Boolean
제일 단순한 타입이다.
True, False 2가지 형태의 데이터로 구성된다.
bit로 표현될 수도, bit로 표현하면 괜히 시간이 많이 소요돼서 그냥 byte로 표현하는 경우도 있다.
boolean 타입은 readability를 높이는 장점이 있다.
수학적으로는 True, False는 논리적으로 동등하기 때문에 비교할 수 없다.
따라서 프로그래밍 언어에서는 이 둘 사이의 순서를 정할 때 프로그래밍 언어 설계자가 직접 정한다.
Character
문자는 컴퓨터에 저장될 때 숫자로 구성된 코드로 저장된다.
과거에 자주 사용하던 인코딩 방식으로 ASCII 인코딩 방식이 있다.
이 문자는 알파벳과 특수기호 몇개만 표현할 수 있어서 부족하다고 느껴졌기 때문에 16-bit를 사용하는 Unicode가 등장했다. (UCS-2 에 정의, ISO에서 표준을 제정)
이 코드는 더 많은 언어에서 사용할 수 있도록 대부분의 언어가 사용하는 문자들을 포함한다.
주로 Java에서 많이 사용한다.
그런데 한글, 한자와 같이 정말 많은 종류의 문자를 필요로 하는 경우를 지원해야 하는 문제가 생겼다.
그래서 이를 위해 32-bit Unicode (UCS-4) 가 등장했다.
2003년 부터 포트란이 지원하기 시작했다.
String
Character를 나열한 값이다. (그래서 문자의 나열 순서에 따라 문자열 간에도 순서가 존재한다. Lexicographical order )
이때 문자열을 어떻게 디자인 할 지 고민이 생겼다.
- 문자열은 primitive 타입인가, 아니면 그저 character 타입의 array 형태인가
- 문자열의 길이를 정적으로 정해놔야 하는가, 동적으로 자유롭게 늘릴 수 있도록 해야하는가
문자열 타입은 일반적으로 아래와 같은 연산을 지원한다.
- 할당, 복사
- 비교 (=, > 와 같은 연산)
- 합성 (catenation)
- 서브스트링 참조
- 패턴 매칭
언어별 문자열 타입
C/C++ : primitive가 아님. cahr 배열을 활용하며 문자열 연산은 라이브러리로 제공한다.
SNOBOL4 : primitive, 패턴매칭을 포함한 많은 연산이 있다.
Fortran, Python : Primitive, 할당 연산을 포함해 몇가지 연산을 더 지원한다.
Java, C#, Ruby, Swift : String 클래스를 이용해 Primitive 타입으로 지원한다.
Perl, JavaScript, Ruby, PHP : 내장 패턴 매칭, 정규표현식 기능을 제공한다.
문자열 길이
Static : COBOL, Java의 String 클래스는 문자열 길이가 정적으로, 컴파일 타임에 결정되면 변하지 않는다. 즉, 변수의 attribute , distribute가 정해진다.
Static Length의 경우, compile-time descriptor가 정해준다. (descriptor = 변수에 어떤 attribute를 모아둔 것)
즉, 스트링 타입이 나오면 디스크립터가 컴파일 타입을 정해준다.
길이가 변하지 않기 때문에 컴파일할 때 길이가 얼마다! 하고 딱 정해주면 된다.
Limited Dynamic : C, C++ 의 경우, 실행중 길이가 변할 수 있지만 제한적이다. \0 문자를 사용해 문자열 끝을 나타내고, 문자열 길이 정보를 갖지 않는다.
run-time descriptor 가 길이를 정해줄 필요가 있다.
(하지만 C, C++은 아니다.)
Dynamic (최대 제한 x) : SNOBOL4, Perl, Javascript
run-time descriptor가 필요하며, 문자열 길이를 늘이고 줄이는 복잡한 과정을 거쳐야 하기 때문에 메모리 할당/반환을 반복하고, 기능을 구현하는데 많은 어려움이 있다.
String type은 writability 에 도움을 주기 위해 존재하는 타입이다.
만약 static length를 가지고 있다면 기능을 제공하는데 많은 비용이 들지 않지만, 그렇다면 굳이 이걸 primitive로 제공할 필요가 있냐는 의문이 들고, Dynamic Length는 좋지만, 만드는데 비용이 많이 들어가는 단점이 있다.

다음은 compile-time descriptor, run-time descriptor 의 구조를 나타낸 사진이다.
컴파일 타임은 문자열, 길이, 문자열이 저장된 주소만 있으면 충분하다.
