Generalized Forwarding
지금까지 정리한 포워딩 방식은 IP 패킷을 받으면, 이 패킷의 목적지 IP주소를 보고, 가장 길게 매치되는 것을 포워딩 테이블에서 찾아서, 그 다음 목적지로 가기 위한 output link(port) 를 결정했었다.
이번엔 이 방법보다 조금 더 일반화된 포워딩 방법을 정리해보려고 한다.
왜 output port 를 찾을 때 목적지 주소만 봐야 하는가, Source IP주소를 봤을 때도 도움이 될 만한 부분이 실제로 많다.
예를 들어 인터넷 해킹에서 공격 시발점의 source ip주소를 보고, black list에 있는 IP주소와 매칭되면 원천적으로 방화벽에서 차단시켜버리는 경우가 있다.
홍대도 매일 100건 이상의 공격시도가 들어오는데, 물론 공격자들이 IP주소를 바꿔가면서 공격을 시도하지만 몇 번 이상 동일한 IP주소로 공격이 들어오면 그 주소들을 블랙리스트에 올려둔다.
그러면 앞으로 같은 IP주소에서 요청이 와도, 방화벽에서 사전에 막을 수 있다.
이런 식으로 꼭 IP 주소의 목적지만 보지 않고, header를 보는 경우에, 라우터의 기능이 꼭 아니더라도 여러가지 유익한 일을 할 수 잇는 네트워크 장치들이 많다.
OpenFlow는 이런 아이디어들의 표준이다.
그리고 Middlebox는 소스와 데스티네이션 사이에 라우터 이외의 엔드 시스템에서 해야될 일을 하는 장치를 말한다.
(NAT도 미들박스이다.)

지금도 많이 쓰이는 동시에, 제일 기본적인 방법은 라우터마다 포워딩 테이블을 갖고 있고, 패킷이 도착하면 그 패킷의 목적지를 포워딩 테이블에서 최대한 길게 매칭되는 부분에 맞춰 output link를 결정하는 방식이었다.
포워딩테이블은 라우팅 알고리즘 (라우팅 프로토콜을 구현한 분산 프로그램) 의 실행 결과로 만들어진다.
근데 generalized forwarding 방식은 이 포워딩 테이블을 아예 별도로 만들어서 제공해줄 수 있지 않냐는 아이디어를 제시한다.
그리고 패킷의 다음 목적지를 결정할 때, 목적지 주소 뿐만 아니라 다른 필드도 같이 볼 수 있지 않느냐는 아이디어를 제시한다.
그래서 기존에 포워딩을 위해 match plus action을 할 때, match 는 목적지 주소가 제일 길게 일치하는 것을 보는 것이 match 였고, action은 forward 밖에 없었지만, 이걸 좀 더 일반화해서 match도 일반화시키고 action도 일반화 시켜보자는 아이디어로 나온 것이 generalized forwarding 이다.
그래서 목적지를 결정할 때는 목적지 IP주소 뿐만 아니라 다른 조건도 and 조건으로 엮어서 매칭하고,
매칭 후 그 결과에 대해 action을 취할 때는 forward 말고도 drop, copy, modify, log 와 같이 다양한 동작을 하도록 일반화했다.
예를 들어, drop은 이 패킷이 악성 코드일 가능성이 있다고 라우터나 다른 네트워크 장치가 자체적으로 판단하면 패킷을 더이상 포워딩 시키지 않고 폐기시키는 것을 말한다.
copy는 패킷을 복사해서 컨트롤러에게 보낸 뒤, 이 패킷을 조사해달라고 할 수 있다.
modify는 NAT 장치가 대표적으로 하는 행동으로 패킷을 전송하기 전에 이 패킷의 헤더 정보 (IP, port 등) 를 바꾸는 행동을 할 수 있다.
또는 단순히 log 기록을 남길 수도 있다.
로그를 남기면 도착한 패킷들을 분류해서 통계 목적으로 사용할 수 있다.
예를 들면 어떤 프로토콜의 패킷이 어느 정도 수준으로 도착하고 있는지 그 비율을 확인할 수 있다.

