개요

위 그림은 전체 디스크를 나타낸 그림이다.
디스크의 앞부분에는 MBR 이라는 부분이 있고, 그 뒤에 partition table 이 있다.
파티션 테이블 뒤에는 파티션들이 존재하며, 각각의 파티션에는 실제 파일과 디렉토리가 저장되어 있다.
이때 각 파티션은 독립된 하나의 파일 시스템을 갖는다.
MBR(Master Boot Record)은 컴퓨터를 부팅할 때 사용한다.
파티션 테이블의 엔트리 하나는 하나의 파티션과 매핑되어 있으며, 각 파티션의 시작 / 끝 주소 정보를 갖고 있다.
파티션 중에 하나는 반드시 active 라는 마킹이 되어있고, 이 파티션이 부팅하는 파티션이다.
(윈도우에서 운영체제가 들어있는 부팅 디스크를 지정하는 것과 비슷하게 생각하면 아해가 된다.)
컴퓨터를 부팅하는 과정을 살펴보면
1. 롬에 들어있는 BIOS (Basic Input Output System)를 읽고 실행하면, BIOS는 MBR를 읽고 실행한다.
2. MBR은 partition table을 보고 active partition을 찾은 뒤, 해당 파티션의 첫 번째 블록을 읽고 실행한다.
3. 이 첫 번째 블록을 Boot Block 이라고 부르며, 이 블록에 들어있는 프로그램은 active 피티션에 들어있는 운영체제를 불러와 실행한다.
(BIOS는 메인보드에 들어있는데, 최근에는 BIOS의 개념이 사라지고, UEFI 가 등장했으나, BIOS가 일종의 펌웨어와 같은 말처럼 쓰이는 방향으로 남았다고 한다.)
각각의 파티션의 구조를 다시 살펴보면
Boot Block 이후에 Superblock은 파일 시스템과 관련된 키 파라미터를 저장한다.
(파일 시스템 타입을 식별할 수 있는 Magic Number, 파티션을 구성하는 블록의 개수 등)
Free Space Management 는 Free Block(비어있는 블록)에 대한 정보를 비트맵 또는 리스트로 저장한다.
I-node 는 (디렉토리도 파일이므로 포함하여) 파일 하나를 나타내는 구조로, 파일의 속성, 내용이 저장된 디스크 블록 주소들을 저장한다.
그 뒤에는 루트 디렉토리 파일이 위치하며, 그 뒤에는 루트 디렉토리 하위의 실제 파일과 디렉토리들이 저장된다.
File 구현 방법
운영체제에서 파일을 구현할 때는 논리적 개념인 파일과, 물리적 개념인 디스크 블록을 어떻게 매핑시킬 것인지 고민하는 것이다.
즉, 파일의 실제 내용을 어느 디스크 블록과 어떻게 매핑할 것인지 고민해야 한다.
이제부터 파일을 구현하는 4가지 주요 방법에 대해 정리해본다.
Contiguous Allocation
이름 그대로 연속적인 할당, 하나의 파일에 연속적인 디스크 블록을 할당하는 방법을 말한다.

위 그림에서 (a)는 A부터 G 까지 7개의 파일을 디스크에 저장한 모습을 보여준다.
파일 A는 4개의 디스크 블록을 필요로 하기 때문에 4개의 연속된 디스크 블록으로 할당한 것을 볼 수 있다.
이때 파일 D와 파일 F를 삭제하면 (b)와 같은 모습이 되며, 5개, 6개의 free block이 생긴다.
이 방법의 장점은 파일의 시작 block 주소와 파일을 구성하는 블록의 개수만 알면 파일 내용을 쉽게 가져올 수 있으므로 구현이 간단하다는 점이다. 또한 파일을 구성하는 내용이 모두 연속된 블록에 존재하므로, 읽기 성능이 좋다는 장점도 있다.
하지만 단점도 있다.
위 그림의 (b) 에서 본 것처럼 중간에 파일을 생성하고 삭제하는 과정을 반복하면 중간 중간 free block 이 생기면서 점점 조각조각 나눠지는 것처럼 보이게 된다. 조각이 생기면 파일을 하나 생성할 때, 그 파일의 최종 크기를 예측할 수 없으므로 어디에 생성할 지 위치를 결정하는 것이 추가적인 고민점이 되고, 그에 따라 모든 파일을 디스크의 한쪽 블록으로 몰아서 저장하는 것 역시, 그 작업을 하는 동안에는 파일을 쓸 수 없다는 문제가 있다.
이 방법은 제일 원시적인 파일 구현 방법이지만, 읽기 성능이 매우 좋다는 장점 덕분에 CD-ROM 에서 주로 사용한다.
ROM 자체가 읽기 전용 메모리라는 뜻이므로 쓰기 성능보다 읽기 성능이 중요하기 때문이다.
(하드디스크에서는 안 쓴다.)
Linked List Allocation