하지만 런타임은 현재 문자열에서 가질 수 있는 최대 길이, 현재 길이, 주소, 지금 문자열 내용과 같은 정보가 저장되어야 한다.
Ordinal Types
ordinal type은 문자타입의 값들이 인티저와 1:1 매칭되면 이를 ordinal type 이라고 한다.
interger는 그 자체로 순서가 정해져있다.
따라서 integer에 매핑하면 어떤 값들의 순서를 정할 수가 있다.
integer는 그 자체로 정해져 있고, 자바는 이에 더해 char, boolean 타입도 정수와 매핑해서 순서가 정해져있다.
Enumerated Type
이름이 있는 constant 를 가리킨다.

C# 에서는 위와 같이 사용할 수 있다.
enum 타입을 설계할 때 발생할 수 있는 고민은 다음과 같다.
- enum 타입이 한가지 형태로만 나타날 수 있는지
- 모든 enum 타입이 정수와 매핑되어야 하는지
- 정수 이외의 타입과 매핑될 수 있는지
Enum은 readability에 도움을 준다.
즉, 색깔을 숫자로 적을 필요가 없다!
또 reliability에 도움을 준다. (컴파일러가 체크할 수 있다.)
그래서 연산에 제한을 둔다거나 (색상과 색상을 더한다거나 하는 동작을 못하게 막는다.)
enum 타입은 그 타입 변수에만 할당되도록 제한할 수 있다.
C++에서는 enum이 정수랑 1:1로밖에 매핑되지 않는 문제가 있어서 C#, F#, Swift, Java 5.0 은 더 많은 기능을 지원한다.
(꼭 하나의 정수에 1:1로 매핑되지 않아도 되도록, 즉, 순서가 없도록)
Array
배열은 다음과 같은 특징을 갖는다.
1. 같은 타입들의 데이터들로 구성된다.
2. 모여서 집합을 이룬다.
3. 순서가 있다. 따라서 배열에 대한 접근은 몇번째 원소에 가겠다는 숫자를 주어야 접근할 수 있다.
배열을 설계할 때 고민하는 내용들은 다음과 같다.
- 배열의 subscript 로 적절한 타입은 무엇인가? -100 ~ 100 으로 해도 되는가?, 실수로 해도 되는가
- subscripting expressions 에 대해서 연산결과에 대해 그 범위를 체크해야 하는가? (C언어는 체크하지 않음)
- 언제 subscript 의 범위가 결정되는가? (bound 되는가)
- 언제 실제로 배열이 메모리를 할당하는가
(범위가 결정되면 메모리를 할당할 것이다. 그런데 컴파일 시점에 결정되는지, 런타임에 결정되는지에 따라 다를 것이다.)
- 2차원 배열, 들쭉날쭉한 다차원 배열 모두 지원하는가? 일부만 지원하는가? 몇차원까지 지원할 것인가?
- 배열의 subscript 최대값은 무엇인가
- 배열을 초기화 할 수 있는가
- slice를 지원하는가
Array Indexing
인덱싱 (또는 subscripting) 은 index (indice)로부터 element를 매핑하는 것이다.
인덱스가 꼭 하나라는 법은 없다. 파이썬에서 보듯, 여러개가 동시에 지정되어도 된다.
그래서 index_value_list를 주면, 해당하는 elements 들이 여러개 나올 수도 있다.
대부분의 언어는 [ ] 를 사용하지만, Fortran, Ada는 ( ) 를 사용한다.
그러면 subscript 에는 어떤 것을 쓸 수 있을까?
Fortran, C 는 정수만 사용할 수 있었고, Java 는 정수 타입만 사용할 수 있다.
C, C++, Perl, Fortran은 인덱스 범위를 체크하지 않는다.
Java, ML, C#은 범위를 체크한다.
Subscript Binding & Array Category
배열의 실제 메모리 공간을 언제 할당하는지에 따라 4가지로 분류할 수 있다.
1. Static
인덱스 범위가 정적으로 바인딩되고, 저장공간 할당도 정적으로 런타임 이전에 된다.
런타임에 주소를 계산하고 메모리를 할당/반납하는 과정이 없으므로 효율적으로 실행할 수 있다는 장점이 있다.
2. Fixed stack-dynamic
배열을 스택 메모리에 저장한다.
인덱스 범위는 컴파일 타임에 정적으로 바인딩 되지만, 저장공간은 선언되는 시점에 할당된다.
메모리 공간의 효율성이 생기는 것이 장점이다.
