Configuration Management (CM)
CM은 소프트웨어 시스템의 변화를 관리하는 도구, 프로세스, 정책과 관련된 개념이다.
특히 팀 프로젝트를 하다보면 각 개발자들이 서로 다른 변화를 만들어내기 때문에 이 변화들을 관리하기 위해 필수적이다.
소프트웨어 컴포넌트의 확정된 변경사항은 버전별로 repository 라는 공동 저장소에 저장되어 있고, 개발자들은 repository 에 있는 코드를 자신의 workspace 로 가져와서 개발한다.

CM 에서 수행하는 활동은 크게 4가지가 있다.
1. version management
시스템 컴포넌트를 버전 별로 추적 관리하는 것
2. system building
컴포넌트, 데이터, 라이브러리를 모아서 하나의 실행가능한 프로그램으로 만드는 것
3. change management
고객이나 개발자로부터 나온 요구사항의 변경 사항을 추적 관리 하는 것
각 버전에서는 어떤 것들이 변경되었는지 기록한다.
4. release management
실제 사용자들이 사용하도록 출시된 소프트웨어의 버전을 관리하는 것
위 그림에서 component version 은 소프트웨어의 각 모듈의 버전을 말하고,
system version 은 모듈이 합쳐진 시스템의 버전
system release 는 그렇게 합쳐진 시스템 중 실제 유저가 사용하도록 출시된 시스템의 버전을 말한다.
component version, system version 은 개발 중인 시스템과 관련있으므로 version management, system building 과 관련이 있고, system version 과 system release 는 출시된 시스템과 관련있으므로 change management, release management 와 관련이 있다.
Version Control (VC)
규모가 큰 소프트웨어는 하나의 working version 을 가질 수 없다.
서로 파트를 나눠서 개발하다보니 각자 작업하는 버전이 당연히 다를 수 밖에 없을 것이다.
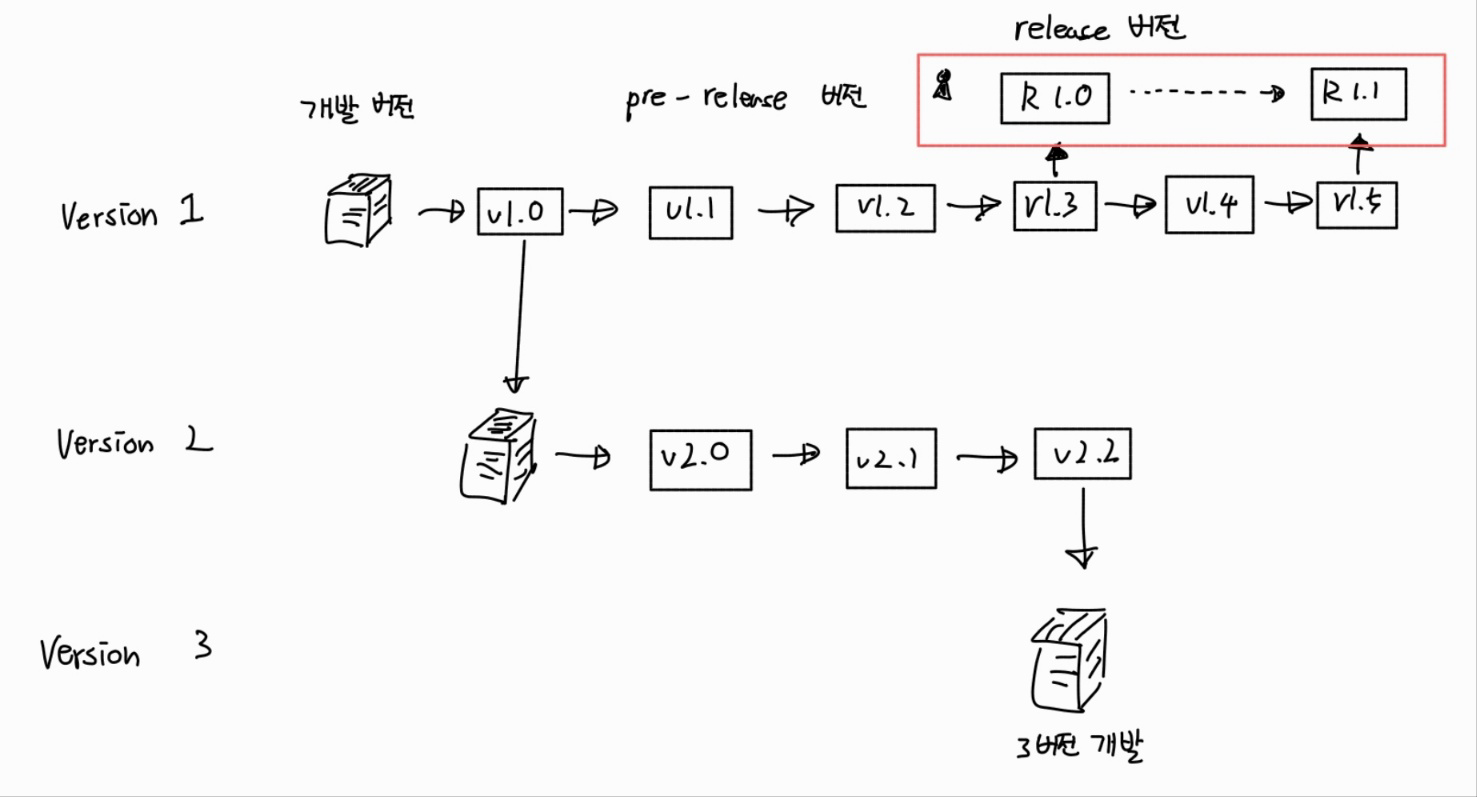
먼저 Development version 은 개발중인 버전을 말한다.
