지난 글에서는 우선순위 큐와 이를 효율적으로 구현하기 위한 자료구조인 Heap 에 대해 정리하여 보았다.
이번 글에서는 한번 파이썬의 Heapq 를 뜯어보고자 한다.

뜯어보는 방법은 간단하다.
파이썬의 heap 모듈인 heapq 를 선언하고, ctrl 키를 누르고 클릭하면, 해당 모듈의 코드를 읽어볼 수 있다.
Heap 개념 설명

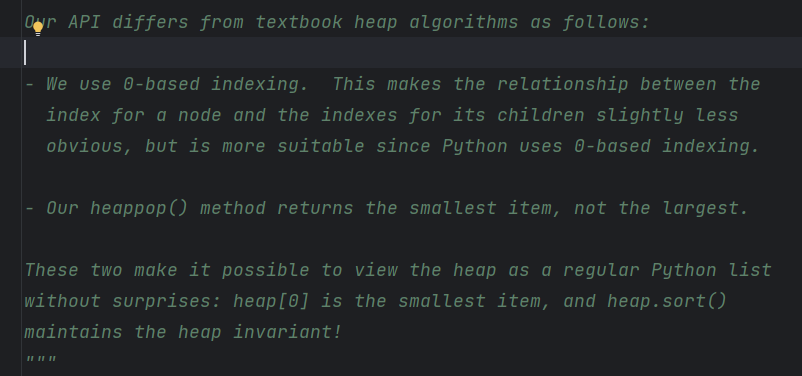
코드 상단부에는 이렇게 heapq 모듈에 대한 설명과 사용 방법이 소개되어 있다.
위에 정의를 보면 우선순위큐를 heap queue 알고리즘이라고도 표현하는 것을 볼 수 있다.
파이썬의 공식 모듈에서 정의한 Heap은 모든 k 에 대해 a[k] <= a[2*k+1] 과 a[k] <= a[2*k+2] 를 만족하는 배열이라고 한다.
지난 글에서 정리했던 정의와 조금 다르다.
그 이유는 파이썬의 heap 은 가장 작은 값이 항상 위로 올라오는 'min heap' 이면서, 배열의 인덱스가 0부터 시작하는 0-index 방식을 사용하기 때문이다.
k = 0 을 넣어보면 a[0] <= a[1] and a[0] <= a[2] 가 나오는 것을 알 수 있다.
지난 글의 마지막에서 정리한대로 0-index 를 사용하면 자잘한 연산이 하나 더 추가되어 1-index 방식보다 효율적이지 않음을 알 수 있다.
재미있던 점은, 이걸 파이썬 모듈 작성자도 그대로 설명했다는 점이다.
우리가 작성한 힙은 최소힙이고 0-based indexing 을 사용한다.

그러더니 갑자기 힙을 친절하게 그림까지 보여주며 설명하기 시작한다.
위 그림이 파이썬에서 사용하는 k 값에 따른 이진트리 내 위치이다. ( a[k] 가 아니다! )

만약 힙의 불변성이 항상 유지된다면, 0번째 인덱스의 값이 항상 승자(제일 작은 값) 이고, 만약 이 값을 제거하면 loser( 즉, 대충 아래쪽에 있는 큰 인덱스 값) 을 0으로 올린 뒤 교체하면서 다시 불변성이 유지될때까지 교체한다는 걸 설명하고 있다.
이 작업을 모든 원소에 대해 반복하면 작은 순으로 뽑아내는 정렬에 O (n log n) 시간이 걸린다는 것도 말해준다.

그리고 지난 글에서 정리한 대로, 스케쥴링에 힙을 쓰기 좋다고 한다.
(근데 미디 시퀸서에 이걸 쓴다는 건 무슨뜻일까..)

그리고 큰 디스크 정렬에도 유용하다고 한다.
Heap 연산자

전체 메소드는 위와 같다.
모든 메소드를 자세하게 정리하기보다 기본 메서드 heappush, heapop 과 그 밖에 재미있게 본 메서드 위주로 정리하고자 한다.
heappush

아주 간단한 코드이다.
리스트의 맨 뒤에 새 아이템을 추가하고, 그 아이템을 포함한 힙을 _shfitdown 함수를 이용해 재설정한다.

shfitdown 함수는 위와 같이 생겼다.
새로 추가한 아이템을 미리 변수에 저장해두고, 부모 노드와 새로 추가한 아이템을 비교해서 부모노드가 더 크다면 아래로 내리는 작업을 반복한다.
그러다가 모든 부모를 내렸거나, 부모가 더 작아서 내릴 수 없다면 반복을 멈추고 그 위치에 새로 추가할 아이템을 넣는다.
이 작업의 시간복잡도는 당연히 O(log n) 이다.
heappop