예를 들어 함수 안에서 배열을 선언하면, 함수가 실제로 실행될 때 배열을 위한 메모리 공간을 스택에 할당하게 된다.
3. Fixed Heap-dynamic
함수의 실행이 종료되면 배열 내부 값들이 모두 사라지므로, 스택이 아니라 heap에 저장할 수도 있다.
heap에 저장할 때는 런타임에 메모리 공간이 할당된다.
하지만 배열의 크기가 바뀌지 않기 때문에 fixed 이다.
즉, fixted stack-dynamic 과 유사하게, 실제로 메모리 공간이 할당되는 것은 할당 요청이 발생했을 때 스택 대신 힙에 메모리를 할당한다. 메모리가 한번 할당되고 나면 그 뒤로는 고정된다.
4. Heap-dynamic
인덱스의 범위, 저장공간의 할당 모두 동적으로 발생하며, 배열의 크기가 언제든 변할 수 있다.
유연성이 증가하는 장점을 갖는다.
배열의 크기가 프로그램이 실행되는 중간에 증가하거나 감소할 수 있다.
[실제 언어 예시]
C/C++ : static 키워드로 선언한 배열은 static 이다. static 이 없으면 fixed stack-dynamic 이다. 물론 fixed heap-dynamic도 지원한다. 이때는 프로그래머가 직접 메모리를 할당/해제하는 것을 신경써야한다.
C# :fixed heap-dynamic 으로 동작하는 ArrayList 라는 second array class 를 추가로 지원한다.
Perl, JavaScript, Python, Ruby : heap-dynamic array를 지원한다.
배열 초기화
C/C++, Java, Swfit, C# 은 배열 초기화를 저장공간을 할당하는 시점에 할 수 있도록 허용한다.
C#은 int list [] = {4, 5, 6,8}; 과 같이 선언과 동시에 초기화할 수 있다.
C/C++ 은 char name [] = "hi"; 와 같이 초기화할 수 있다.
char * names [] = {"hi" "bye"}; 와 같이 초기화할 수 있다.
Java는 String[] names = {"hi", "bye"}; 와 같이 초기화할 수 있다.
파이썬은 리스트 축약을 사용해서 초기화 할 수 있다.
Heterogeneous Array
여러 데이터형이 뒤섞여 들어갈 수 있는 배열을 말한다.
Python, Perl, JavaScript, Ruby 와 같은 언어가 지원한다.
인터프리터 언어가 쉽게 지원할 수 있다.
Array Operations
APL은 벡터, 행렬을 위해 배열을 다루는 가장 강력한 연산자들을 제공한다.
이항연산자 말고도 단항 연산자도 제공한다.
벡터 곱셈 (내적, 외적), 역행렬을 구하는 연산 (단항 연산자) 등을 지원한다.
(하지만 단점이 많아서 잘 안쓰인다고 한다.)
파이썬은 배열 할당을 지원하지만, 참조에 대한 변화만 일어난다.
배열과 배열을 합치는 catenation, elment membership을 지원한다.
루비도 배열을 합치는 catenation을 지원한다.
(사실 파이선, 루비는 애초에 dynamic array length를 지원해서 가능한 것이다.)
Rectangular & Jagged Arrays
Rectangualr array는 다차원 배열로, 모든 row가 같은 수의 원소를 갖고, 모든 column이 같은 수의 원소를 갖는, 정말 직사각형 모양의 다차원 배열을 말한다.
Jagged Array는 다차원 배열인데, 각각의 row가 가진 원소의 수가 다를 수 있는 배열을 말한다.
예시로, 문자열은 문자 타입을 모은 1차원 배열이다.
이때 문자열의 배열에 대해, 각 문자열의 길이가 제각각이면 Jagged Array이다.
따라서 C, C++, Java는 jageed array를 지원한다.
F#, C#은 rectangular array, jaged array 모두 지원한다.
Slice
슬라이스는 큰 배열을 잘라서 일부분만 가져온 뒤, 그 부분 어레이가 새로운 배열인 것처럼 쓰는 것을 말한다.
큰 배열을 잘라서 일부에 대해 연산을 하면 연산속도가 빨라지기 때문에 사용한다.
이걸 지원하도록 할 때는 인덱스를 조작해서 인덱스끼리 매핑만 해줄 수 있으면 된다.
(referencing mechanism)
그냥 슬라이스만 제공하는 것은 당연히 의미가 없고, 슬라이스된 배열에 대해 배열 연산을 쓸 수 있도록 지원해야 의미가 있다.