Version 1 에서 처음으로 1.0 버전이 나온 것은 모든 것을 조립해서 처음으로 잘 돌아가는 하나의 시스템이 완성된 상태를 말한다.
그리고 그 시스템에서 계속 수정하면서 V1.1, V1.2, .. 하면서 버전이 계속 올라간다.
기본적으로는 1.0 버전 기반으로 수정하기 때문에 앞자리 1은 같은 버전을 유지한다.
그러다가 V1.3 에서 처음으로 이 소프트웨어를 사용자에게 공개하였다.
이때 사용자 입장에선느 처음으로 이 소프트웨어를 본 것이므로 R1.0 버전으로 보인다.
하지만 내부 개발팀 입장에서는 1.3 버전으로 관리중인 상태이다.
사용자에게 출시한 이후 피드백을 받으면서 내부적으로 1.4, 1.5 버전으로 수정을 하다가 1.5 버전에서 다시 사용자에게 수정된 버전을 출시하였고, 그 버전은 사용자 입장에서 R1.1 버전으로 보인다.
한편 내부에서는 1.0 버전을 기반으로 2.0 버전을 개발하고 있고, 2.0 버전을 수정하다가 2.3버전을 기반으로 3.0 버전을 개발하고 있다.
이렇게 앞자리가 바뀌는 경우는 크게 변화한 경우를 말한다.
이렇게 소프트웨어는 다양한 버전으로 나눠져 개발이 되기 때문에, 각각의 버전 별 컴포넌트를 식별하고, 저장하고, 접근을 관리할 수 있는 Version Control System 이 필요하다.
VC에는 크게 Centralized System 과 Distributed System 의 2가지 종류가 있다.
Centralized Version Control
Centralized System 은 하나의 master repository에 모든 버전의 컴포넌트와 시스템을 관리하는 방식이다.
대표적인 예시로 CVS, SVN, Subversion 등이 있다.
centralized 방식에서는 Check-out 과 Check-in 개념이 존재한다.
이 개념은 호텔에 들어갈 때 내가 입실한다는 것을 기록하기 위해 체크인하고, 호텔에서 나갈 때 내가 퇴실한다는 것을 기록하기 위해 체크아웃하는 것과 비슷한 개념이다.
하나의 main repository 에서 새로운 기능을 개발할 때는 기존 소스코드가 들어있는 main repository 에서 '나와서(check-out)' 나의 workspace 로 이동해야 한다.
그리고 workspace 에서 개발한 기능을 main repository 에 반영한다는 것은 내가 개발한 소스코드가 main repository로 '들어가는check-in)' 것과 같다.

예를 들어, main repository 에 A, B, C 컴포넌트가 각각 1.0 버전으로 들어있는 상태에서 앨리스와 밥이 추가 개발을 하기 위해 이 소스코드를 자신의 워크스페이스로 가져왔다고 해보자.
각 소스코드 입장에서는 main repository 에서 나와서 각 개발자들의 워크 스페이스로 이동한 것이므로, check-out 하여 소스코드를 가져온 것이다.

앨리스는 소스코드에서 A, B 를 수정하였고, 밥은 소스코드에서 B, C 를 수정하였다.
그러면 각 컴포넌트의 버전은 앨리스와 밥 입장에서 모두 1.1 이 될 것이다.

변경을 마친 컴포넌트는 다시 main repository 로 들어가야 한다. (check-in)
이때 B 컴포넌트는 앨리스와 밥 모두에 의해 수정되었기 때문에, 두 수정사항이 합쳐져 2개 버전이 올라간 1.2 버전으로 관리된다.
따라서 앨리스와 밥이 다음에 다시 checkout 하게 되면 그때는 둘 모두 B의 버전이 1.2 로 올라가있을 것이다.
