트랜잭션은 일련의 읽기와 쓰기 동작으로 이루어진 하나의 실행 동작을 말한다.
트랜잭션은 여러 사용자가 같은 데이터에 동시에 접근할 때, 데이터의 일관성을 유지할 수 있도록 도와주며, 장애 복구에도 유용하게 사용된다. 이를 위해서 트랜잭션은 다음의 4가지 성질을 만족해야 한다.
ACID
1. atomicity (atomic)
트랜잭션을 구성하는 일련의 동작들은 모두 수행되거나 모두 수행되지 않아야 한다.
따라서 트랜잭션을 수행하는 일반 사용자는 트랜잭션 내 동작들이 일부만 수행되다가 장애가 발생했을 때도 그 영향에 대해 걱정할 필요가 없다.
2. Consistency
각각의 트랜잭션은 데이터베이스의 일관성을 유지해야 한다.
즉, 동시에 수행되지 않는 각각의 트랜잭션은 언제나 일관된 데이터를 보고 있어야 한다.
(수업 중에는 여러 병행된 요청들은 일관된 데이터를 보고 있어야 한다고 설명하심)
3. Isolation
사용자는 동시에 수행되고 있는 다른 트랜잭션을 고려하지 않고 트랜잭션의 수행 결과를 이해하고 예측할 수 있다.
즉, 다른 트랜잭션의 동작에 영향을 받지 않으므로, 이 시스템을 나 혼자 쓰고 있는 것과 같은 느낌을 주어야 한다.
4. Durability
DBMS의 트랜잭션이 성공적으로 수행되었음을 유저가 인지했을 때, 비록 그 수행 결과가 디스크에 반영되기 전에 장애가 발생하더라도 그 효과가 남아있어야 한다. (장애 복구와 관련된 내용같음. 수업 중에는 한번 디스크에 썼다면 그 내용이 계속 유지된다는 느낌으로 설명하심)
그리고 위에서 말한 '트랜잭션이 성공적으로 수행되었다' 는 효과를 주는 것이 DBMS에서의 commit 이다.
이와 관련하여 한 가지 예시를 살펴보자.
미국에 있는 유튜브 DB 서버가 있다고 해보자.
유튜브 같은 글로벌 기업들은 각 나라마다 그 나라에 가까운 별도의 서버를 복제해서 만들어둔다. (CDN과 같이)
이때 복제가 제대로 되지 않으면 두 서버에 일관된 데이터가 존재하지 않는 문제가 발생할 수 있다.
꼭 복제가 제대로 안되는 문제가 아니더라도 두 서버 사이에 거리가 있으니 반영하는데에도 어느 정도 시차는 존재할 수 밖에 없다.
만약 이 상황에서 한국과 미국에서 같은 데이터를 요청하는 트랜잭션이 동시에 발생하면 두 트랜잭션은 일관되지 않은 데이터를 볼 수도 있다.
그래도 유튜브와 같은 컨텐츠 서비스라면 조금의 시차가 있더라도 큰 문제가 되지는 않는다.
하지만 만약 이 문제가 은행에서 발생한다면 어떨까? 대형사고가 발생할 수 있는, 중요한 문제가 된다.
그래서 이와 관련하여 CAP 라는 개념이 등장하기도 했다.
CAP는 Consistency / Availability / Partition tolerance 의 줄임말로,
분산 시스템에서 데이터 일관성, 가용성, 분할 저항성을 모두 만족하는 것이 불가능하다는 법칙을 말한다.
예를 들면 Partition tolerent 는 분할된 상황에서 둘 사이의 통신이 끊겼을 때, C와 A를 모두 만족할 수 없다는 것을 의미한다.
사실 직관적으로는 통신이 끊긴 상태에서 C와 A를 모두 만족할 수 없다는 것은 당연하다.
만약 단선된 상황에서 A를 유지하려면 그냥 일관성을 무시하고, 각자 갖고 있는 데이터를 그대로 보내주면 된다.
반면 C를 유지하고자 한다면, 서비스를 중단하고 데이터의 일관성을 맞추는 작업을 해야 할 것이다.
은행의 경우에는 C를 중시할 것이므로, 만약 복제를 하려고 한다면 일단 서비스를 중지시키고 복제를 할 것이다.
이때는 A가 잠시 떨어질 것이다.
반면 SNS 서비스라면 A를 높이고 C를 낮추는 것이 더 바람직할 것이다. 서비스가 일단 계속 되어야 사람들이 계속 사용하고 돈을 벌 수 있을 것이기 때문이다.
직렬 가능성
트랜잭션 내에서 실행하는 읽기와 쓰기, 커밋, 롤백 연산의 나열을 가리켜 '스케줄' 이라고 한다.