파이썬은 [:] 를 이용해서 리스트 슬라이싱을 할 수 있고, 루비는 slice 메소드를 사용해서 슬라이싱할 수 있도록 지원한다.
PL1 이라는 언어도 String, array 에 대해 매우 많은 연산을 지원하지만 언어가 너무 커서 문제가 많아 잘 안나온다.
Array Implementaion
배열에 인덱스를 넣었을 때, 요소가 나오려면, 이 요소들은 메모리에 저장이 되어 있어야 한다.
그럼 인덱스를 주었을 때 메모리의 주소를 계산할 수 있는 메커니즘이 필요하다.
1차원 배열의 경우, address ( list [k] ) = address( list[ lower_bound ] ) + ( ( k - lower_bound ) * element_size ) 방식으로 구한다.
예를 들면 &array[0] + (i-0)*sizeof( int ) 와 같은 방식이다.
2차원 배열의 경우, base address + ((i - row_lb) * n + (j - col_lb)) * element_size 의 형식으로 계산한다. (1-index)
이 계산 방식은 row-major, column-major 방식에 따라 달라진다.
row-major 는 대부분 언어에서 사용하는 방식으로, column 이 변하는 순서대로 메모리에 차곡차곡 쌓다가, column을 다 저장하면 그 때 row 인덱스가 증가하는 방식이다.
column-major 는 column을 고정하고 row가 변할때마다 메모리의 주소가 1칸씩 채워지는 방식이다.
Fortran이 해당한다.
2차원 배열의 주소값을 계산하는 것은 1차원보다 덧셈, 뺄셈, 곱셈의 양이 늘어났다.
차원이 늘어날 수록 주소값 계산은 복잡해지며, 보통 차원의 제곱 정도에 비례해서 올라간다.

이 그림은 다차원 배열에 대한 compile-time descriptor 이다.
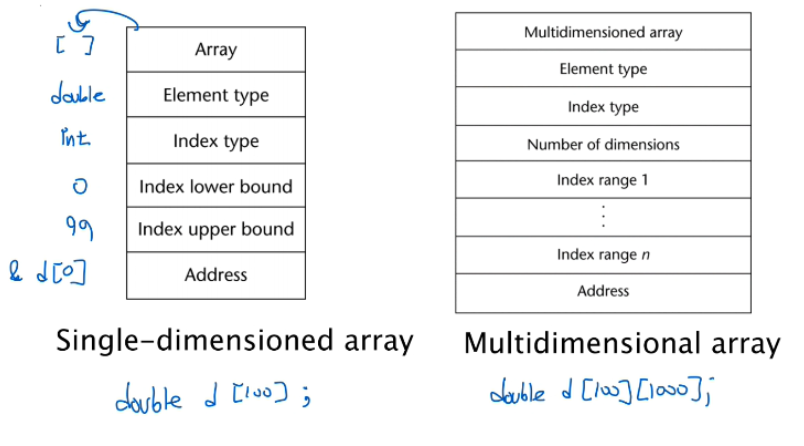
1차원, 다차원 배열에 대한 Compile-Time Descriptor의 예제는 위와 같다.
Associative Array
배열의 인덱스로 정수 이외에 우리가 원하는 값으로 넣는 것을 말한다. (key)
Associative Array는 순서가 없는 데이터의 집합으로, key와 key에 연관된 값 (associative value) 가 나온다.
만약 사용자 정의 key를 사용한다면, 이 키들은 어딘가에 저장이 되어 있어야 한다.
그렇다면 인덱스 없이 어떻게 key를 통해서 value가 나오도록 구현할 수 있을까?
사이즈는 static할까 dynamic할까? 와 같은 고민을 할 수 있다.
Perl, Python, Ruby, Swift 같은 언어들이 내장 타입으로 지원한다.
Perl 에서는 Associative Array 이름이 % 로 시작한다.
인덱싱은 { } 를 사용해서 하고, 원소를 지울 때는 delete 키워드를 사용한다.
(컴퓨터 구조에 이와 비슷하게 Associative Memory 라는게 존재한다.. 아마 캐시를 말하는게 아닐까)
Record
C언어의 Struct 에 해당하는 것
서로 다른 데이터 타입들 (heterogeneous aggregate)이 묶여서 각 요소들에게 이름이 붙여 식별되는 것을 말한다.
이 타입을 설계할 때 고려할 점은 아래와 같다.