그런데 B와 같이 하나의 컴포넌트를 서로 다른 사람들이 각각 가져가서 수정하면, 나중에 합칠 때 어떤 수정본으로 합쳐야 할 지 애매해서 충돌이 일어날 수 있다. 따라서 이미 checkout 된 코드를 또 check out 하려고 하는 경우에는 VC system이 경고를 보낸다.
또한 다른 사람의 수정 사항이 이미 main repository 에 올라가 있는데, 그 부분이 수정되기 전의 repository 코드를 가져가서 수정했다가 check-in 하는 경우에 다른 사람의 수정 사항을 덮어써서 없던 것으로 만들 수 있다.
따라서 항상 check-in 하기 전에는 다른 수정사항이 있었는지 check-out 을 하고나서 check-in 해야 한다.
Distributed Version Control
Distributed System 은 각 컴포넌트의 여러 버전에 대한 레포지토리가 동시에 분산되어 있는 방식이다.
대표적인 예시로 Git, Mercurial 등이 있다.
Distributed 방식에서는 하나의 'master repository' 를 만든다.
이 레포지토리는 개발팀에서 작성한 팀 단위의 코드가 유지된다.
그리고 각각의 개발자는 master repository 를 복제한(clone) 각자의 레포지토리를 갖는다.
따라서 별도의 checkout 없이 자신의 private repository 에서 개발을 이어나가면서 필요할 때마다 변경사항을 commit 한다.
그리고 최종적으로 수정이 끝나면 그 결과물을 master repository에 push 한다.

아까와 비슷하게 예시를 보면, 앨리스와 밥은 소스코드를 가져올 때 check-out 대신 clone 으로 가져온다.
이때 클론은 말 그대로 master repository 를 완전히 복사해서 내 컴퓨터로 가져오는 것을 말한다.
그리고 각자 자신의 레포지토리에서 A, B, C 컴포넌트를 수정하고 commit 하여 변경사항을 기록한다.

그리고 수정된 버전의 repository 를 그대로 master repository 에 push 한다.
이때도 서로 같은 부분을 수정했다면 충돌이 발생할 수 있기 때문에, push 하기 전에는 다른 사람의 수정사항을 내 컴퓨터로 가져와야 한다.
clone 은 아무것도 없는 초기에 master repository 를 복사하는 것을 말하기 때문에, 추가적인 수정사항을 나의 repository 로 가져올 때는 pull 을 해야 한다.
- Distributed VC 의 장점
1. 오프라인에서 작업할 수 있다.
처음에 master repository 를 복사할 때는 온라인으로 가져와야 하지만, 한번 가져온 뒤로는 모든 소스코드가 내 컴퓨터에 들어있기 때문에 오프라인에서도 작업하고 수정사항이 생길 때마다 커밋하여 스스로 버저닝을 할 수 있다.
하지만 centralized 방식에서는 수정사항이 생겼을 때 check-in 을 해야만 버전이 바뀌므로 온라인으로 작업해야 한다.
2. 레포지토리에 대한 백업
Centralized 방식에서는 master repository 에 문제가 생기면 그걸로 끝이다. (single point of failure)
하지만 Distributed 방식에서는 master repository 에 대한 복제본이 여기저기 널려있기 때문에, 원본에 문제가 생겨도 복제본을 기반으로 쉽게 복구할 수 있다.
3. 메인 프로젝트와 private repository 를 독립적으로 관리할 수 있다.
개발자가 자신만의 커밋 히스토리를 private repository 에 만들 수 있다.
즉, 자신만의 버저닝이 가능하다는 뜻이다.
centralized 방식에서는 버그가 있는 코드가 한번 check-in 되면, 그 이후에 check-out 한 모든 개발자가 그 버그의 영향을 받으므로 독립적이지 않다.
하지만 distributed 방식에서는 push 만 조심하면 버그가 발생한 코드가 project 에 반영되지 않는다.
Distributed VC는 오픈소스 개발에 있어 필수적이다.
오픈소스를 master repository 로 두고, 오픈소스를 수정할 사람들은 clone 해서 각자의 private repository 에서 수정한 뒤, 새로운 버전을 push 하면, 오픈소스 관리자는 push 된 버전들 중에서 어떤 것들을 master repository 로 pull 할 지 결정할 수 있다.
(수업 중에는 아무에게나 push 할 권한을 주면 안된다고 하셨는데, master repository 에 대한 push 권한은 당연히 관리자만 갖고 있어야 한다.)
Branching and Merging
프로젝트를 개발하면서 버전을 업데이트 할 때, 꼭 버전이 시간 순서를 따라서 증가하지 않을 수 있다.
어떤 버전이 증가하는 것과는 독립적으로 다른 버전에서 버전이 증가할 수 있다.