배열의 제일 마지막 원소를 pop 한다.
배열이 비어있어서 pop을 할 수 없다면 에러가 발생하는데, 이는 적절한 에러라고 한다.
마지막 원소를 빼고도 여전히 힙에 데이터가 있다면, 반환할 아이템을 미리 변수에 저장해두고
마지막 원소를 맨 처음 루트에 넣은 뒤, siftup 메소드를 통해 마지막 원소가 힙 정의에 맞는 위치로 가도록 한다.
정렬이 끝나면 저장해둔 반환할 아이템을 반환한다.
이제 siftup 메소드를 한번 살펴보자.
그런데 해당 메서드 위로 가니 이런 긴 주석이 있었다.


대충.. 파파고와 구글번역기와 내가 알던 영어지식을 총집합해서 해석하니까 아래 접은글 내용과 같았다.
heap index pos 의 자식 인덱스들은 이미 힙이다.
우리는 index pos 의 힙도 그렇게 만들고 싶다.
우리는 이를 pos 의 더 작은 자식을 bubbling up 함으로서 수행한다. (leaf 에 닿을 때까지)
(그리고 이를 그 아래 자식에 대해 반복한다.)
그리고나서 siftdown 함수를 사용하여 index pos 에 있는 oddball 을 제자리로 이동시킨다.
=> 코드를 보니 이게 파이썬의 heapq 모듈에서 구현한 heap pop 방식이다.
우리는 newitem이 그 두 자식보다 모두 작다거나 같다는 걸 알자마자 반복문을 빠져 "나올 수 있다"
그러나 이는 여러 책에 pop 과정을 이렇게 설명하였음에도 좋은 아이디어가 아니라고 밝혀졌다.
heap pop 을 하는 동안, 배열의 마지막 원소는 체에 치듯 걸러지고, 점점 커지는 경향이 있다.
그래서 배열의 마지막 원소를 첫번째 루트 노드부터 비교하는 것은 일반적으로 효율적이지 않다.
(반복문을 더 일찍 빠져나오지 못한다.)
크누스 volume3 을 보면 이것이 설명되어있고, 예시와 함께 수치화되어 있다.
=> 요약하면, 너희가 배운 방식은 그렇게 효율적인 방식이 사실 아니다! 라는 내용이다.
이 루틴들이 배열의 원소로부터 "우선순위" 를 추출하는 방법이 없어서 우선순위를 설정하는 아이디어는 커스텀 비교 함수나 (우선순위, 값) 으로 설정된 튜플에 숨어있는 경우가 많아서 비교 횟수를 줄이는 (컷팅하는) 것은 중요하다.
그래서 비교는 꽤 값비싼 연산이다.
길이 1000의 랜덤 배열에 대해, 이 변화를 적용하는 것은 비교횟수를 heapify 에서는 조금 감소시켰고, 1000번 heappop 하는 것에 대해서는 꽤 크게 비교 횟수를 줄였다.
heapify 가 아니라 heappush 를 1000번 사용하여 heap 을 구성하는 경우, 비교횟수는 각각 2198, 2148, 2219 였다.
(heapify 에서는 위 표에서 볼 수 있듯 커팅을 적용한 후 각각 1663, 1659, 1660 이었다.)
따라서 heapify 를 한번 사용하는 것이 heappush 를 여러번 사용하는 것보다 효율적이다.
동일한 리스트에 대해 list.sort() 메소드로 정렬하는 경우 비교횟수는 8627, 8627, 8632 였다.
반면 heapify 를 적용하고, heappop 을 1000번 하여 정렬하는 경우에는 위 표에서 보이는 두 비교횟수를 더한 것과 같다.
따라서 정렬을 할 때는 그냥 list.sort() 를 사용하는 것이 더 효율적이다.
내가 영어를 잘 못해서 이 문장을 제대로는 이해하지 못했지만, 위 내용을 이해한대로 대충 요약하면
heap pop 을 할 때, 맨 마지막 원소를 root로 올리고, 거기서부터 두 자식과 비교하면서 heap 을 구성해 나가는 방법을 많은 책에서 소개하고 있는데, 사실 이건 별로 효율적이지 않다.
그래서 우리는 더 작은 child 가 bubbling up 되도록 한 뒤, addball 의 위치를 되찾도록 하는 방식으로 비교횟수를 커팅했다.
비교횟수를 커팅하는 것이 중요한 이유는 배열에 들어있는 "우선순위" 에 대한 정보를 추출하는 방법이 이 루틴(?) 에는 없어서 커스텀 비교함수를 쓰거나, 힙에 데이터를 저장할 때 (우선순위, 값) 쌍의 튜플을 저장하는 아이디어를 자주 사용하기 때문이다. 그러므로 비교는 잠재적으로 비용이 크다.
커팅 결과, heapify 는 소폭 비교횟수가 감소했고, heappop 은 대폭 비교횟수가 감소했다.
그리고 직접 비교해보니 heappush 를 1000 번하기보다 가능하다면 heapify 로 이미 구성된 배열을 heap 으로 만드는 것이 더 효율적이었다.
그리고 데이터를 단순히 정렬하는 게 목적이라면 그냥 list.sort() 를 쓰는게, heapify 해서 힙으로 만들고 1000번 pop 하는 것보다 효율적이었다.
비교횟수가 얼마나 커팅되는지는 지금 와닿지는 않지만, 한번 그 효율적이라는 코드를 읽어보자.