이렇게 일반화된 경우에 사용하는 테이블을 flow table 이라고 한다.
기존에는 forwarding table 이었지만, flow table을 대신 사용해서 헤더 필드의 조합을 통해 'flow' 라는 것을 한번 생각해보자는 것이다. (flow = 트래픽 단위의 모음, 동일한 처리를 요구하는 트래픽이나 한 사용자가 발생시키는 연속된 TCP 데이터 등을 flow로 볼 수 있다.)
그리고 각각의 flow에 대해 어떻게 처리할 것인지 flow table에 명시한다.
좀 더 구체적으로 예를 들자면, 여러 헤더 필드에 특정한 패턴을 보고 match가 되는지 안되는지 확인하고, 매치된 패킷에 대해 다양한 action을 수행하는 것이다. (우선순위를 부여할 수도 있다. 2개 이상 규칙에 부합하면 어떤 규칙에 우선순위를 줄 것인지 등)
priority counter 는 로그 목적으로 이러한 특정한 매치된 패킷이 얼마나 되는지, 패킷의 수를 로그로 남길 수 있다.

예를 들면 테이블에는 이런 내용이 들어갈 수 있다.
3.4.*.* 을 목적지로 하는 패킷은 2번 포트로 포워딩하고, 특정 주소에서 오는 패킷은 버리는 등의 규칙을 다양하게 둘 수 있다.
세번째 규칙의 경우, src 가 private ip주소라는 것을 알 수 있다.
이 src는 라우터가 만나면 안된다. 이 IP주소를 볼 수 있는 경우는 NAT가 설치된 경우 밖에 없다.
따라서 이런 src는 컨트롤러로 보내서 확인을 요구할 수 있다.
OpenFlow
open flow는 이런 generalized forwarding을 위한 일종의 open 표준이라고 볼 수 있다.
따라서 이 표준은 어떤 특정 회사의 소유가 아니라 누구나 볼 수 있는 표준이다.

OpenFlow 의 표준으로 나타나는 Flow table의 각 엔트리 포맷은 위와 같다.
우선 match부터 살펴보면,
ingress port : 라우터의 input port 중 어떤 포트로 들어왔는지를 나타낸다. 나가는 port 는 outgress port가 된다.
녹색은 2계층의 정보를 담는다.
MAC 어드레스, 이더넷 타입 (이더넷 프레임에 포함될 데이터의 성격, 대부분은 IP 일 것이다. IP버전을 명시할 수도 있다.)
VLAN은 Virtual LAN 이다.
주황색은 3계층의 정보를 담는다.
IP주소의 출발지, 목적지, IP Protocol (IP의 데이터가 갖고 있는 데이터 종류, TCP인지 UDP인지), tos 필드를 체크할 수도 있다.
빨간색은 4계층의 정보를 담는다.
여기에는 포트정보가 들어간다.
destination-based forwarding 에서는 순수하게 IP dest 정보만 봤지만, Generalized Forwarding 방식에서는 위와 같이 다양한 정보를 이용해서 action을 결정한다.
action에는 아까 정리한대로, forwarding, drop, modify 과 같은 것들이 있었다.
캡슐화해서 컨트롤러로 보낼 수도 있는데, 컨트롤러는 SDN 기반의 기술에서 등장한다.
SDN 기반의 기술은 클라우드 같은 곳에서 각 라우터에 보낼 포워딩 테이블을, '컨트롤러' 라고 부르는 일종의 서버가 만들어서 보내주는 것을 말한다.
action에는 컨트롤러에게 정보를 보내는 것까지 포함되는데, 아까 상술한 예시처럼 라우터에는 프라이빗 네트워크를 IP src로 달고 패킷이 오면 안되기 때문에, 컨트롤러가 확인하는 절차를 거칠 수 있다.
stat 은 통계 목적으로 패킷 수와 byte 수를 기록할 수 있다.
Example
1. Destination-Based forwarding
OpenFlow를 사용하면서 기존의 포워딩 방식을 흉내낼 수 있다.