시스템을 개발할 때 사실 자연스러운 현상이다.
각각의 개발자가 서로 개발하고 있으면 각자 자신만의 버전을 쌓아나가고 있을 것이기 때문이다.
이렇게 각각의 개발자가 자신의 파트를 개발하는 단계에서 버전이 증가하면 자연스럽게 기존 버전에 대해서 새로운 가지(branch)가 뻗어나오는 식으로 버저닝되고, 각각의 개발자가 개발한 단게를 합칠 때 다시 버전이 합쳐진다.
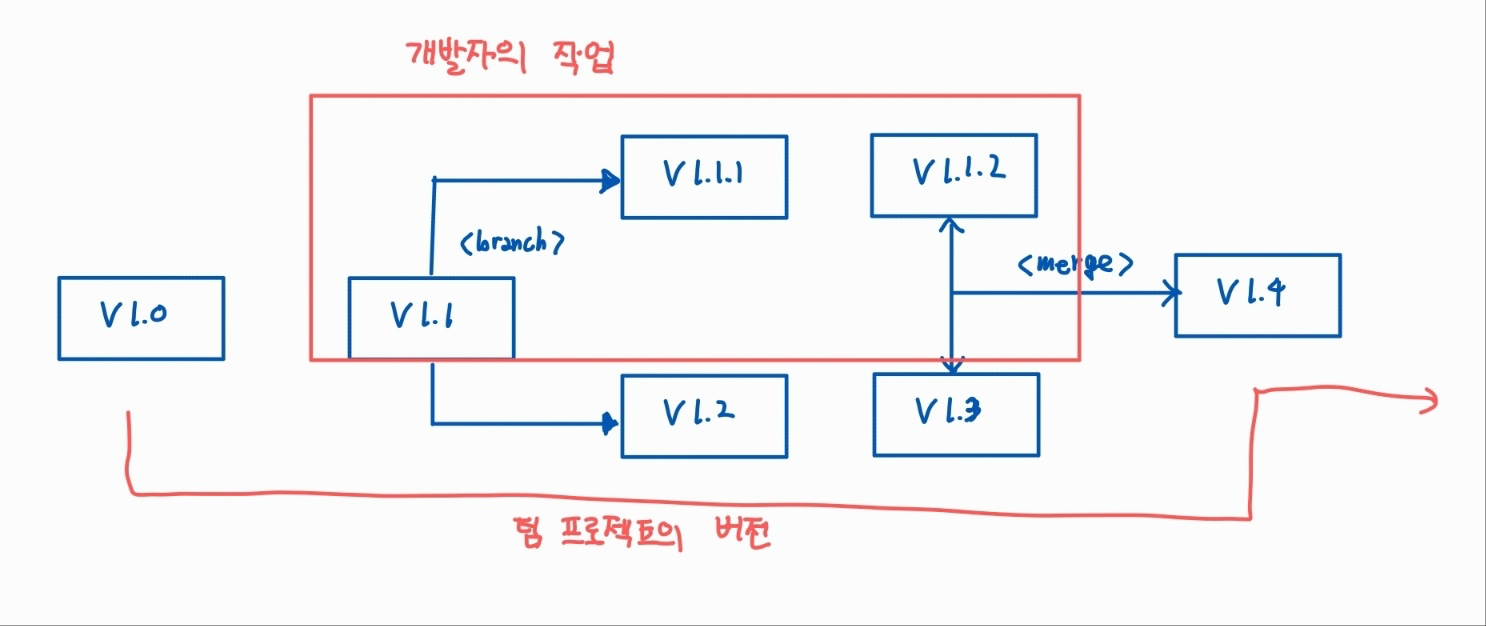
그림으로 보면 위와 같이 나타낼 수 있다.
팀 프로젝트가 1.0, 1.1, 1.2, ... 로 증가하고 있을 때, 개발자가 1.1 버전에서 브랜치를 파고 나와 신규 기능을 개발한 뒤, 1.3 버전에서 merge 하여 1.4 버전으로 넘어가는 단계를 보여준다.
지금까지 Configuration Management 와 버전 관리에 대해 정리하였다.
다음 글에서는 git 을 통해 어떻게 버전관리하는지 그 예시를 정리한다.
'CS > 소프트웨어공학' 카테고리의 다른 글
| [소프트웨어공학] 14. Object Interaction (0) | 2025.06.04 |
|---|---|
| [소프트웨어공학] 13. Requirement Analysis (3) | 2025.06.03 |
| [소프트웨어공학] 11. Use Case Diagram (1) | 2025.04.21 |
| [소프트웨어공학] 10. Requirement Capture (0) | 2025.04.20 |
| [소프트웨어공학] 9. Modeling Concept (1) | 2025.04.19 |