일단 heappop 을 하기 위해서, 제일 마지막 원소를 root 인 0번째 인덱스에 저장하고, siftup(heap, 0) 을 수행하는 상황이다.
endpos 는 힙 배열의 길이
startpos = 0
newitem = heap[0]
이렇게 설정될 것이다.
childpos = 2*0+1 = 1 로 왼쪽 자식을 먼저 보고 있다.
반복문으로 들어가면, childpos < endpos 인 동안 반복하는데, childpos 값이 계속 바뀔 것으로 예상된다.
먼저 pos의 오른쪽 자식의 인덱스를 childpos + 1 로 구한다.
그리고 rightpos < endpos 이고, 왼쪽 자식의 값이 오른쪽 자식의 값보다 작지 않다면 childpos 를 오른쪽 자식으로 설정한다. (즉, 좌우 자식의 값 중 더 작은 값을 자식의 값으로 설정.. 왜 이걸 이렇게 배배 꼬아서 작성하는 걸까..)
기존 heap[pos] 의 값을 위에서 설정한 childpos 의 값으로 바꾸고 (부모와 자식을 교체한다.)
pos 는 새로운 childpos 로, childpos 는 다시 왼쪽 자식의 노드값으로 설정한다.
즉, 반복문을 통해 자식 노드 중에서 더 작은 값을 골라서 일단 부모노드와 교체부터 하고 보고 있다.
왜 부모노드와 비교도 하지 않고 이 과정을 왜 수행하는 걸까?
아무튼 이 과정을 거치면, 새로 들어온 아이템이 제일 맨 마지막 leaft 로 들어가게 된다.
이 과정에서 다시 siftdown 을 수행하여, 힙을 맞춘다.
뭔가 저 주석을 읽고나서 이 코드를 읽어보니 알 것 같다.
그러니까 요지는 다음과 같다.
지금 leaf 에 있던 마지막 원소를 root 노드로 대체해서 넣어놨는데, 생각해보자.
이미 root 노드 말고 나머지 노드들은 잘 heap 으로 정렬되어 있었다.
즉, 이미 완벽한 상태에서 마지막 노드를 root 로 바꿔서 끼워넣으니까 모든게 꼬인 상태다.
이 상태에서 다시 heap으로 만드는 건 별로 효율적이지 않다.
왜냐하면 마지막 노드는 일반적으로 heap 에서 비교적 꽤 큰 값일 가능성이 크기 때문이다.
그래서 swap이 꽤 많이 일어나게 된다.
그렇다면 기존에 잘 정렬된 노드들을 이용해서 일단 힙을 구성한 다음, 새로 들어온 (아마도 꽤 큰 값을 가능성이 큰) 녀석을 제일 아래쪽(즉, 다시 제일 큰 인덱스) 에 깔아둔다.
그 다음 위에서 수행했던 siftdown 함수를 수행한다.
그러면 이 함수는 반복문을 빠르게 탈출할 확률이 높다.
새로 들어온 녀석은 큰 값일 확률이 높기 때문이다.
따라서 기존에 잘 정렬된 노드를 이용해 힙을 구성하는 과정에서의 비교횟수는 기존에 배웠던 방식과 동일하지만,
siftdown 함수에서 비교횟수가 월등히 줄어들게 된다.
그런데 지금 드는 한가지 의문은, 그럼 애초부터 마지막 노드를 root에 왜 두는 거냐는 거다.
어차피 결국 제일 마지막으로 내려갈 노드인데 말이다.
그냥 root 노드를 비워두고 자식 노드를 비교하면서 잘 채우면 되지 않았을까?
그리고 기존 방식보다 이게 더 효율적인 이유가 뭘까?
기존에는 루트노드, 왼쪽 노드, 오른쪽 노드 이렇게 3개를 비교해서 더 작은 노드를 위로 올리면서 교체하는 걸 반복하면 되었다.
(루트 노드와 왼쪽 노드 비교, 루트노드와 오른쪽 노드 비교, 왼쪽 노드와 오른쪽 노드 비교, 3번 비교가 일어남)
그리고 이 과정은 루트노드가 두 자식노드보다 작다면 끝나는 거였다.
그런데 이게 꽤 아래쪽까지 이어질 가능성이 컸다.
그렇다면 3번 비교하는 걸 log n 번 반복할 수 있다는 뜻
그런데 이 방식은 왼쪽 노드, 오른쪽 노드를 비교해서 (1번 비교) 더 작은 값으로 부모 노드와 반드시 교체한다.
그리고 아래에서부터 위로 올라가면서 부모노드와 비교해서 (1번 비교) 교체한다.
(이거가 금방 끝날 가능성이 크다는 건가)
그럼 최선의 경우 log n 번 비교해서 새로 들어온 친구를 맨 아래로 깔아두기만 하면 거의 heap 세팅이 완료되었다는 뜻이니까 log n 번이면 끝난다는 뜻?
3 log n vs log n 의 차이라서 더 효율적이라는 건가
heapify
학교 수업에서도 heapify 연산은 O(n) 선형 시간에 가능하다고 하였다.
어떻게 기존 배열을 heap으로 만드는데 선형시간에 수행가능한걸까?
한번 코드를 뜯어보았다.