- 각 필드에 접근하기 위한 문법적 형태는 무엇인가
- 중간 단계를 생략할 수 있는가

코볼은 level number 를 사용해서 중첩된 레코드를 표현한다.
다른 언어들은 보통 재귀 정의를 사용한다.

코볼은 OF 키워드로 중첩된 필드에 접근한다.
보통 다른 언어들은 . 을 이용해서 접근한다.
이걸 매번 나열해서 쓰는 것이 불편하기 때문에, COBOL에서는 Elliptical reference 는 뒤에 있는 필드 이름에 대해, 그 필드 이름이 프로그램 전체에서 유일하면 그냥 바로 접근해서 쓸 수 있도록 허용한다.
Record 타입과 Array 타입을 비교해보자.
레코드 타입은 데이터 타입이 서로 다른 것들이 섞일 때 사용한다.
물론 배열도 heterogeneous 할 수도 있지만, 이렇게 구성하면 인덱스로부터 메모리를 계산하는데 시간이 오래 걸린다.
하지만 레코드는 필드에 접근할 때 직접 static한 필드명을 통해서 접근하므로 더 빠르게 접근할 수 있다.
레코드에서도 동적으로 레코드의 멤버를 다이나믹하게 만들 수 있는데, (런타임에 멤버를 추가/삭제)
static할 때 얻던 속도의 이점을 잃게 되고, 실행시간에 체크해야 하는 문제가 생긴다.

다음 그림은 레코드에 대한 descriptor의 모습이다.
각 필드에는 offset 데이터가 있어서 address로부터 그 offset을 더한 것으로 메모리 위치를 파악한다.
Tuple
튜플은 레코드와 비슷한데 필드의 이름이 없고, 배열과 비슷한데 homogenious 한 타입이 아니다.
파이썬, ML, F# 등의 언어에서 함수가 여러개 데이터를 반환할 수 있도록 하기 위해 사용한다.

ML, F# 에서 튜플을 사용하는 예제이다.
List
LISP, Scheme 에서 사용하는 리스트는 데이터가 괄호로 감싸져있고, comma를 사용하지 않는다.
데이터와 코드가 모두 같은 형태를 가지기 때문에, 인터프리터는 이게 데이터인지 아닌지 파악할 필요가 있다.
따라서 데이터를 나타낼 때는 ` 를 이용해서 데이터를 표시한다.
Scheme 에서 리스트에 대한 연산으로는 CAR, CDR, CONS 와 같은 연산이 있다.
CAR은 인자로 들어온 리스트의 첫번째 원소를 반환한다. (카)
CDR은 첫번째 원소렐 제외한 나머지 리스트를 반환한다. (쿠다)
CONS는 첫번째 인자를 두번째 인자로 들어온 리스트에 추가하여 새로운 리스트를 만든다. (콘즈)
ML 에서는 리스트를 표현할 때 [ ] 를 사용하며 각 원소를 , 로 구분한다.
리스트 원소는 모두 같은 타입을 갖고 있어야 하며, ML에서는 CONS 대신 :: 를 이용하여 원소를 리스트에 추가한다.
스킴에서는 CAR, CDR 이 각각 hd, tl 이라는 이름으로 사용된다. (head, tail)
F#에서는 모든 원소를 ; 으로 구분하고, hd, tl 은 list 클래스의 메소드로 제공한다.
파이썬에서는 리스트가 파이썬의 배열과 같다.
파이썬 리스트는 다른 함수형 언어와 다르게 mutable 하다는 특징이 있다.
원소는 어떤 타입이든 들어갈 수 있고, assignment 를 이용해 리스트를 생성한다.
0-index를 사용해 인덱싱하여 원소에 접근할 수 있고, del 키워드로 리스트 원소를 지울 수 있다.
파이썬은 set notation에서 기반한 리스트 축약 문벱을 제공한다.
Haskell, F#도 리스트 축약이 존재한다.
C#, Java는 각각 generic heap-dynamic collection class 인 List, ArrayList를 사용해 리스트를 제공한다.
12-2 = type theory
Union
같은 메모리 공간을 서로 다른 타입이 사용하는 것을 말한다.
당연히 동시에 쓰는 것은 불가능하고 서로 번갈아가면서 사용한다.
Union type을 사용할 때는 타입이 계속 바뀌는 것이 고민거리다.
그래서 타입 체킹을 하기 힘들어서 프로그래머가 신경을 많이 써야 한다.
ML, Haskell, F#은 타입 체킹을 제공한다.