이 방식은 파일을 저장할 때 필요한 디스크 블록을 연속된 배열 형태가 아니라 링크드 리스트 형태로 구성해서 저장하는 방법이다.
파일의 하나의 블록은 물리적 블록의 데이터와 더불어 그 다음 블록의 주소를 함께 저장하며, 마지막 블록의 경우 주소에는 0을 저장한다.
이 방법의 장점은 fragmentation 이 발생하지 않고, 디렉토리가 보유한 파일 정보를 저장하는 디렉토리 엔트리에도 파일 디스크 블록의 시작 주소만 저장하면 된다는 장점이 있다. (연속된 블록에 할당했다면 블록의 개수와 같은 정보도 함께 저장해야 한다.)
이 방법의 단점은 연결 리스트의 단점인 랜덤 액세스에 약하다는 단점을 그대로 갖는다.
파일의 중간 위치를 읽고 싶다면 무조건 처음 위치부터 시작해서 타고 들어가야만 하는 것이다.
특히 연결된 디스크 블록 주소와 같은 정보는 메모리가 아니라 디스크에 저장되어 있기 때문에 디스크 I/O가 반복적으로 일어나므로 더 느리다.
또한 디스크 블록은 기본적으로 2의 거듭제곱 꼴의 크기를 갖는데, 연결 리스트 방식은 포인터를 저장해야 하기 때문에, 실제로 저장하는 데이터는 2의 거듭제곱의 크기가 되지 않을 수 있다.
예를 들면 물리적인 디스크 블록 하나의 크기는 1024 byte 인데, 주소 포인터로 4byte를 사용해서 실제 데이터는 블록당 1020 byte만 쓸 수 있는 것이다.
그런데 보통 프로그램에서는 2의 거듭제곱 단위로 데이터를 읽어오도록 하기 때문에, 만약 프로그램에서 1024 만큼의 데이터를 읽어왔다면 이 방식에서는 1020 파이트 크기의 데이터와 그 다음블록에서 4 byte 만큼의 데이터를 읽어오게 되어 2개 블록의 데이터를 읽어오는 불편함이 생긴다.
Linked List Allocation (using FAT in memory)
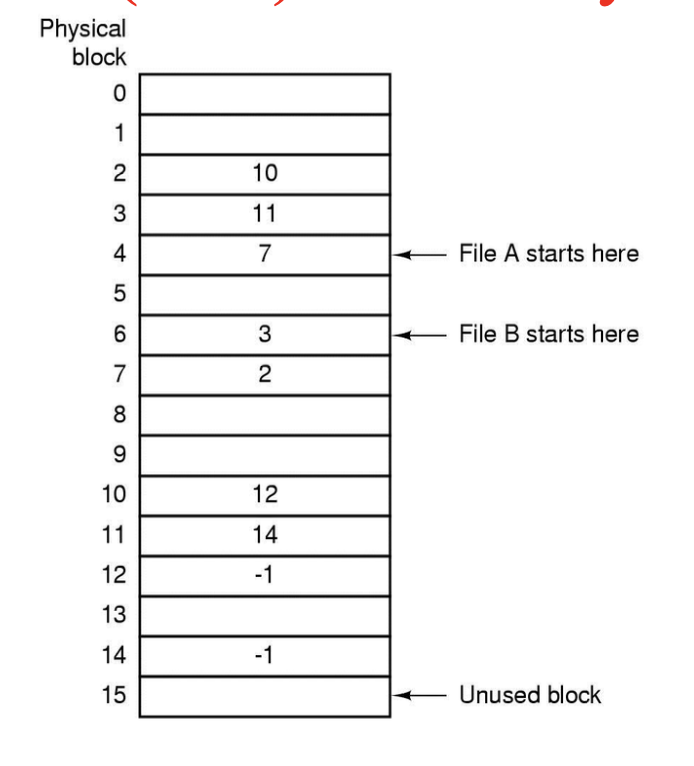
이 방법은 똑같이 연결리스트를 사용하되, FAT (File Allocation Table) 라는 테이블을 메모리에 올려둔다.
위 그림이 FAT의 모습을 보여준다.
만약 File A 에 접근해서 읽는다면, File A의 스타팅 포인트로 이동한다. (physical block 4에 있다.)
이 엔트리가 가리키는 값 7은 다음 디스크 블록의 물리 주소를 나타낸다.
다시 7번 엔트리로 가면 2가 저장되어 있고,
2번 엔트리로 가면 10이 저장되어 있고,
10번 엔트리로 가면 12가 저장되어 있고,
마지막으로 12번 엔트리로 가면 -1이 저장되어 이 블록이 파일의 마지막 블록임을 나타낸다.
FAT을 사용하는 방법의 장점은 다음과 같다.
먼저 FAT은 메모리에 올라와있기 때문에 기존의 링크드 리스트를 사용한 방법과 비교했을 때 비교적 빠르게 파일의 내용을 읽어올 수 있다.
따라서 기존의 링크드 리스트보다 Random Access가 빠르다.
또한 디스크에는 더 이상 다음 블록의 주소 정보가 들어가지 않으므로 2의 거듭제곱 형태로 온전하게 데이터를 저장할 수 있다.
그러면서도 기존의 링크드 리스트와 마찬가지로 디렉토리 엔트리에는 File이 시작하는 디스크의 블록 번호만 저장하면 된다.
반면 FAT의 단점은 이 테이블 자체가 디스크의 모든 블록과 1대1로 매핑이 되어야 하기 때문에, 디스크의 크기가 커질수록 FAT의 크기도 커진다. 그런데 FAT은 항상 메모리에 올라와 있어야 하므로 디스크 크기에 비례하여 메모리를 많이 차지하는 문제가 있다.
I-node (★)