위 그림은 T1, T2 트랜잭션의 read, write 연산 스케줄을 보여준다.
위에서부터 아래로 시간순으로 진행된 연산을 보여주며, T1의 연산과 T2의 연산이 번갈아가면서 진행된 것을 볼 수 있다.
이렇게 트랜잭션 내 연산이 서로 뒤섞이는 것을 '인터리브' 라고 표현한다.
위 스케줄에서는 커밋과 롤백 연산을 표시하지 않았다.
실행 완료된 트랜잭션들의 집합에 대한 스케줄이 '직렬 가능하다'면 이는 각각의 스케줄이 인터리브 되지 않고 실행되었을 때와 같은 결과를 가지는 것을 말한다.
즉, 여러 트랜잭션이 동시에 들어올 때, 여러 트랜잭션을 동시에 실행하도 마치 따로따로 실행한 것과 같이 서로에게 영향이 없는 것을 가리켜 직렬 가능하다고 말한다.

예를 들면 왼쪽과 같이 실행되는 트랜잭션은 이미 그 자체로 직렬가능하다.
서로 영향을 전혀 주지 않기 때문이다.
오른쪽과 같이 실행되는 경우에는 비직렬 상태이지만 (non-serial)
만약 빨간색 공통 영역에서 실행하는 액션들이 서로에게 영향을 주지 않는다면 직렬가능하다. (serializable)

예를 들어 위와 같은 스케줄이 있다면, 이 스케줄은 직렬 가능하다.
T1 트랜잭션이 시작된 이후 T2 트랜잭션이 시작되었으므로, 인터리브 되지 않은 상황을 생각하면
T1 <R(A) - W(A) - R(B) - W(B) - Commit> - T2 <R(A) - W(A) - R(B) - W(B) - Commit> 순으로 동작하기를 기대할 것이다.
그런데 A, B 라는 데이터 각각의 관점에서 보면, 위 그림 속 스케줄은 T1에서 RW을 수행한 이후에 T2에서 RW를 수행하고 있으므로 인터리브 되지 않은 상황에서 기대하는 것과 동일한 결과를 내보낸다. 따라서 이 스케줄은 직렬가능하다.
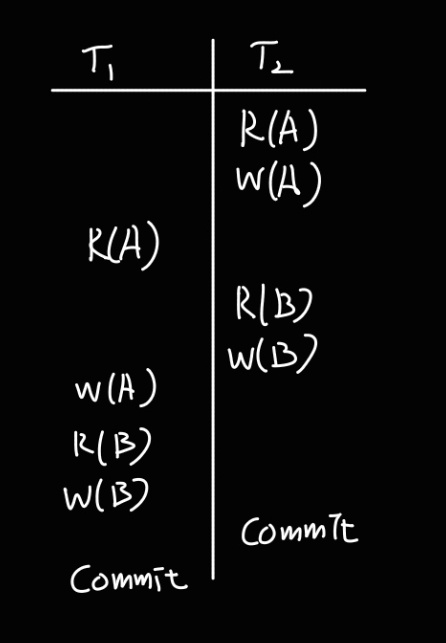
이 예시 역시 직렬가능한 스케줄을 나타낸다.
T2에서 먼저 트랜잭션이 시작되었으므로 A, B 데이터에 대한 연산이 T2에서 먼저 수행되기만 하면 직렬가능하다.
충돌 상황
어떤 데이터 X에 대해 서로 다른 트랜잭션에서 액션을 수행하기 위해 접근할 수 있다.
이때 가능한 경우의 수는 총 4가지로
Read-Read / Read-Write / Write-Read / Write-Write 상황이 발생할 수 있다.
이때 Read-Read 는 아무런 문제가 발생하지 않는다.
두 트랜잭션 모두 같은 데이터에 대해 읽기만을 수행하므로 같은 값을 바라봐서 일관성이 유지되기 때문이다.
하지만 나머지 3가지 경우에 대해서는 문제가 발생할 수 있다.
충돌 상황의 예시는 다음과 같은 경우가 있다.

T2는 디스크에서 x 값을 읽어 100을 더한 뒤 저장하고, T1은 디스크에서 x 값을 읽어 10을 뺀 뒤 저장한다.
T2가 먼저 실행되고나서, 그 다음 T1이 실행되므로 두 트랜잭션이 직렬 가능하다면 T2는 200을 디스크에 쓰고, T1은 190을 디스크에 써야 한다.
그런데 T2가 값을 읽은 뒤, 계산하는 동안 T1이 디스크에 접근해서 T2와 동일한 100 이라는 값을 읽고 연산을 진행하고 있다.
그리고 T2가 연산한 값을 쓰고나서 T1이 100에 대해 연산한 값을 써서 90이라는 값이 저장되고 말았다.
T1 입장에서는 T2의 존재를 알 수 없으니 올바르게 동작한 것이지만, T2 입장에서는 분명 100을 읽고 100을 더해서 저장했는데 실제로 90이 남아있는 이상한 일이 발생하고 만다.
(이렇게 다른 트랜잭션이 읽은 값에 대해 쓰기를 진행해서 다른 트랜잭션이 읽은 값이 의미 없어진 것을 가리켜 팬텀 리드라고 한다.
추가로 다른 트랜잭션이 쓴 값에 대해 읽기를 진행해서 기존과 다른 값을 읽은 것을 dirty read 라고 한다.)