매칭 조건을 위와 같이 설정하면 된다.
다른 조건은 안보고 오로지 IP Dst만 보는 것이다.
그리고 aciton은 무조건 forward만 사용하는 것이다.
2. Firewall

또는 그림과 같이 방화벽을 흉내낼 수도 있다.
22 port 로 접근하는 패킷은 어떤 패킷이든지 그냥 버리도록 할 수도 있고,
특정 src IP주소로 부터 오는 패킷을 버리도록 할 수도 있다.
그래서 해커들은 실제로는 black list에 들어있는 IP주소에서 요청을 보내지만 패킷을 조작해서 다른 IP주소에서 보낸 요청처럼 속여서 요청을 보낸다. (이걸 스푸핑 이라고 한다.)
3. Layer 2 destination-based forwarding

이렇게 MAC 어드레스의 도착지만 보고 포워딩하면 L2 스위치의 기능을 흉내낼 수도 있다.
그래서 이렇게 예시에서 볼 수 있듯, SDN (Generalized Forwarding)을 사용하면 여러가지 다른 종류의 device를 추상화해서 흉내낼 수 있게 된다.

그래서 이렇게 라우터, 방화벽, 스위치, NAT 와 같이 다양한 장치의 행동을 흉내낼 수 있다.
SDN은 네트워크의 프로그래머빌리티를 집어 넣는 아이디어라고 생각할 수 있다.
(참고로 스위치는 원래 범용 용어다. 계층을 가리지 않고, 어떤 데이터 전송 단위를 받아서 다음 목적지로 빠르게 내보내주는 장치를 통틀어서 스위치라고 부른다. 그래서 라우터도 스위치의 일종이다. 그런데 많은 사람들이 2계층의 이더넷 스위치를 그냥 스위치로 부르다보니 2계층 스위치를 가리키는 것처럼 생각하면 된다.)
2계층 스위치로서 동작할 때는 forwarding 말고도 flooding도 할 수 있다.
flooding 은 처음에 인터넷 목적지 주소를 가지고 목적지 노드를 찾아갈 수 없을 때, 전체에 뿌리는 방법이다.
그래서 flooding (broadcasting) 을 지원하기도 한다. (인터넷의 목적지 주소가 모두 F인 경우)
방화벽의 주요 동작은 drop 이다. drop 하면 deny하는 것이고 drop하지 않으면 permit 하는 것이다.
NAT는 Translation table이 필요했는데, 이를 OpenFlow로 구현하면 Flow table을 translation table처럼 쓸 수 있다.
이번엔 또 다른 예시를 살펴보자.