I-node(index node)는 유닉스 운영체제에서 사용하는 파일 구현 방법이다.
아이노드는 파일 하나를 나타내는 구조로서, 파일의 속성들이 들어있고, 그 다음에는 파일을 구성하는 디스크 블록들의 주소가 들어있다.
위 그림에서는 8개 블록에 대한 주소를 저장할 수 있는데, 만약 파일의 크기가 커서 8개 블록보다 많은 블록 주소를 저장해야 한다면 그때는 블록 주소를 저장하는 추가 공간을 만들고, 마지막 엔트리에 그 공간을 가리키는 주소 값을 저장한다.
(그림에서 맨 아래에 있는 칸에 해당한다.)
결국 I-node는 실제 데이터가 아니라, 실제 데이터가 저장된 블록의 주소들을 저장하도록 모아둔 구조이다.
그래서 위의 개요에서 본 이미지를 보면 I-node 와 root directory 옆에 실제 파일과 디렉토리 데이터가 저장된 공간이 파티션 내에 별도로 존재한다.
I-node 방식의 장점은 FAT과 비교했을 때, 운영체제에서 지원하는 한번에 열 수 있는 파일의 개수에 비례해서 메모리를 차지하므로 메모리를 더 효율적으로 사용할 수 있다는 장점이 있다.
예를 들어, 한번에 50개의 파일만 열 수 있다면, 실제 메모리에 불러오는 I-node의 개수는 최대 50개 인 것이다.
(원래 i-node는 하드디스크에 저장되어 있지만, 파일을 열고 조작할 때는 i-node를 메모리에 불러온다.)
따라서 위 예시에서 I-node 크기가 1KB 라면, 메모리에는 최대 50KB 만큼만 I-node가 차지한다.
Directory 구현 방법

디렉토리를 구현하는 방법은 운영체제마다 조금씩 다르다.
먼저 (a) 방식은 Simple Directory 라는 MS-DOS, Windows 에서 사용하는 디렉토리 구현 방법으로, 고정된 크기의 디렉토리 entry에 파일 이름, attribute, 디스크 주소 등을 저장한다.
(b) 방식은 UNIX 운영체제에서 사용하는 방법으로, 파일 이름과 I-node 번호를 저장한다.
파일에 대한 자세한 내용은 i-node를 타고 들어가서 읽으면 알 수 있다.
두 방법은 파일에 대한 자세한 정보를 직접 적을 것인지, i-node를 통해 적을 것인지는 다르지만, '파일 이름'을 명시한다는 점은 같다.
이때 엔트리 크기에 제한이 있다면 저장할 수 있는 파일 이름의 길이에도 한계가 있을 것이다.