따라서 discriminant 라는 타입 인디케이터를 사용해야 한다.


그림에서 보는 것과 같이 F#은 변수 옆에 IntValue 17 과 같은 식으로 타입을 명시하며 선언한다.
IntValue, RealValue 가 discriminant 역할을 하는 동시에 constructor 역할도 한다.
반면 C, C++은 타입체킹을 제공하지 않는다.
이런 union 을 free union 이라고 한다.
F#은 union 값에 접근할 때 pattern matching을 사용한다.
패턴은 어떤 데이터 타입이든 들어갈 수 있다.
또 각각의 expression list는 _ 라는 wild card를 가질 수 있다.

x 에는 apple, grape, fruit 중 하나의 값이 매칭이 되어 들어갈 것이다.
Free Union은 타입체킹을 하지 않기 때문에 위험하다.
Java, C# 은 그래서 Union을 지원하지 않는다. 대신 오브젝트 클래스의 형태로 제공한다.
Pointer & Reference
Pointer
포인터 타입의 변수는 크게 2가지 종류의 데이터가 들어간다.
1. 실제 메모리 주소
2. 아직 메모리 주소가 정해지지 않았음 (nil 또는 null)
메모리를 동적으로 관리하는 방법을 제공하고, heap 메모리 영역 (동적으로 생성된 공간) 에 접근하는데 사용된다.
포인터를 사용할 때 고려할 점은 다음과 같다.
- 포인터 변수의 스코프와 lifetime
- heap-dynamic 변수의 lifetime
- 포인터가 가리킬 수 있는 값의 타입에 제한이 있는가?
- dynamic storage management, indirect addressing 으로 사용될 수 있는가?
- 언어가 포인터 타입을 지원해야 하는가? 참조 타입을 지원해야 하는가? 둘 다 해야하는가?
포인터 연산
포인터는 2개의 기본적인 연산을 지원한다.
1. assignment (사용할 수 있는 메모리 주소를 할당하는 것)
2. dereferencing (포인터가 가리키는 주소의 값을 읽어오는 것)
dereferencing은 명시적일 수도, 암시적일 수도 있다.
C++은 * 연산자를 통해 명시적으로 값을 읽어온다.
포인터를 사용할 때 문제
1. Dangling Pointers
포인터가 할당이 해제되어 없어진 heap-dynamic 변수를 가리키는 상황이다.
2. Lost heap-dynamic varialbe
2개의 포인터가 같은 오브젝트를 가리키는 경우이다.
하나의 포인터가 기존 공간을 가리키고 있다가 새로 할당된 공간을 가리켰는데, 기존에 할당된 공간이 반환되지 않아서 그 공간을 가리키는 포인터가 없는 경우, memory leakage 가 발생한다. (garbage라고도 함)
C, C++ 에서는 매우 유연하게 포인터를 사용할 수 있지만, 그 만큼 조심해야 한다.
포인터는 어떤 주소값이든 가리킬 수 있다. (언제, 어디가 할당되었는지 상관없이)
dynamic storage management, addressing 을 위해 사용된다.
포인터의 산술 연산이 가능하다.
명시적 dereferencing 과 address-of operators 를 지원한다. (*, &)
Domain Type 은 고정될 필요가 없다.
(void * 는 어떤 타입도 가리킬 수 있고, 타입 체킹도 될 수 있다. 하지만 dereferenced 될 순 없다.)
참조 타입
C++은 reference type 이라는 특별한 종류의 포인터 타입을 갖는다.
주로 파라미터에 사용되어 pass-by-reference, pass-by-value 의 이점을 모두 갖는다.
자바는 C++의 참조타입을 확장하여 전체적으로 포인터를 바꿀 수 있도록 허용한다.
참조는 주소에 대한 참조가 아니라 오브젝트에 대한 참조이다.
C#은 자바의 참조와 C++의 포인터를 모두 포함한다.
Dangling pointer 와 dangling object 는 heap management에 있어 문제가 된다.
포인터는 goto 문과 비슷하게 변수로 접근할 수 있는 메모리의 범위를 넓힌다.
포인터나 참조는 모두 동적 자료구조에 필수적이라, 이것 없이 언어를 설계할 순 없다.
큰 컴퓨터는 하나의 값을 사용하고, 인텔 CPU는 segemnt 와 offset을 사용한다.
Dangling Pointer 문제에 대한 대처 방법은 크게 2가지가 있다.
1. Tombstone
heap-dynamic variable을 가리키는 포인터로서, 추가적인 heap cell 을 사용한다.