그림과 같이 네트워크가 구성된 경우를 생각해보자.
이때는 (비록 흐리게 나와있지만) controller가 존재하는 상황이다.
이 컨트롤러가 중앙 서버 역할을 수행하면서, 각 라우터에 들어갈 테이블을 만들어서 전달해준다.
즉, OpenFlow 개념은 중앙화된 컨트롤러를 가정하는 개념이다.
기존 방식은 라우터들끼리 데이터를 주고받으면서, 이 데이터를 통해 라우터가 독자적으로 포워딩 테이블을 계산해서 어디까지의 경로는 어디로 가는 것이 좋은지를 계산했다.
하지만 OpenFlow 방식은 컨트롤러가 만들어서 라우터들에게 뿌려준다.
이렇게 하면 모두가 같은 네트워크 그림을 보므로 동일성이 보장된다.
즉, Network-wide 하게 행동을 제어한다.
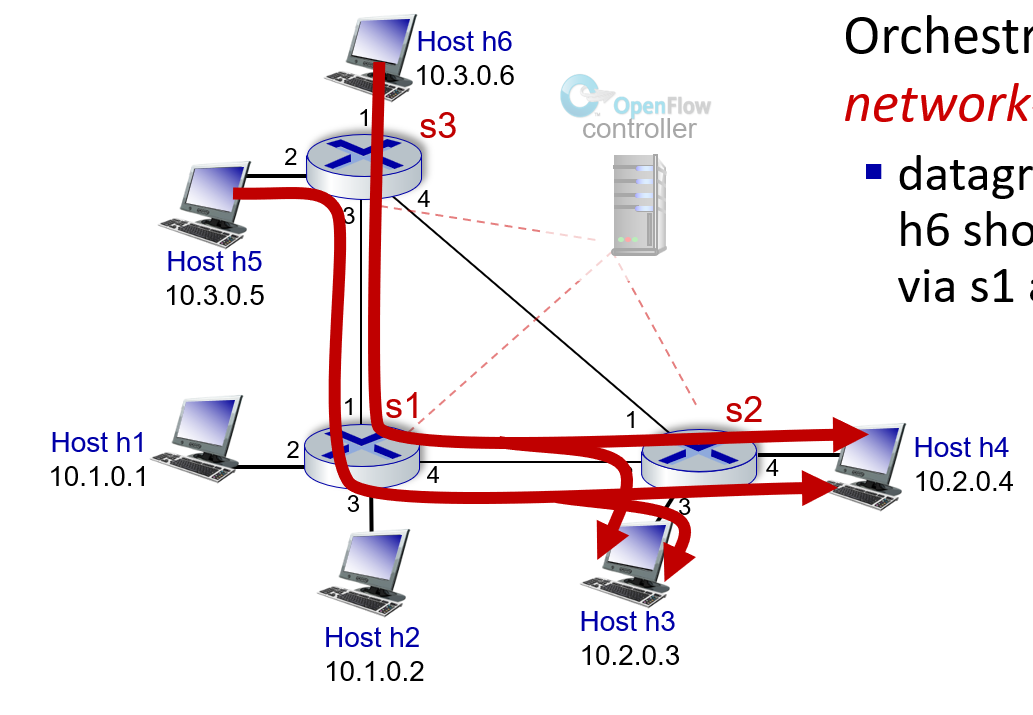
따라서 위 그림과 같이 패킷이 전달되도록 각각의 라우터의 포워딩 테이블 값을 설정한다면

이렇게 설정할 수 있다.
s3 라우터의 input 포트에는 항상 10.3 으로 시작하는 IP주소를 가진 호스트가 요청을 보내므로 10.3.*.* 로 설정할 수 있다.
ㄴ자 경로로 갈 때 항상 s2 라우터에 물린 10.2.* 위치의 호스트로 보내므로 목적지 조건은 10.2.*.*로 설정할 수 있다.
그리고 이때의 액션은 forward(3)으로 하면 항상 s1으로 가도록 설정할 수 있다.
이렇게 네트워크 전체의 동작을 프로그래밍해서 라우터에 주입할 수 있다.
이것이 OpenFlow가 지향하는 네트워크 프로그래머빌리티이다.
프로그램을 통해 패킷 단위의 프로세싱을 가능하게 한다.
(과거에는 active networking 이라는 이름의 연구 분야가 있었고, 이 OpenFlow에 기반을 두고 있었다.)
요즘은 더 일반화된 다양항 방식의 프로그래밍을 할 수 있다.
p4 (Programming Protocol-independant Packet Processor) 라는 프로그래밍 언어를 사용한다고 한다.
'CS > 컴퓨터 네트워크' 카테고리의 다른 글
| [컴퓨터 네트워크] 32. Network Layer (8) : control plane, 라우팅 프로토콜 개요 (0) | 2024.06.08 |
|---|---|
| [컴퓨터 네트워크] 31. Network Layer (7) : Middlebox (0) | 2024.06.07 |
| [컴퓨터 네트워크] 29. Network Layer (5) : IPv6 (0) | 2024.06.06 |
| [컴퓨터 네트워크] 28. Network Layer (4) : NAT (0) | 2024.06.06 |
| [컴퓨터 네트워크] 27. Network Layer (3) : IP (0) | 2024.06.05 |