파일 이름은 2가지 방법으로 저장할 수 있다. 위 그림은 디렉토리 파일을 자세히 표현한 것이다.
먼저 기본적으로 디렉토리 파일은 디렉토리 엔트리로 구성되어 있다는 점을 생각하면서 그림을 보자.
(a) 방법은 하나의 파일에 대해 파일 엔트리의 길이, 파일의 속성, 파일 이름 순으로 저장한 것을 반복한다.
이 방법은 이름을 엔트리 중간에 저장하기 때문에 in-line 방식이라고 부른다.
이렇게 저장하면 파일의 이름 길이에 따라 하나의 파일을 나타내는 디렉토리 엔트리의 크기도 제각각 달라진다.
또한 파일 이름을 저장할 때는 반드시 워드 단위로 공간을 확보해야 하므로, 낭비되는 공간이 조금씩 생긴다.
거기에 만약 디렉토리 내에서 파일이 삭제되면, 해당 엔트리 공간이 비면서 구멍이 생긴다.
이때 빈 공간으로 다른 엔트리들이 옮겨오지 않으므로, 더 긴 이름의 파일을 저장하려고 하는 경우에는 기존에 비어있는 엔트리 공간이 작아서 저장할 수 없어, hole이 점점 생겨나는 문제가 존재한다.
(b) 방법은 모든 파일에 대해 이름을 가리키는 포인터와 파일의 속성을 저장하는 필드를 저장하여 모든 파일에 대해 같은 크기의 엔트리를 저장한다. 그리고 파일 이름은 힙 영역에 저장한다.
이 방법은 파일 이름을 저장할 때 워드 단위로 저장해야 하는 제약도 없고, 파일을 삭제했다가 새로운 파일을 저장할 때도 기존에 비워진 엔트리에 그대로 저장할 수 있으므로 (a) 방법보다 더 좋다.
Shared File
마지막으로 Unix 운영체제에서 link를 통해 파일을 공유하는 방법을 살펴보자.

유닉스 운영체제는 위 그림과 같이 C 유저가 소유한 파일을 B와 공유해서 볼 수 있도록 하는 기능이 존재한다.
파일을 공유할 때는 링크를 통해서 공유할 수 있다. (윈도우의 바로가기와 비슷한 느낌이다.)

링크에는 하드링크와 소프트 링크 (또는 symbolic link) 가 존재하는데, 위 그림은 하드 링크의 예시를 보여준다.
먼저 최초에 C가 파일을 만들고 자신의 디렉토리 밑에 파일을 둔다.
유닉스 운영체제에서는 디렉토리 엔트리에 i-node 번호가 저장되고, 위 그림에서 디렉토리와 연결된 네모가 i-node를 의미한다.
그림에는 i-node에 있는 다른 속성들을 생략하고 파일의 소유자와 이 파일에 걸린 링크의 개수를 보여주고 있다.
최초에 이 파일에는 C의 디렉토리와 연결된 하드링크가 1개 존재하는 것과 같다.
이때 B에서 C가 만든 파일에 하드링크를 걸게 되면, 이 파일을 나타내는 같은 i-node 번호가 B의 디렉토리 엔트리에도 똑같이 연결되어 같은 i-node를 바라보게 된다.
이때 소유자는 여전히 최초에 이 파일을 만든 C로 표기된다.
이때 C가 파일을 삭제하게 되면, 디렉토리에서 unlink 시스템 콜을 통해 C의 디렉토리와 i-node 사이의 링크를 지운다.
하지만 이 파일은 여전히 B의 디렉토리와 link 가 존재하므로, B의 디렉토리에서 여전히 파일에 접근할 수 있다.
(원본 파일의 생성자가 지웠다고 해서 이 파일을 링크로 갖고 있는 모든 디렉토리에 가서 디렉토리 엔트리를 지울 수 있는 현실적인 방법이 없다.)
반면 소프트 링크(심볼릭 링크)는 링크를 생성하기는 하는데, LINK 라는 타입의 새로운 파일을 만들고, 이 파일의 i-node를 가리키도록 디렉토리 엔트리를 생성한다. LINK 타입의 파일의 내부에는 원본 파일의 경로가 텍스트로 저장되어 있으며, 추가적인 디스크 요청을 통해 원본 파일에 접근할 수 있다.
결론적으로는 새로운 파일을 만드는 것이기 때문에 추가적인 디스크 블록과 i-node를 사용한다.
또한 별도의 파일을 만들어서 공유할 파일을 가리키는 방식이므로, 기존 파일에 추가적인 링크가 없어서 기존 파일을 C가 삭제하면 링크가 모두 사라져서 정말 삭제되며, LINK 타입의 파일로 접근하려고 하면 접근에 실패한다.
심볼릭 링크는 다른 파일의 경로를 참조하는 경로를 저장하는 파일이므로, 이를 응용하면 같은 시스템이 아닌 다른 기계에 존재하는 파일을 가리키는 것도 가능하다.
'CS > 운영체제' 카테고리의 다른 글
| [운영체제] 21. I/O Device (0) | 2024.12.09 |
|---|---|
| [운영체제] 20. UNIX V7 File System (0) | 2024.12.08 |
| [운영체제] 18. File & Directory (0) | 2024.12.07 |
| [운영체제] 17. Segmentation (0) | 2024.12.05 |
| [운영체제] 16. 페이지 교체 알고리즘 (0) | 2024.12.05 |