in-place 그러니까 별도의 배열을 사용하지 않고, 그 안에서 O( n ) 시간에 이 연산을 수행한다.
최소힙의 특성상, 제일 큰 값은 항상 누군가의 자식노드로 깔릴 수 밖에 없다.
그래서 0~n//2 까지를 거꾸로 돌면서 그 인덱스의 값을 제일 밑으로 깔아내린다.
왜 이렇게 하면 힙이 되는거지.....?
그리고 왜 반복문은 반만 도는거지?
그리고 siftup 메소드는 log 시간 아닌가? 왜 이게 n log n 이 아니라 n 시간에 작동하는거지?
https://leeminju531.tistory.com/33
build heap 시간복잡도 O(n) 이해하기
포스팅 목적 - heapify 이해하기 - siftup , siftdown 이해하기 - build Heap Time Complexity : O(n) 이해하기 Heap 을 구성하는데 O(n)의 시간복잡도를 갖음을 이해하는데 앞서 가장 간단한 방법을 생각해봅시다.
leeminju531.tistory.com
이 글을 참고하니까 조금 더 이해가 쉬웠다.
(이 글에서 사용한 siftup 과 파이썬의 siftup이 조금 다른 것 같긴 하다.)
우선 반복문을 반만 돌아도 괜찮은 이유는, 기존 배열을 힙으로 구성하였때, 이미 n//2 개 노드는 leaf 노드에 있어 (위 글의 표현을 빌리면) siftdown 이 발생하지 않기 때문이다.
(파이썬 코드를 보면 siftup 코드에서 마지막에 siftdown 함수를 호출한다.)
시간복잡도가 n 이 되는 이유는 위 글에서 증명한 내용을 보고 이해하였다.
모듈을 뜯어본 후기
처음 모듈을 뜯어봤는데, 생각보다 주석이 자세해서 놀랐고, 또 코드가 생각보다 길지 않아서 놀랐다.
그럼에도 아직은 이해가 잘 안 되는 부분도 많은 것 같다.
다음에 다시 한번 더 읽어보면 그때는 좀 더 잘 읽히지 않을까 기대해본다.
'CS > 자료구조' 카테고리의 다른 글
| [자료구조 및 프로그래밍] 13. Binary Search & Sequential Search (0) | 2023.12.05 |
|---|---|
| [자료구조 및 프로그래밍] 12. Hashing & Hash Table (0) | 2023.12.02 |
| [자료구조 및 프로그래밍] 11. 우선순위 큐와 Heap (0) | 2023.12.02 |
| [자료구조 및 프로그래밍] 10. BST 탐색 시간과 Height 사이 관계 (0) | 2023.10.23 |
| [자료구조 및 프로그래밍] 9. 이진 탐색 트리 (3) | 2023.10.22 |