실제 pointer 는 단순히 tombstone을 가리키고 있다.
heap-dynamic 변수가 반환되면, tombstone은 남아있지만 nil로 세팅된다.
시간과 공간적인 비용이 추가된다.
2. Locks-and-keys
Pointer 값들이 (key, address) 쌍으로 저장된다.
Heap-dynamic 변수들은 변수 + integer lock value 에 대한 cell 을 모두 활용하여 나타낸다.
heap-dynamic 변수가 할당되면 lock value 가 생성되어 lock cell 과 pointer의 key cell 모두에 저장된다.
Heap Management 는 매우 복잡한 런타임 과정으로, Single-size cell 또는 variable-size cell 을 다룬다.
garbage를 처리하기 위해 2가지 방법이 있다.
1. Reference counters (즉각적인 접근방법)
그때그때 발생할때마다 collection 한다.
모든 cell에 대해 counter를 두고, 현재 그 셀을 포인팅하는 포인터 변수의 개수를 카운팅한다.
포인팅이 0이 되면 즉시 반환하는 방식이다.
장점은 본질적으로 증분식이기 때문에 어플리케이션 실행 시 큰 딜레이를 피할 수 있다.
단점은 메모리 공간이 추가로 필요하고, 프로그램 실행 시간이 늘어나며, 각 메모리 공간이 둥글게 연결된 경우, 추가적인 문제가 발생할 수 있다.
2. Mark-sweep (lazy approach)
garbage 회수가 변수 공간 리스트가 비었을 때 진행된다.
런타임 시스템이 storage cell에 대한 요청이 들어오면 할당하고, 필요할 때 포인터를 cell로부터 연결을 끊는다.
모든 heap cell 은 collection algorithm 을 위해 추가적인 bit를 가는다. (mark bit)
모든 셀들은 처음에 garbage로 세팅되어 있다.
모든 포인터들은 heap을 추적하고, 포인터가 가리킬 수 있는 변수들은 garbage가 아니라고 mark 되어 있다.
모든 garbage cell 은 이용가능한 cell 리스트에 반환된다 (sweep)
단점은 original 형태에 대해, 매우 드물게 발생한다는 점이다.
이 알고리즘이 수행되면, 어플리케이션 실행시 큰 딜레이를 유발한다.
현재의 mark-sweep 알고리즘은 이 문제를 피하기 위해 더 자주 가비지 콜렉팅을 한다.
이 방식을 incremental mark-sweep 라고 부른다.
variable-size cell (가변크기 셀)
단일 크기 셀 (single-size cell) 이 갖고있는 어려운 점에 추가적인 어려운 점을 갖는다.
대부분의 프로그래밍 언어들이 필요로 하며, mark-sweep 방식을 사용하여 가비지 콜렉팅을 하는 경우, 추가적인 문제가 발생할 수 있다.
- heap 내에 있는 모든 셀에 대한 초기 세팅이 어렵다.
- marking process가 복잡하다.
- 이용가능한 변수 셀 공간 list를 관리할 때 추가적인 오버헤드가 필요하다.
Optional
옵셔널 타입은 변수에 아무런 값이 없다는 것을 알리고 싶을 때 사용하면 유용하다.
C#, F#, Swift 가 옵셔널 타입을 지원한다.
C#의 참조 타입은 기본적으로 옵셔널 타입이다. 아무 값이 없을 때 null을 사용하기 때문이다.
C#의 값 타입 (struct 타입) 은 ? 표시를 붙여서 옵셔널로 선언할 수 있다.
int ? x; 와 같이 선언하면 된다.
아무런 값이 없음을 의미하는 값은 null 이며, 위 예시의 x에 할당될 수 있다.
x역시 null 을 갖는지 확인할 수 있다.
Swift는 nil을 대신 사용한다.
Type Checking
타입 체킹은 연산자와 피연산자의 개념을 서브프로그램과 할당까지 일반화한다.
타입 체킹은 연산자와 피연산자들이 서로 같이 쓰일 수 있는 compatible type 이라는 것을 보장하는 작업이다.
compatible type 이라는 것은 연산자가 허용하거나, 언어가 암묵적으로 형변환을 해서 연산이 허용되는 것을 말한다.
(언어가 암묵적으로 변환하는 것을 coercion 이라고 한다.)
타입 에러는 적절하지 않은 피연산자에 대해 연산자가 내는 에러이다.
만약 모든 타입 바인딩이 static 하면, 거의 모든 타입 체킹이 static 할 것이다.