이번엔 T2에서 먼저 100을 더하고 T1에서 10을 빼는 과정은 동일하나, 마지막에 T1이 커밋하고나서 T2는 롤백을 했다고 해보자.
그러면 사실 T2가 실행한 동작은 없던 동작이 되어야 하므로 90이 쓰여야 하나, 190이 쓰이는 문제가 발생한다.
(수업중에는 커밋하고 롤백이 발생한 것으로 설명하셨다. 만약 롤백하고 커밋이 다음에 일어나면 어떻게 될까?)
책애서는 이런 경우, 이미 commit 된 동작은 되돌릴 수 없기 때문에 '복구 불가능한 스케줄' 이라고 표현한다.
어떤 스케줄이 복구 가능하려면, 내가 읽어서 사용한 값과 관련된 트랜잭션이 모두 commit 될 때까지 기다렸다가 commit 해야 한다.

마지막으로 위와 같은 예시를 보자.
T2는 x, y, z의 값을 읽어 세 값을 더한 뒤 S에 저장하는 연산을 수행하고
T1은 x의 값을 10 감소시키고, z의 값을 10 증가시키는 연산을 수행하고 있다.
그런데 만약 이 연산이 직렬가능하다면 T2는 단독적으로 100 + 50 + 25 를 읽거나, 90 + 50 + 35를 읽어서 175를 저장해야만 한다.
(위 상황에서는 T2가 먼저 시작했으니 100 + 50 + 25를 읽어서 175를 저장하는 것이 올바를 것이라고 생각했는데, 수업중에 교수님은 90 + 50 + 35를 읽어서 175를 내는 것이 맞다고 하셨다. T2가 먼저 시작했는데 왜일까?)
하지만 최종적으로는 185를 읽어서 저장하였는데, 이 상황에서 한번도 x, y, z 값이 동시에 100, 50, 35 가 된 적이 없음에도 185를 저장하는 문제가 발생하였다.
직렬 가능성 판별
그렇다면 이렇게 스케줄에서 여러 액션이 뒤섞여 있을 때, 주어진 스케줄이 직렬 가능한지 어떻게 판단할 수 있을까?
이는 각각의 트랜잭션 사이에 간선을 그었을 때 사이클이 나오는지 확인하면 직렬 가능성을 판단할 수 있다.
먼저 트랜잭션 Tᵢ 와 Tⱼ 가 모두 Read 연산을 하는 게 아니라면, 충돌이 발생할 가능성이 있다.
따라서 두 트랜잭션의 액션 사이의 선후를 따져 Tᵢ → Tⱼ 와 같이 간선을 긋는다.
Read - Read를 제외한 모든 연산 관계에 대해 간선을 그었을 때, 트랜잭션을 노드로 하는 그래프가 그려질 텐데, 이 그래프에 사이클이 없다면 직렬 가능하다.

예를 들어 위와 같은 스케줄이 있다고 해볼 때, 이 스케줄의 직렬 가능성을 판단해보자.

먼저 시간순으로 살펴볼 때, read - read 연산은 충돌이 발생하지 않으므로 직렬가능성을 판단할 때 고려하지 않는다.

다음으로 시간순을 따라가면 T2 read → T3write 가 나온다. 이에 대해 T2 → T3 의 간선을 만든다.
같은 방법으로 다음 시간대에는 T3 → T1 간선이 만들어진다.
이를 조합하면 T2 → T3 → T1 이 나오며, 이는 사이클을 형성하지 않으므로 이 스케줄은 직렬가능하다.

이 예시에서는 같은 방법으로 트랜잭션을 나열하면 T3 → T1 → T2 → T3 으로 사이클이 발생한다.
따라서 이 스케줄은 직렬 가능하지 않다.
이렇게 지금까지 트랜잭션의 특성과 직렬 가능성에 대해 정리하였다.
다음 글에서는 직렬 가능하지 않은 트랜잭션에 대해 어떻게 동시에 들어오는 트랜잭션 요청을 처리할 수 있을지 여러가지 해결책을 정리해본다.
'CS > 기초데이터베이스' 카테고리의 다른 글
| [데이터베이스] 26. 정규화 (1NF ~ 5NF) (0) | 2024.12.08 |
|---|---|
| [데이터베이스] 25. 동시성 제어 & 장애 복구 (0) | 2024.12.07 |
| [데이터베이스] 23. Postgresql Explain (0) | 2024.12.05 |
| [데이터베이스] 22. 외부 정렬 (0) | 2024.11.29 |
| [데이터베이스] 21. 질의 수행 (Query Plan) (2) | 2024.11.29 |