만약 타입 바인딩이 dynamic 하면 타입 체킹은 반드시 dynamic하다.
하나의 프로그래밍 언어가 strongly typed 라는 뜻은, type error 가 항상 발견된다는 뜻이다.
(즉, 런타임에 타입관련으로 죽지 않는다.)
strong typing 의 장점은 잘못 사용된 변수를 찾아내서 타입 에러를 낼 수 있다는 것이다.
C/C++은 이를 지원하지 않는다.
union 타입도 지원되지 않고, 파라미터 타입 체크도 하지 않을 수 있다.
Java, C#은 거의 지원한다. (명시적 형변황 때문에 반드시 지원하진 않음)
ML, F#은 지원한다.
강제 형변환 규칙은 (coercion rules) strong typing 에 영향을 많이 준다.
이 규칙은 strong typing을 꽤 약하게 만들 수 있다. (C++ 과 ML, F# 의 차이를 생각하자.)
Name Type Equivalence
두 변수가 같은 선언 안에 있거나 같은 이름의 타입으로 선언되었다면 같은 타입을 갖는다는 것을 의미한다.
int a, b; 또는 int a, int b;
구현하기는 쉽지만, 매우 제한적이다.
어떤 배열에 대해 그 배열보다 작은 크기의 subrange 는 정수형과 같은 타입이 아니다.
일반적인 파라미터는 실제 파라미터와 일치해야 한다.
Structure Type Equivalence
두 타입이 동일한 구조를 갖고 있다면 두 변수가 같은 타입을 갖고 있다는 것을 의미한다.
조금 더 유연하지만 구현이 어렵다는 단점이 있다.
Type Equivalence
두 structured types 의 문제를 생각해보자.
두 레코드 타입이 만약 구조적으로 같지만 다른 필드 네임을 사용한다면 같은 타입이라고 볼 수 있을까?
두 배열 타입이 같은 크기를 갖는데, 인덱스 범위가 1-index, 0-index만 다르다면 같다 볼 수 있을까?
두 enum 타입을 구성하는 각각의 컴포넌트가 다르게 이름이 지어져있어도 같은 타입으로 볼 수 있을까?
structural type equivalence 에서 같은 구조의 타입 사이에서 차이점을 구분할 수 없다.
Type Theory
그래서 type theory 를 사용한다.
type theory 는 수학, 논리학, 컴퓨터과학, 철학에서도 사용된다.
컴퓨터 과학에서는 두개로 분류되는데, Practical, Abstract 이다.
우리가 주로 사용하는 건 practical type theory 이다.
상업적 언어의 데이터 타입들을 다루는 이론이다.
abstract type theory는 lambda calculus 와 같은 분야가 신경쓴다.
type 시스템은 type과 그에 대한 규칙들로 이루어진 집합이다.
프로그래밍언어의 반이 syntax, 반이 symantics라면, 시멘틱스의 반이 type이라고 볼 수 있다.
타입 시스템을 결정하기 위해 프로그래밍 언어의 디자이너는 굉장히 많은 고민을 해야 한다.
그래서 Attribute Grammar 도 데이터 타입에 대한 이론에 들어가고, finite mapping, cartesian products, set unions, subsets 들이 타입을 결정하기 위해 사용되는 언어들이다.
요약
데이터 타입은 프로그래밍 언어의 스타일과 프로그래밍 스타일에 많은 영향을 준다.
숫자 문자 불린 정도는 CPU에서 하드웨어적으로 지원을 해준다.
subrange type, enumeration type 은 프로그래밍을 편하게 만들어주고 readability, reliability를 높여준다.
배열과 레코드는 많은 언어가 갖고 있다.
포인터는 주소 처리 유연성과 메모리 동적 관리에 사용되지만 많은 문제를 야기한다.
하지만 자료구조를 만들 때 포인터는 필수적이었다.
'CS > 프로그래밍언어론' 카테고리의 다른 글
| [프로그래밍언어론] 12. Expression & Assignment Statements (0) | 2024.06.13 |
|---|---|
| [프로그래밍언어론] 11. Logic Programming Language (Prolog) (0) | 2024.06.13 |
| [프로그래밍언어론] 9. 함수형 언어 (LISP) (0) | 2024.06.12 |
| [프로그래밍언어론] 8. Name & Binding (0) | 2024.06.12 |
| [ Lex/Yacc ] 내가 만든 테스트케이스 (테스트 파일 포함) (0) | 2024.05.08 |